Quick Summary
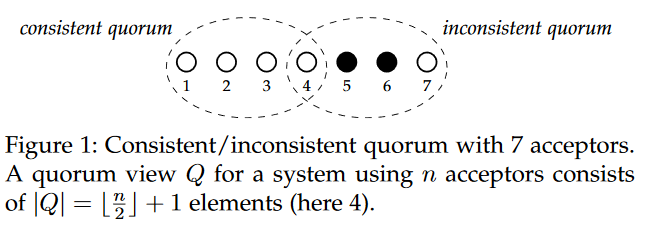
In the last reading group discussion, we talked about RMWPaxos. The paper argues that under some circumstances, log-based replication schemes and replicated state machines (RSMs), like Multi-Paxos, are a waste of resources. For example, when the state is small, it may be more efficient to just manage the state directly instead of managing a log of state-mutating operations. To that order, RMWPaxos foregoes the log and instead implements a state machine as a single atomic register. The basic protocol implements a write-once distributed register and resembles Paxos – it has two phases to elect a leader and prepare the value. There are some differences too. For example, the leader’s ballot is given by acceptors in phase-1, essentially meaning that a proposer always gets the majority of replies, as long as the majority of acceptors are up. The protocol then makes use of consistent quorums (see image below), and if the entire majority quorum has the same round number, the leader can proceed to phase-2 and play out regular Paxos (recover value if needed, or write a new one if not). However, if the phase-1 quorum is inconsistent, meaning that some acceptors have returned different round numbers, the protocol default back to running a regular Paxos Phase-1 by picking a round number higher than any seen in the quorum. The basic protocol is augmented to allow a register to be rewritable (after all, if all we care about is a write-once register, we can simply use basic synod Paxos). Anther augmentation deals with preventing the same operation to be double-written in the dueling leader scenarios. Here authors make some strong assumptions about the network and expect ordered point-to-point message delivery.
Discussion
(1) We have spent quite some time discussing the basic write-once protocol, as it seems more complicated than Paxos (and default to Paxos under inconsistent phase-1 quorum). It appears that when there is a need to recover some partly written value, a new proposer does so in 3 phases instead of two: phase-1, phase-1 classical Paxos, and phase-2
(2) On the usefulness of such protocol. The authors claim it is a big overhead to manage the log, but in our discussion, we did not fully buy that. The compelling point is that when the size of an operation is large, it becomes cheaper to manage the register than a log since the log will occupy a lot more space compared to the state machine. In this argument, an entire state machine fits in a register. The authors claim that there is no need to maintain separate learner nodes as each acceptor always has a copy of a register and that the entire RSM can be “learned” with just one read. The paper gives an example of a KV-store that can use different registers for different keys. One issue we discussed was that the keys are managed by totally separate state machines, meaning that having complex operations that touch multiple keys require a distributed transaction protocol.
(3) With regard to related works, our consensus was that there are some similar protocols proposed earlier that are not discussed or compared against. One example is CASPaxos/gryadka. Another one is CPaxos(Bolt-On Global Consistency for the Cloud), and both of these have earlier precursors, such as Disk Paxos and Active Disk Paxos.
(4) More about assumptions in the basic protocol. We discussed the possibility of duplicate messages causing the repeat of phase-2 in the round since it is possible for a proposer to go into phase-2 with an acceptor-assigned round/ballot. In that case, a bizarre duplication of phase-1 acks, may cause an acceptor to also run phase-2 twice. Which is ok if the value at the proposer does not change. This scenario is a bit of a stretch, but it was fun looking for ways to possibly defeat the protocol.
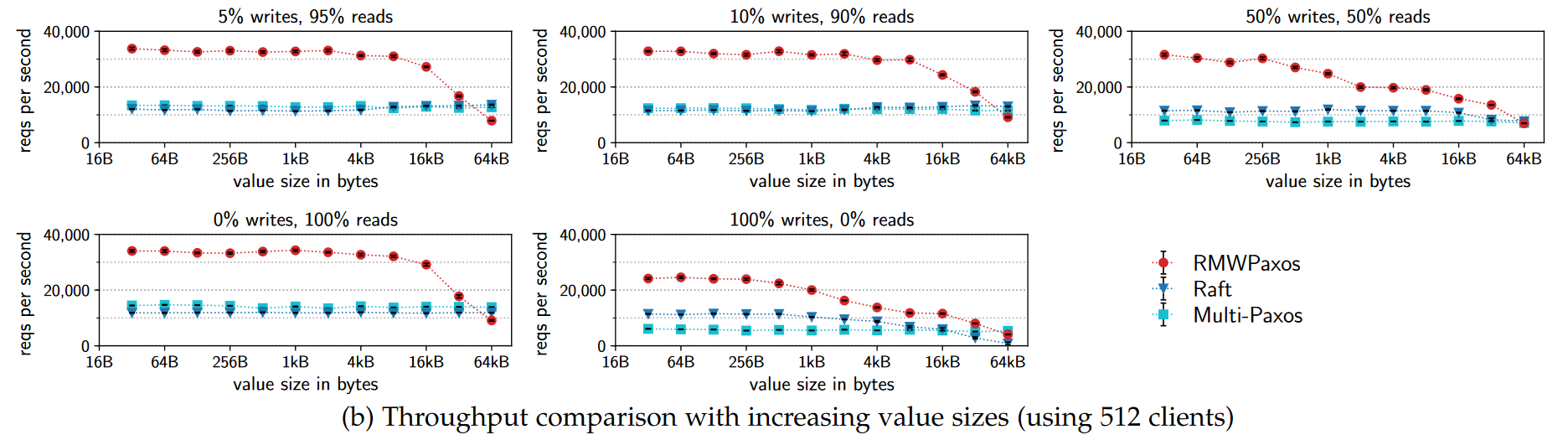
(5) Evaluation shows good results, with RMWPaxos outperforming Multi-Paxos two-fold in some cases. This is impressive, but not unexpected, given that RMWPaxos used multiple instances for different keys vs one instance of Multi-Paxos for all keys. In the discussion, we believe that this is a better illustration of why sharding/partitioning/multi-leader approach helps with performance and not so much the pure benefit of having a register. The being said, RMWPaxos should be very good for such fine-parallelism in tasks that allow it.
Please join the reading group’s slack channel for more discussion, paper information, and presentation times.