In this post I will talk about Implementing Linearizability at Large Scale and Low Latency SOSP 2015 paper.
Linearizability, the strongest form of consistency, can be very important in large scale data storage systems, although many such systems either do not implement linearizability or do not fully expose serializable operation to the clients. The later type of systems can maintain linearizability for internal operations that occur between servers, but do not provide the same consistency to the clients.
The authors of the paper provide a linearizability framework, called RIFL, suitable for use in existing non-linearizable RPC based distributed system. The framework allows to convert existing RPC into linearizable ones in just a few lines of code with minimal impact on the overall performance. The paper only discusses RPC-based systems, since according to the paper, linearizability requires a request-response protocol to operate. I think it may be possible to sue RIFL-like system for message passing approaches as long as receiving each message eventually produces an ack to the sender.
Linearizability
In order to better understand RIFL and how it is beneficial in the data-store system, we need to talk about Linearizability. According to the paper, Linearizable operations appear to happen instantaneously and only once at same point in the execution of a system. It is important to understand that in a real system an operation can take some time to execute and can potential fail midway through its execution. Linearizable system must make it appear to all its clients as if the operation happened right away. The ability to execute operations only once is another important point, as many existing systems retry execution of operation upon failure. Authors say such operations follow at-least-once semantics, whereas linearizable operations have exactly-once semantics. In order to achieve certain consistency guarantees, many existing systems use idempotent operations which produce the same outcome regardless of how many times such operations have been executed. Authors show an example in which running such operation more than once can break the linearizability after a certain failure.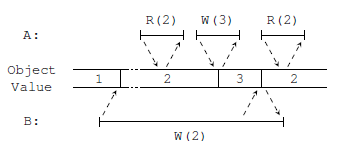
Example of at-least-once semantic breaking linearizability.
In this case we have two clients interacting with a single server. Client B writes 2 to the server but it crashes before the server has a chance to respond. When client A reads the data, it will get the value written by B. Later client A can write a different value, while client B is recovering from the failure. Once client B as back up, it does not know that its previous operation has succeeded, so it retries it and overwrites the later value written by A. Authors do not mention how likely such example to occur in practice, but given a large scale of the system with thousands or even millions clients, it will be unwise to discount the possibility of such failure. Nothing is mentioned whether any of the existing data-store systems address the issue.
RIFL
RIFL framework allows the conversion of the system relaying on the at-least-once RPC operations into linearizable exactly-once operations. The main idea behind RIFL is storing the results of the RPC execution, so that in case of a retry of an RPC call the system could have used already known result without having to re-run the procedure. The results of the RPC invocation are stored on the completion records, and each such record is associated with each unique RPC. This ensures the exactly-once operation of the RPCs in the system, but also opens up a number of problems that had to be solved.

High level representation of RIFL logic
In order to operate properly, the system must be able to detect retry calls. In order to make such detection easy, each RPC is assigned a 128-bit ID number consisting of a 64-bit client ID and 64-bit sequence at such client. If an operation is to be retried by the client, it must use the same ID. Before execution of an RPC, the server will check if it is aware of a completion record for such RPC and if it does not exist, RPC continues, but if a completion record is present then the server will return the results stored in the completion record instead of running an RPC.
Migrating completion records is essential in the event of a failure, as the system relies on the presence of such records to make a decision on whether an RPC needs to run. From time to time, data can migrated from one server to another, especially in case of a server crash. The new server must have the completion records available to it after the migration, so each completion records is attached to one of the data-objects being modified by an RPC, so that moving the object will also move all the completion records for RPCs acting on the object. Unfortunately, authors do not explain in detail how the migration is made, as this part is probably left out to the underlying system. It is very likely that completion records also get replicated with the objects they belong to for durability reasons, although no mechanism for such replication is described as well, so it is worth to assume that the completion record replication is left out to the underlying system.
Overtime many completion records are going to be created for each object, increasing the storage requirements and the bandwidth used for replication and migration of objects. In order to improve resource utilization, a garbage collection mechanism for old completion records was devised. In RIFL a completion record can get removed from the system if a client acknowledges that it knows of a successful RPC execution and will not retry it in the future. Such acknowledgments are piggybacked to the new RPC requests and as a result incur minimal overhead. In case of a client failure, no acknowledgement will be sent to the server, causing certain completion records to persist. In order to deal with this problem, RIFL uses lease manager to grant leases to all the clients. In case a client lease is not renewed, all completion records for the client will be purged. It is not clear how a centralized lease system can impact the overall performance of a system implementing RIFL. A time synchronization between the client, lease manager and a server is used to reduce the need to communicate: the server will contact lease manager only when it estimates that the client lease will expire soon. This portion of a lease protocol raises some questions about the reliability of the lease sub-system. What is going to happen if time skew is greater than the server estimates for? If the server time is ahead of lease manager time, server will start issuing more check requests to the lease manager, but if it is lagging behind the lease manager time, than the server may think lease is still good while the client may have already been dead. I think the worst case scenario is that GC does not collect all dead completion records, which may not be of a big immediate problem, but may eventually lead to the excess memory consumption by the server applications.
Transactions with RIFL
Authors implemented a transaction system using RIFL for linearizability on top of RAMCloud, a distributed, in memory key-value datastore. A two-phase commit protocol similar to Sinfonia is used to implement transactions. In the first phase of the protocol, usually called a prepare phase, a set of read, write or delete commands is sent to servers and each server upon receiving prepare determines if it can proceed with the commit. If all servers can commit, then a second phase finalizes the transaction. RIFL makes crash recovery simpler compared to Sinfonia. Since each prepare operation is linearizable, retires of the prepare will not cause and adversary effects. Upon a more serious crash, recovery manager can learn if the results of the prepare operation without the knowledge of the original commit commands, and if all prepares have succeeded, it can finalize the transaction; in case of some prepare failures, transaction is simply aborted.
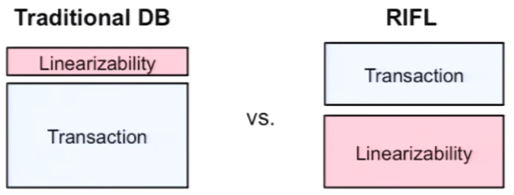
One important point authors make in the paper is about traditional way of implementing linearizability on datastores and how it differs from their implementation. In the existing system, linearizability is implemented on top of a transaction system and according to the authors this approach creates more cumbersome transaction mechanism. With RIFL, transactions were implemented on top of a linearizability layer, which authors claim is a better approach.
Evaluation
RIFL was implemented and evaluated in RAMCloud. Overall, authors claim only 5% reduction in latency for RIFL linearizable write RPCs compared to the original writes. No significant difference in throughout was observed when using RIFL.
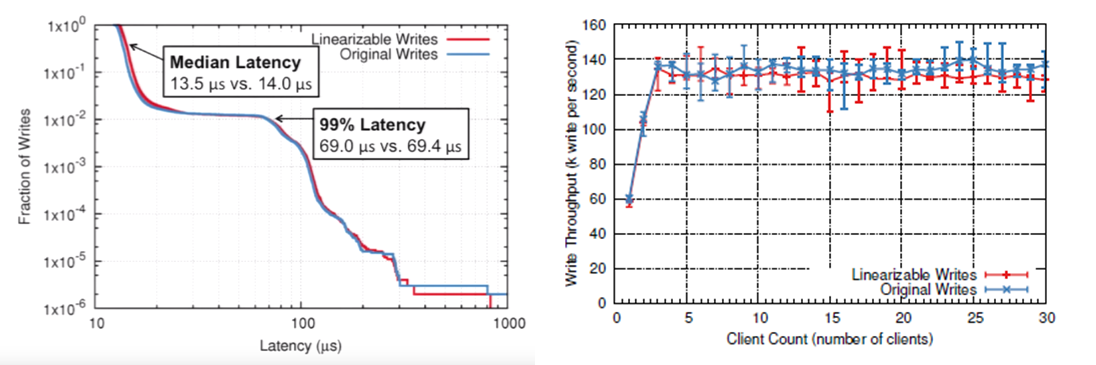
Added overhead of RIFL to the RAMCloud system. Left is latency, right is throughput.
Transaction performance was evaluated with TPC-C benchmark typically used for performance evaluation of Online Transaction Processing (OLTP) systems. RIFL RAMCloud was compared against H-store database. Both system are in-memory databases but they different significantly in their purpose and typical use cases. As a matter of fact, RIFL RAMCloud solution had to be specifically implemented for TPC-C benchmark. When comparing the two systems, authors found out that RAMCloud with RIFL significantly outperforms H-store in all tests. I am a bit skeptical about these results, at least without more knowledge about how RAMCloud was used to make TPC-C benchmark work with it and whether the implementation of RIFL & RAMCloud interface for TPC-C benchmark was specifically tailored for the tests performed by TPC-C. It may have been a good idea to compare the system against other transaction protocols implemented in RAMCloud, such as the ones based on consensus.
Overall Thoughts
When reading the paper I thought that the idea of caching the results of RPC calls is a very straightforward and simple and I am surprised it has not been exploited before. Yes, store such cache presents a few challenges, mainly in memory management of the overall system, as the cache size can grow large, but as shown in RIFL, these are not very big challenges and can be solved with simple protocols and existing tools, such as ZooKeeper. Authors claim that implementing transactions on top of linearizability layer is a better and faster approach. Transactions (mini-transactions?) implementation became easier with RIFL, but I am not sure the performance benefit is obvious. On my opinion performance comparison with H-store seems somewhat unfair.