Hard to imagine, but the reading group just completed the 45th session. We discussed “Pegasus: Tolerating Skewed Workloads in Distributed Storage with In-Network Coherence Directories,” again from OSDI’20. Pegasus is one of these systems that are very obvious in the hindsight. However, this “obviousness” is deceptive — Dan Ports, one of the authors behind the paper who joined the discussion, mentioned that the project started in 2017, so it was quite a bit of time from the start to publish with a lot of things considered and tried before zeroing in on what is in the paper.
Pegasus is a replication system for load balancing and throughput scalability in heavily skewed workloads. Consider a workload with a handful of “hot” objects. These hot objects may have so much usage, that they overwhelm their respective servers. Naturally, this limits the overall throughput because the system is now capped by servers at their maximum capacity/utilization. The solution is to replicate these hot objects to many servers and allow clients to access them from multiple replicas. However, as soon as we have a replicated scenario, we start running into consistency issues. Strongly consistent systems often degrade in performance with the addition of more replicas due to the synchronization overheads. This is what makes Pegasus rather unique — it scales for load balancing through replication while remaining strongly consistent. The key enabler of this is the smart Top of Rack (ToR) switch that handles all the traffic in the server rack. This switch acts as the “source of synchrony” in the rack, and it does so at the packet’s line speed.
In Pegasus, the data is assigned to servers in the rack using a consistent hashing mechanism, allowing clients to send the requests directly to servers that own the data. However, all these requests go through the ToR switch which can inspect the packets and make some additional routing decisions for “hot” objects. Let’s consider a write request for a such high-demand object. ToR inspects a packet, and if it is for a “hot” key, it sends the write message to some larger and potentially different set of servers in a rack, essentially increasing the replication factor and rotating the responsible servers. Once the servers ack the write completion, the ToR switch sees the acks and records these servers into its coherency directory as servers with the latest copy of the data. The read requests have a similar rerouting fate — if a read is for a hot object, instead of going to the default server, the ToR switch sends it to one of the replicas from its coherency directory. The paper has more details on implementing this coherency directory and keeping track of the recent progress using a simple versioning mechanism.
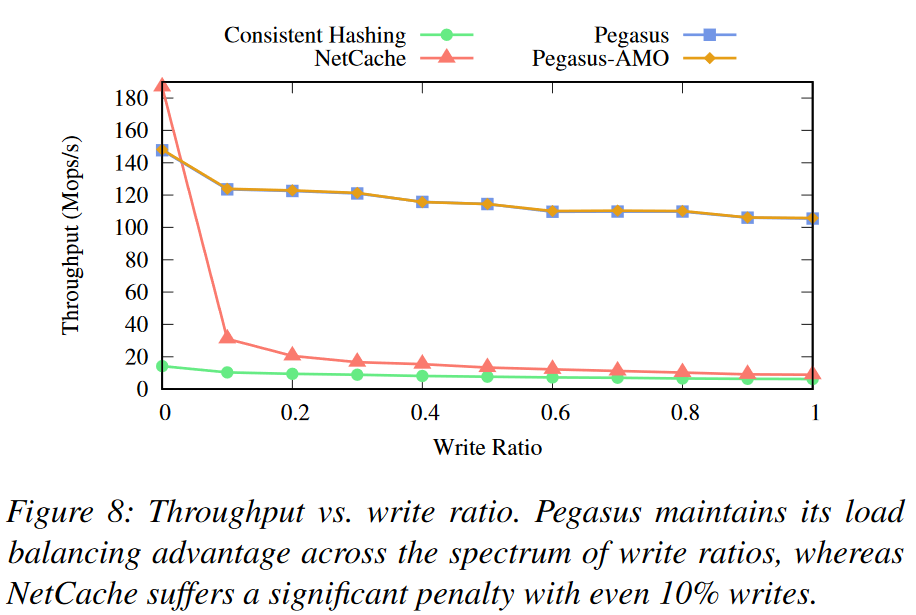
The end result is awesome! Just by replicating a handful of objects in skewed workloads (~16 objects out of a million in the paper), Pegasus achieves load balancing and high throughput beating in-network caching in almost all scenarios. There are a few other advantages to Pegasus that are missing in other SOTA solutions: the ability to store larger objects (not evaluated), and tolerance of workloads with different read-write ratios (evaluated extensively).
Finally, I have not touched on a few other important pieces of the system: figuring out which keys are hot and fault-tolerance. For measuring the key temperature, the Pegasus statistics engine samples some packets and determines the frequency of keys in the samples to make gauge how hot each key is. For fault-tolerance, the system uses chain replication across racks for durability.
As always, we have our presentation of the paper by A. Jesse Jiryu Davis:
Discussion
This time around we had Dan Ports join us to answer the questions about the paper, so this turned out to be a nice discussion despite a slightly lower than expected attendance.
1) Simple API. Currently, Pegasus supports a simple API with reads and simple destructive writes (i.e. each write is an unconditional overwrite of the previous copy of the data). The main reason for this is how the writes are structured in Pegasus. The system is very nimble and quickly adjustable, it picks write servers on the fly as the write request “goes through” the switch. This means that a write should be able to just complete on the new server. However, if the write operation is, for example, a conditional write or an update, then such an update also needs to have the previous version of the object, which may be missing on the new server. We have spent some time discussing workarounds for this, and they surely seem possible. But the solution also introduces additional communication, which both introduces more load to the servers and more latency for operations. And since we are dealing with a subset of objects that already generate the most load in the system, adding anything more to it must be avoided as much as possible. The cost of supporting these more complex API will also differ for various read-write ratios.
2) Comparison with caching. Another big discussion was around using caching to load balance the system. As Dan pointed out, caches are good when they are faster than storage, but for super-fast in-memory storage, it is hard to make a cache faster. NetCache (one of the systems used for comparison in the paper) does provide a faster cache by placing it in the network switch. It has several downsides: handles only small objects, consumes significant switch resources, and does not work well for write workloads (this is a read-through cache, I think). Of course, it is possible to make it a write-through cache as well to optimize for write workloads, but it still does not solve other deficiencies and adds even more complexity to the system. We also touched on the more complicated fault-tolerance of cached systems. The disparity between the load that cache and underlying systems can take can create situations when the underlying systems get overrun upon cache failure or excessive cache misses.
3) Chain replication. Since Pegasus replicates for scalability, it needs a separate mechanism to handle fault-tolerance. The paper suggests using a chain replication approach, where racks are the chain nodes. Only the tail rack serves reads, however, the writes must be applied in all racks as the write operation propagates through the chain. One question we had is why not use something like CRAQ to allow other racks to serve reads, but the reality is that this is simply not needed. The chances that an object can become so skewed and hot that it needs more than a rack worth of servers are very slim, so there is no need to complicate the protocol. Another question I have now but forgot to ask during the discussion is what happens to hot writes as they go through the chain? If non-tail racks only use the default server for writes on “hot” keys (instead of let’s say round-robin or random node), then this server may get overwhelmed. But I think it is trivial to pick a random server for the hot object on each write at the non-tail racks.
4) Zipfian distribution and workload skewness. Pegasus needs to load-balance fewer keys for a less skewed Zipfian distribution. This was an interesting and a bit counter-intuitive observation at the first glance since one can intuitively expect the more skewed distribution to require more load-balancing. However, a higher alpha Zipf has more skewed objects, but not necessarily more skewed objects than a lower alpha Zipfian distribution. Fewer highly skewed objects mean less load-balancing.
5) Virtualization of top-of-rack switches. One important question about the technology that enables Pegasus is the virtualization of these smart ToR switches. Currently, it is not the case, so one needs to have bare-metal access to a switch to deploy the code. Virtualization of such a switch may make the technology available to cloud users. I think this would be a huge boost to the overall state of distributed computing at the datacenter level. I would be speculating here, but I think a lot depends on the willingness of manufacturers to provide such support, especially given the relatively limited capabilities of the hardware right now. Of course, the virtualization should not add a significant latency penalty to the users, and most importantly should not add any penalty to non-users (applications/systems that reside in the same rack but do not use the extended capabilities of the switches). Couple all these with the risks of running user’s code on the hardware that handles all the traffic in the rack, and we also need to worry about user isolation/security more than ever. However, as wishful as it is, it is quite probable that these smart switches will not make their way to the public cloud any time soon. This gives large cloud vendors an edge since they can benefit from the technology in their internal systems. Smaller service providers that rely on the cloud, however, will have to find a way to compete without access to this state-of-the-art technology. Aside from my extremely high-level speculations, some smart people actually go deeper into the topic.
6) There were a few other minor topics discussed, and jokes are thrown here and there. For example, Dan explains Pegasus with cat pictures.