We covered yet another state machine replication (SMR) paper in our reading group: “Rabia: Simplifying State-Machine Replication Through Randomization” by Haochen Pan, Jesse Tuglu, Neo Zhou, Tianshu Wang, Yicheng Shen, Xiong Zheng, Joseph Tassarotti, Lewis Tseng, Roberto Palmieri. This paper appeared at SOSP’21.
A traditional SMR approach, based on Raft or Multi-Paxos protocols, involves a stable leader to order operations and drive the replication to the remaining nodes in the cluster. Rabia is very different, as it uses a clever combination of determinism to independently order requests at all nodes and a binary consensus protocol to check whether replicas agree on the next request to commit in the system.
Rabia assumes a standard crash fault tolerance (CFT) model, with up to f node failures in a 2f+1 cluster. Each node maintains a log of requests, and the requests execute in the log’s order. The log may contain a NO-OP instead of a request.
When a client sends a request to some node, the node will first retransmit this request to other nodes in the cluster. Upon receiving the request, a node puts it in a min priority queue of pending requests. Rabia uses this priority queue (PQ) to independently and deterministically order pending requests at each node, such that the oldest request is at the head of the queue. The idea is that if all nodes have received the same set of requests, they will have identical PQs.
At some later point in time, the second phase of Rabia begins — the authors call it Weak-MVC (Weak Multi-Valued Consensus). Weak-MVC itself is broken down into two stages: Propose Stage and Randomized Consensus Stage. In the propose stage, nodes exchange the request at the head of PQ along with the log’s next sequence number seq. This stage allows the nodes to see the state of the cluster and prep for the binary consensus. If a node sees the majority of a cluster proposing the same request in the same sequence number, then the node sets its state to 1. Otherwise, the node assumes a state of 0.
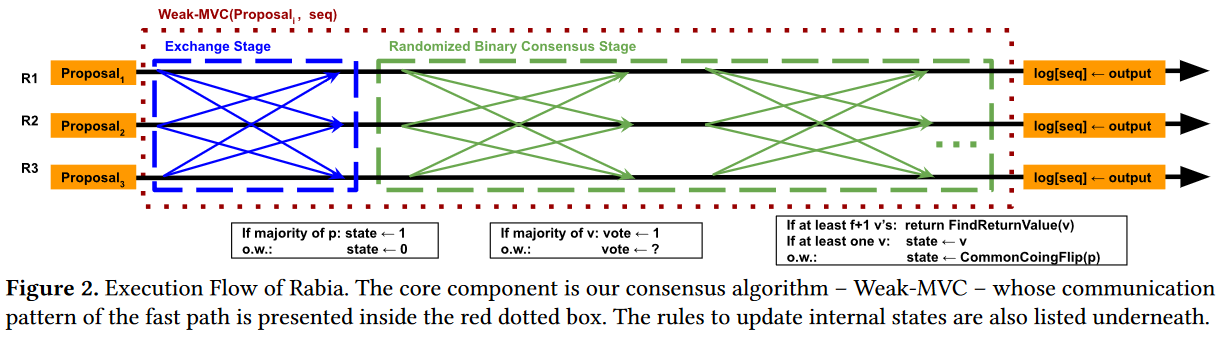
At this point, the binary consensus begins to essentially certify one of the two options. The first option is that a majority of nodes want to put the same request in the same sequence number (i.e., the state of 1). The second option is to certify that there is no such common request in the majority(state of 0). For binary consensus, Rabia uses a modified Ben-Or algorithm. Ben-Or consists of two rounds that may repeat multiple times.
In round-1, nodes exchange their state and compute a vote to be either 0 or 1. The vote corresponds to the majority of state values received, so if a node received enough messages to indicate that the majority of nodes are in state 1, then the node will take on the vote value of 1. Similarly, if a majority has state 0, then the node will vote 0. If no majority is reached for any state, the vote is nil.
Round-2 of Ben-Or exchanges votes between nodes. If the majority of nodes agree on the same non-nil vote, the protocol can terminate. Termination means that system has agreed to certify the request from the proposal if the consensus value is 1 or to create NO-OP if a value is 0.
In an ideal situation, all participating nodes will have the same request at the head of their PQs when the propose phase starts. This means that nodes will have the same state at the end of the propose phase, allowing the binary consensus to certify the proposed request at its sequence number in just one round trip (Round-1 + Round-2 of Ben-Or). So the request distribution + proposal + Ben-Or consensus under such an ideal case only takes 4 message exchanges or 2 RTTs. It is way longer than Multi-Paxos’ ideal case of 1 RTT between the leader and the followers, but Rabia avoids having a single leader.
A less ideal situation arises when no majority quorum has the same request at the head of PQ when the proposal starts. Such a case, for example, may happen when the proposal starts before the request has had a chance to replicate from the receiving node to the rest of the cluster. In this case, binary consensus may reach the agreement on state 0 to not certify any operation in that particular sequence number, essentially producing a NO-OP. The authors argue that this NO-OP is a good thing, as it gives enough time for the inflight requests to reach all the nodes in the cluster, get ordered in their respected PQs. As a result, the system will propose the same request in the next sequence number after the NO-OP. Both of these situations constitute a fast path for Ben-Or, as it terminates in just one iteration (of course the latter situation does not commit a request, at least not until the retry with higher sequence number).
Now, it is worth pointing out that the fast path of one RTT for binary consensus is not always possible, especially in the light of failures. If too many nodes have a nil vote, the protocol will not have enough votes agreeing for either state (1 – certify the request, 0 – create a NO-OP), and the Ben-Or process must repeat. In fact, the Ben-Or protocol can repeat voting many times with some random coin flips in between the iterations to “jolt” the cluster into a decision. For more information on Ben-Or, Murat’s blog provides ample details. This jolt is the randomized consensus part. The authors, however, replaced the random coin flip at each node with a random, but deterministic coin flip so that each node has the same coin flip value for each iteration. Moreover, the coin flip is only needed at the node if there is no vote received from other nodes in round-1 of Ben-Or, otherwise, the node can assume the state of the vote it received. The whole process can repeat multiple times, so it may not be very fast to terminate.
The paper provides more details on the protocol. Additionally, the authors have proved the safety and liveness of the protocol using Coq and Ivy.
The big question is whether we need this more complicated protocol if solutions like Multi-Paxos or Raft work well. The paper argues that Raft and Paxos get more complicated when the leader fails, requiring the leader election, which does not happen in Rabia. Moreover, Paxos/Raft-family solutions also require too many additional things to be bolted on, such as log pruning/compaction, reconfigurations, etc. The argument for Rabia is that all these extra components are easier to implement in Rabia.
Quite frankly, I have issues with these claims, and the paper does not really go deep enough into these topics to convince. For example, one argument is that leader election is complicated and takes time. Surely, not having a leader is good to avoid the leader election and performance penalty associated with it. But this does not come for free in Rabia. The entire protocol has more messages and rounds in the common case than Multi-Paxos or Raft, so it kind of shifts the complexity and cost of having a leader election once in a blue moon to having more code and more communication in the common case. I am not sure it is a good tradeoff. The performance claim of slow leader elections in Paxos/Raft is also shaky — failures in Rabia can derail the protocol of the fast path. I am not sure whether the impact of operating under failures is comparable with leader-election overheads upon leader failures, and I hope Rabia may have a point here, but the paper provides no evaluation for any kind of failure cases.
And speaking of evaluations, this was the biggest disappointment for me. The authors claim Rabia compares in performance to Multi-Paxos and EPaxos in 3 and 5 nodes clusters, with 3-nodes in the same availability zones allowing Rabia to outperform EPaxos. In fact, the figure below shows that Rabia beats Multi-Paxos all the time.
But there are a ton of assumptions and tweaking going on to get these results. For example, Rabia needs to have enough time to replicate client requests before starting the propose phase to have a good chance for completing on the fast path. So the testing is done with two types of batching to give the delay needed. The figure mentions the client batching. However, there is also a much more extensive server-side batching which is mentioned only in the text. Of course, there is nothing wrong with batching, and it is widely used in systems. For all the fairness, the paper provides a table with no batching results, where Multi-Paxos outperforms Rabia fivefold.
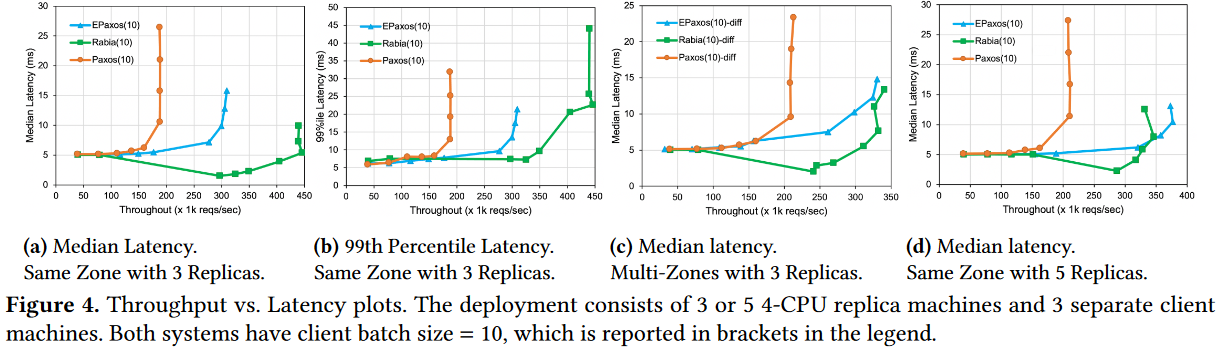
The biggest issue is the lack of testing under less-favorable conditions. No evaluation/testing under failures. No testing when the network is degraded and does not operate on the timing conditions expected by the protocol. These issues impact real performance and may create reliability issues. For example, a network degradation may cause Rabia to not use a fast path and consume more resources, reducing its maximum processing capacity. Such a scenario can act as a powerful trigger for a metastable failure.
As usual, we had a nice presentation of the paper in the reading group. Karolis Petrauskas described the paper in great detail:
Discussion.
1) Evaluation. I have already talked about evaluation concerns, and this was one of the discussion topics I brought up during the meeting.
2) Use of Ben-Or. Ben-Or is an elegant protocol to reach binary consensus, which is not usually useful for solving state machine replication. Traditionally, Multi-Paxos or Raft agree on a value/command and its sequence number, so they need a bit more than just a yes/no agreement. However, Rabia transforms the problem into a series of such yes/no agreements by removing replication and ordering from consensus and doing it apriori. With deterministic timestamp ordering of requests, Rabia just needs to wait for the operation to exist on all/most nodes and agree to commit it at the next sequence number. So the consensus is no longer reached on a value and order, but on whether to commit some command and some sequence number.
3) Practicality. The evaluation suggests that the approach can outperform Multi-Paxos and EPaxos, but whether it is practical remains to be seen. For one, it is important to see how the solution behaves under less ideal conditions. Second, it is also important to see how efficient it is in terms of resource consumption. EPaxos is not efficient despite being fast. The additional message exchanges over Multi-Paxos, Raft, and even EPaxos may cost Rabia on the efficiency side.
4) Algorithms. The paper provides some nice algorithms the illustrate how the protocol works. However, some of the conditions are not necessarily confusing. In the same algorithm, the authors use f+1, n-f, and floor(n/2)+1 to designate the majority in an n=2f+1 cluster. Please proofread your algorithms — a bit of consistency can improve readability a lot!