In the 75th reading group session, we discussed the transaction locality and dynamic data partitioning through the eyes of a recent OSDI’21 paper – “Don’t Look Back, Look into the Future: Prescient Data Partitioning and Migration for Deterministic Database Systems.”
This interesting paper solves the transaction locality problem in distributed, sharded deterministic databases. The deterministic databases pre-order transactions so that they can execute without as much coordination after the pre-ordering step. Now, this does not mean that every transaction can run locally. Indeed, if a transaction needs to touch data across multiple partitions or shards, then there is a need to reach out across partitions, which introduces delays. A natural way to solve the problem is to migrate the data based on its access patterns to minimize the number of such cross-partition transactions.
Such dynamic data migration is pretty much the solution in Hermes, the system presented in the paper. The thing is that the “group the data together” approach is not new. The authors cite several papers, such as Clay that do very similar stuff. Now, the biggest difference between Hermes and other approaches is the decision-making process involved in figuring out how and where the data needs to go. Traditionally, dynamic re-partitioning solutions rely on the historical data from the workload. These approaches work great when the workload is decently stable. However, workloads that abruptly change their access patterns present a problem — the system based on historical observation of access locality is reactive and needs time to adjust to the new workload. So, naturally, to tolerate the rapidly changing workload locality characteristics, we need a proactive system that can predict these locality changes and make necessary changes ahead of time. It would be nice to have an oracle that can see into the future. Well, Hermes kind of does this. See, the system requires a batched database, and before executing each batch, it can look at the access patterns within the batch and adjust accordingly.
Hermes looks at the patterns of transactions to be executed shortly, figures out how many transactions will require cross-partition coordination, and then makes data movements to minimize that number. For example, if some transaction type accesses two objects frequently together, Hermes will move one of these objects, incurring one cross-partition data transfer. If this happens, the transaction itself becomes partition-local, incurring no cross-partition data transfers.
In addition to moving and repartitioning the data around, Hermes also moves the transactions. The movement of compute tasks, again, is not new and makes a ton of sense. If a transaction originating in partition P1 needs some objects A & B located in some partition P2, then it makes a lot of sense to move a relatively small transaction to where the data is.
Unfortunately, the combination of dynamic re-partitioning and transaction movements leads to some unintended consequences over the long run. Consider a batch where objects A & B were used frequently together. The system moves them to one partition for speed. In the next batch, we may have objects B & C used together, so C moves to the same partition as B, again for speed. Now we have colocated objects A, B, and C. If this continues for very long, the system will consolidate more and more data in one place. This consolidation is not ideal for load balancing, so Hermes has to account for this and prevent data from gradually drifting closer together. It does so by “de-optimizing” for locality and allowing more distributed transactions in exchange for a more even load in each batch.
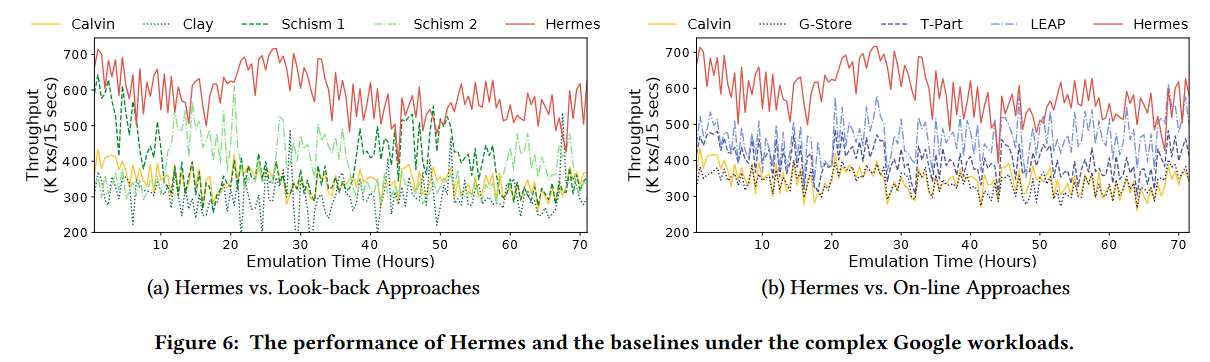
As far as performance, Hermes delivers when it comes to the workloads with frequent changes in locality:
As always, the presentation video from the reading group:
Discussion
1) Wide Area Networks. Hermes takes advantage of locality in a data center setting. It groups objects used together to allow local transactions as opposed to distributed ones. However, it may not work in a geo-distributed environment. The problem is that Hermes only solves one type of locality puzzle. It accounts for the grouping of objects used together in hopes that these objects will be used together again — spatial locality and used soon enough — temporal locality. In fact, Hermes optimizes based on spatial criteria. This notion of locality works well in LAN, where the transaction can run in a partition with the data without a performance penalty. However, in WAN, moving transactions between partitions is costly. If a transaction originated in region R1, but data is in region R2, then moving the transaction from R1 to R2 may incur almost as much latency as moving data from R2 to R1. That is a big difference between LAN and WAN — in the WAN setting, transactions incur a significant latency penalty when processed in another region. In geo-distributed setting, locality means more than just grouping frequently used objects together to rip the benefit shortly. In addition to grouping data based on spatial principles, we need to preserve the geographical affinity and place data close to where it is accessed. In other words, in geo-replication, we do not only care about finding cliques of related data, but also placing these cliques in the best possible geography for a given workload. And needless to say, grouping objects and finding the best geographical location for the data often conflict with each other, making the problem significantly more nuanced and complicated.
2) Workload. A significant motivation for the paper is the existence of workloads with significant and abrupt access pattern changes. The paper refers to Google workload traces for the example of such abrupt workloads. The authors also conduct a significant portion of the evaluation on the workload created from these traces. We are a bit skeptical, at least on the surface, about the validity of this motivation. One reason for skepticism is the traces themselves — they come from Google Borg, which is a cluster management system. While Borg is obviously supported by storage systems, the traces themselves are very far from describing some actual database/transactional workload. It would be nice to see a bit more details on how the authors created the workload from the traces and whether there are other examples of workloads with abrupt access pattern changes.