Our 74th paper was a foundational one — we looked at Viestamped Replication protocol through the lens of the “Viewstamped Replication Revisited” paper. Joran Dirk Greef presented the protocol along with bits of his engineering experience using the protocol in practice.
Viestamped Replication (VR) solves the problem of state machine replication in a crash fault tolerance setting with up to f nodes failing in the cluster of 2f+1 machines. In fact, the protocol (between its two versions, the original and revisited) is super similar to Raft and Multi-Paxos. Of course, the original VR paper was published before both of these other solutions. An important aspect in the narrative of the VR paper is that the basic protocol makes no assumptions about persisting any data to disk.
Replication
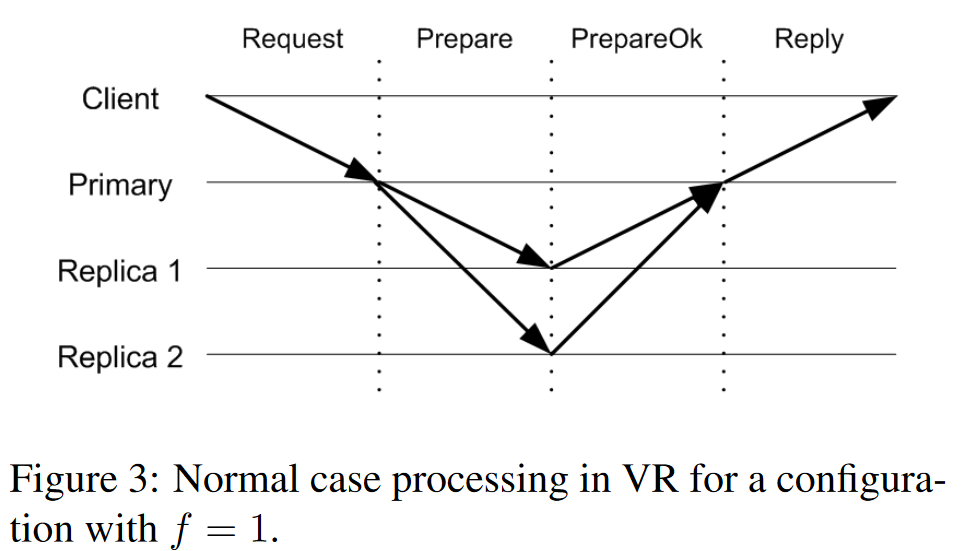
In the common case when replicating data, VR has a primary node that prescribes the operations and their order to the followers. The primary needs a majority quorum of followers to ack each operation to consider it committed. Once it reaches the quorum, the primary can tell the followers to commit as well. In VR, followers do not accept out-of-order commands and will not ack an operation without receiving its predecessor. With a few differences, this is how typical consensus-based replication works in both Raft in Multi-Paxos. For example, Multi-Paxos complicates things a bit by allowing out-of-order commits (but not execution to the state machine).
View Change and Replicas Recovery
As with everything in distributed systems, the interesting parts begin when things start to crumble and fail. Like other protocols, VR can mask follower crashes, so the real challenge is handling primary failures. The VR protocol orchestrates the primary failover with a view-change procedure. Here I will focus on the “revisited” version of the view-change.
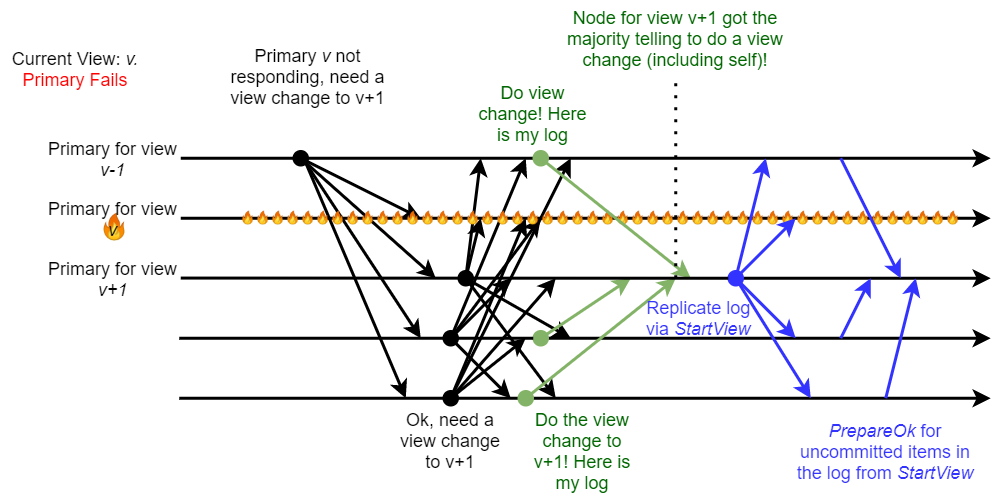
One interesting piece of the revisited view-change is its deterministic nature, as each view is assigned/computed to belong to a particular node. When a current primary in view v fails, the node for view v+1 will try to become a new primary. This promotion to primary can be started by any node suspecting the current primary’s demise. We do not need to have a node for view v+1 to directly observe the crash of primary for v, allowing for unreliable failure detectors.
So, any replica can start a view change if it detects a faulty primary. The replica will advance to the next view v+1 and start the view change by sending the StartViewChange message with the new view number to all the nodes. Each replica that receives the StartViewChange will compare the view to its own, and if its view is less than the one in the received StartViewChange message, it will also start the view change and send its own StartViewChange message to every replica. Also note, that two or more replicas may independently start sending the initial StartViewChange messages for the new view v+1 if they independently detect primary failure. The bottom line of this StartViewChange communication pattern is that now any replica that received at least f StartViewChange messages will know that the majority of the cluster is on board to advance with the view change.
So, after receiving f StartViewChange messages for the new view v+1 from other nodes, each replica sends a DoViewChange message to the primary for that new view v+1. The DoViewChange message contains the replica’s last known view v’ along with the log. The new primary must receive a majority (i.e., f+1) of DoViewChange messages. The new primary then selects the most up-to-date log (i.e., the one with the highest v’ or longest log if multiple DoViewChange messages have the same highest v’). This up-to-date log ensures the new primary can recover any operations that might have been majority-accepted or committed in previous views. Such “learning from the followers and recover” part of the view change procedure is somewhat similar to Multi-Paxos, as the new leader needs to recover any missing commands before proceeding with the new ones. The VR leader recovery only cares about the view and the length of the log because it does not allow out-of-order prepares/commits. In Multi-Paxos, with its out-of-order commitment approach, we kind of need to recover individual log entries instead of the log itself.
Anyway, after receiving enough (f+1) DoViewChange messages and learning the most up-to-date log, the new primary can start the new view by sending the StartView message containing the new view v+1 and the recovered log. The followers will treat any uncommitted entries in the recovered log as “prepares” and ack the primary. After all entries have been recovered, the protocol can transition into the regular mode and start replicating new operations.
There is a bit more stuff going on in the view change procedure. For example, VR ensures the idempotence of client requests. If some client request times out, the client can resend the operation to the cluster, and the new leader will either perform the operation if it has not been done before or return the outcome if the operation was successful at the old primary.
Another important part of the paper’s recovery and view change discussion involves practical optimizations. For example, recovering a crashed in-memory replica requires learning an entire log, which can be slow. The proposed solution involves asynchronously persisting log and checkpoint to disk to optimize the recovery process. Similarly, view change requires log exchange, which is not practical. An easy solution would involve sending a small log suffix instead since it is likely that the new primary is mostly up-to-date.
Discussion
1) Comparison With Other Protocols. I think the comparison topic is where we spent most of the discussion time. It is easy to draw parallels between Multi-Paxos and VR. Similarly, Raft and VR share many things in common, including the similarity of the original VR’s leader election to that of Raft.
One aspect of the discussion is whether Multi-Paxos, Raft, and VR are really the same algorithms with slightly different “default” implementations. We can make an argument that all these protocols are the same thing. They operate in two phases (the leader election and replication), require quorum intersection between the phases, and have the leader commit operation first before the followers. The differences are how they elect a leader to ensure that the committed or majority-accepted operations from the prior leader do not get lost. Multi-Paxos and VR revisited recover the leader, while Raft ensures the new leader is up to date to eliminate the need for recovery.
2) Optimizations. Academia and Industry have churned out quite a substantial number of optimization for Multi-Paxos and Raft. There has even been a study on whether the optimizations are interchangeable across protocols (the short answer is yes). But that study did not include VR. Interestingly, Joran mentioned that they applied Protocol-Aware-Recovery to VR, and (if I am not mistaken) they also used flexible quorums. Of course, I am not surprised here, given how similar these solutions are.
3) In-memory Protocol. Joran stressed the importance of in-memory protocol description to engineers. In their systems, the in-memory consensus allows reducing the reliance on fault-tolerance/reliability of the storage subsystem. It appears that VR is the only major SMR protocol specified without the need for a durable infallible disk. And while people in academia do a lot of in-memory consensuses (including Multi-Paxos and Raft), the aspects of what is needed to make these systems work without the disk are not clearly described.
The VR paper briefly describes the problem that the lack of durable log introduces. The issue is that a node can forget its entire state. So, it can accept some value, create a majority and then reboot. Upon rebooting, if the node is allowed to participate right away, we no longer have the forgotten value in the majority quorum. Similarly, a node can vote on something in one view, reboot and forget and then potentially revote in a lesser view by some slow old primary.
To avoid these problems, the node needs to recover before it can participate. At least a partial recovery is needed to avoid the double voting problem — the node needs to learn the current view before accepting new operations. At the same time, such a partially recovered node must still appear “crashed” for any older operations until it has fully recovered.