In the 57th reading group meeting, we continued looking at byzantine fault tolerance. In particular, we looked at “XFT: Practical Fault Tolerance beyond Crashes” OSDI’16 paper.
Today’s summary & discussion will be short, as I am doing it way past my regular time. The paper talks about a fault tolerance model that is stronger than the crash fault tolerance (CFT) model of traditional state machine replication protocols, like Multi-Paxos and Raft, but slightly weaker than a full-blown byzantine fault tolerance (BFT). The authors propose cross fault tolerance (XFT), which is a relaxation of the BFT model for partly synchronous networks. In particular, the XFT model assumes that at least a majority of servers are both correct and can communicate synchronously. This deviates from classical BFT where the entire communication schedule can be byzantine. Naturally, authors claim that such a byzantine network scheduler is rather difficult to orchestrate in many environments and thus we do not need to account for it and gain some performance in return.
The paper then proposes XPaxos, a Paxos variant designed for XFT. I am not going in-depth on the XPaxos. Like many BFT-protocols, it relies on signed messages and involves more complicated communication patterns than CFT protocols. The two images below should give some hint on how XPaxos works.
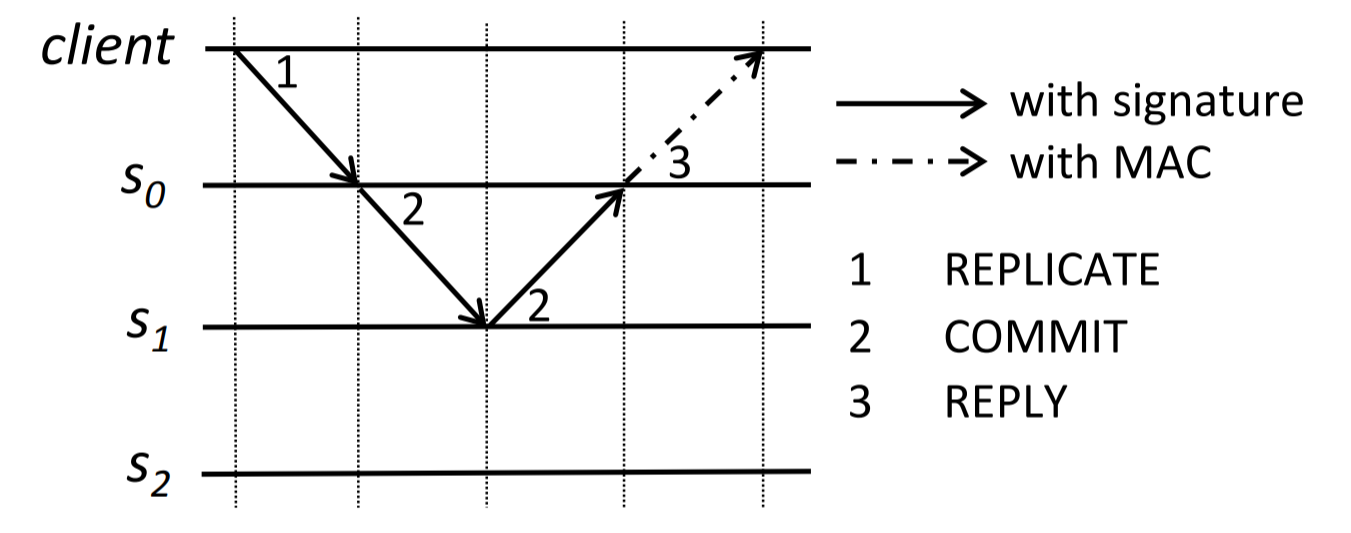
XPaxos has a special 3-node configuration that is efficient from a communication standpoint, and it seems like this configuration can compete with a 3-node Multi-Paxos.
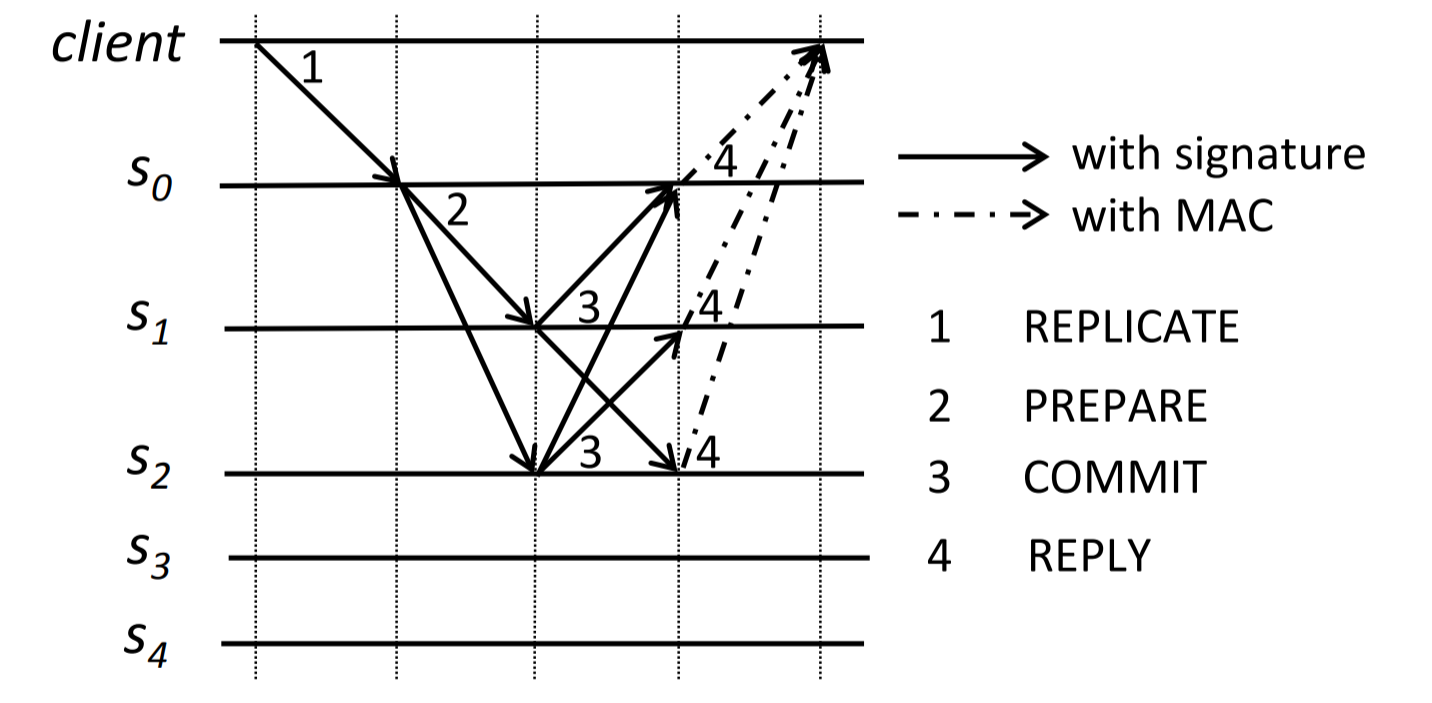
However, a more general XPaxos configuration is more complex communication-wise to be able to handle byzantine nodes. Obviously, this is a lot less efficient.
Another complication in XPaxos is a view change, but hopefully, in the happy case we do not need to change leaders/sync-groups too often so, the extra costs of this can be amortized over time.
Mohit Garg did an excellent presentation of the paper:
Discussion
1) Comparison with Protocol Aware Recovery. Recently we looked at the Protocol Aware Recovery paper that assumes a possibility of arbitrary corruption of data. Obviously, PAR considers a specific type of byzantine fault (such data corruption makes the node act out of spec by potentially sending bad data), while the XFT model is a lot more general. On the other side, PAR paper may be even cheaper to run and has no less efficient general cases. But we think the spirit of the problems is similar, as we need to have better ways to handle common failures that fall out of the traditional CFT model. The difference is doing a more general approach like XFT, or doing a piece-wise defined solution for each non-CFT fault type, like PAR.
2) On 3-way replication. It seems that the only practical and fast configuration of XPaxos is the one with 3 replicas. This may limit some applications. However, many systems do stick with 3-replica deployment. For example, Cockroach or Yugabyte. One consideration with using just 3 servers is planned maintenance. When a system needs to be updated in a rolling manner, one node at a time must be taken out of commission, living the system vulnerable. But of course, we can solve this problem with reconfiguration and/or temporary operation with a bigger but less efficient cluster.
3) Further reading. Mohit has worked on follow-up/extension to XFT.
We have also discussed a few examples of these out-of-spec/BFT problems in the wild. For instance, this one talks about data corruption in the Chubby lock service.