Our 73rd reading group meeting continued with discussions on transaction execution systems. This time we looked at the “Polyjuice: High-Performance Transactions via Learned Concurrency Control” OSDI’21 paper by Jiachen Wang, Ding Ding, Huan Wang, Conrad Christensen, Zhaoguo Wang, Haibo Chen, and Jinyang Li.
This paper explores single-server transaction execution. In particular, it looks at concurrency control mechanisms and conjectures that the current approaches have significant limitations for different workloads. For instance, two-phase-locking (2PL) may work better in workloads that have high contention between transactions, while Optimistic Concurrency Control (OCC) works best in low-contention scenarios. A natural way to solve the problem is to create a hybrid solution that can switch between different concurrency control methods depending on the workload. A paper mentions a few such solutions but also states that they are too coarse-grained.
Polyjuice presents a different hybrid strategy that allows a more fine-grained, auto-tunable control over transaction concurrency control depending on the workload. The core idea is to extend the existing concurrency control mechanisms into a set of actions and train the system to take the best actions in response to each transaction type, transaction’s dependencies, and the current step within the transaction.
Possible actions Polyjuice can take include different locking options, whether to allow dirty reads, and whether to expose dirty writes.
For the sake of time, I will only talk about locking actions. Each transaction upon accessing some data must pick the concurrency control actions. For example, if some transaction “B” has another transaction “A” in its dependency list for some key, it needs to decide whether to wait or not for the dependent transaction “B.” In fact, “B” has a few options in Polyjuice: be entirely optimistic and not wait for “A” or to be more like 2PL and halt until the dependent “A” has finished. In addition to the two extremes, Polyjuice may tweak this lock to wait for partial execution of the dependent transaction.

Polyjuice system represents the possible concurrency control actions through the state and action space policy table. In the table, each row is a policy for a particular step of a particular transaction. Each column is an action type. Wait actions are specific to dependents of a transaction, so if a transaction has a dependency, we will pick the wait action corresponding to the dependency. The cells then represent the action parameters, such as the wait duration or whether to read dirty.
So, to operate the concurrency control actions, we need to maintain the dependency lists for transactions and tune the policy table for optimal parameters. The tuning is done with a reinforcement-learning-like approach, where we aim to optimize the policy (our table that maps state to actions) for maximizing the reward (i.e., the throughput) in a given environment (i.e., the workload). The actual optimization is done with an evolutionary algorithm, so it is a bit of a random process of trying different parameters and sticking with the ones that seem to improve the performance.
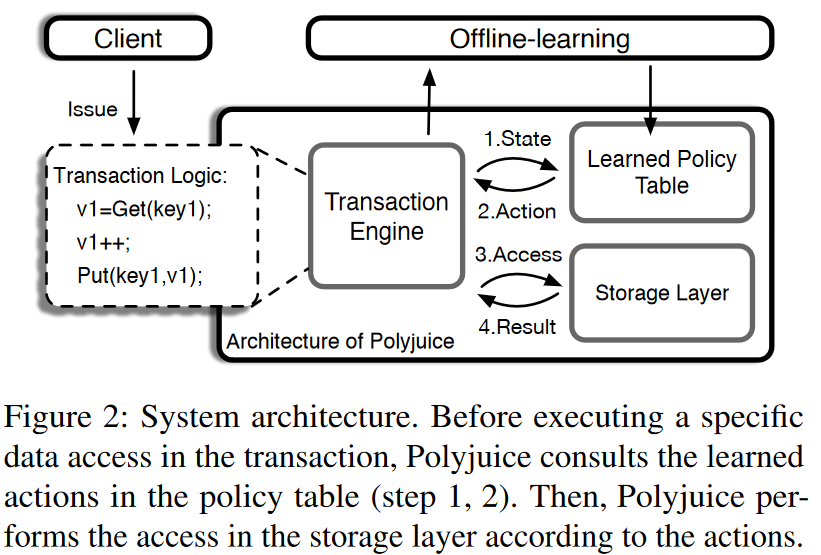
It is important to note that the Polyjuice concurrency control policy is not ensuring the safety of transactions. It merely tries to tweak the waits and data visibility for best performance. So when each transaction finishes with all its accesses/steps, Polyjuice runs a final validation before committing. If the validation passes, then everything is ok, and if not, the transaction is aborted. This makes the entire concurrency control process optimistic, despite adding some waiting/locks for dependencies. In my mind, Polyjuice is a “loaded” optimistic concurrency control that tries to improve its chances of passing the validation and committing as quickly as possible. Kind of like a loaded die with a higher chance of getting the value you are betting on.
Our presentation video is available below. Peter Travers volunteered for this paper about a day before the meeting, saving me from doing it. So big thanks to Peter, who did an awesome job presenting.
Discussion
1) Single-server transactions. Polujuice is a single-server system, which makes some of its transactional aspects a lot simpler. For example, keeping track of transaction dependencies in a distributed system would likely involve some additional coordination. As we have seen in Meerkat, additional coordination is not a good thing. At the same time, there may be some interesting directions for learned CC in distributed space. For example, we can train a separate model or policy table for different coordinators in the systems. This can be handy when deploying the system across WAN with non-uniform distances between nodes or coordinators. I was originally excited about this possibility, and it feels like a natural direction for research.
2) Fixed transaction types. The system expects a fixed set of transaction types — transactions that have the same “code” and execute the same logic, but on different data. It is not entirely clear what will happen when a new transaction type arrives at the system before Polyjuice is retrained to include this new type. We would expect some sort of a default fall-back mechanism to be in place.
3) Evolutionary algorithm. So this is an interesting part. Polyjuice uses an evolutionary optimization algorithm to train its policy model. These types of algorithms try to mimic natural evolutionary processes to arrive at the more optimal solution. For example, the systems may start with an initial population of policies, then it needs to evaluate how these initial population performs, pick the two best policies, and somehow combine them. This combined policy (i.e., the offspring of the two best ones) can then replace the weakest performing policy in the population. The process can repeat.
The paper actually does not use a crossover approach to produce offspring between the best policies. Polyjuice creates “children” by mutating the parameters of the good parents to produce the next population generation. It then evaluates this next generation, prunes the weak policies, and repeats the process.
The paper claims this works well, but we were wondering about the convergence of this to an optimal solution. Can the evolutionary algorithm get stuck in some local maximum and not find the best policy? Another concern is the time to converge, and the training impact on the transactional performance. To find the best policies, Polyjuice needs to evaluate the entire population. While this is happening, the performance of the system may stutter and jump back and forth as it tries different policies, which is not ideal in production workloads. At the same time, we must use production workloads to train the policy. And of course, the process requires multiple iterations.