Short Summary
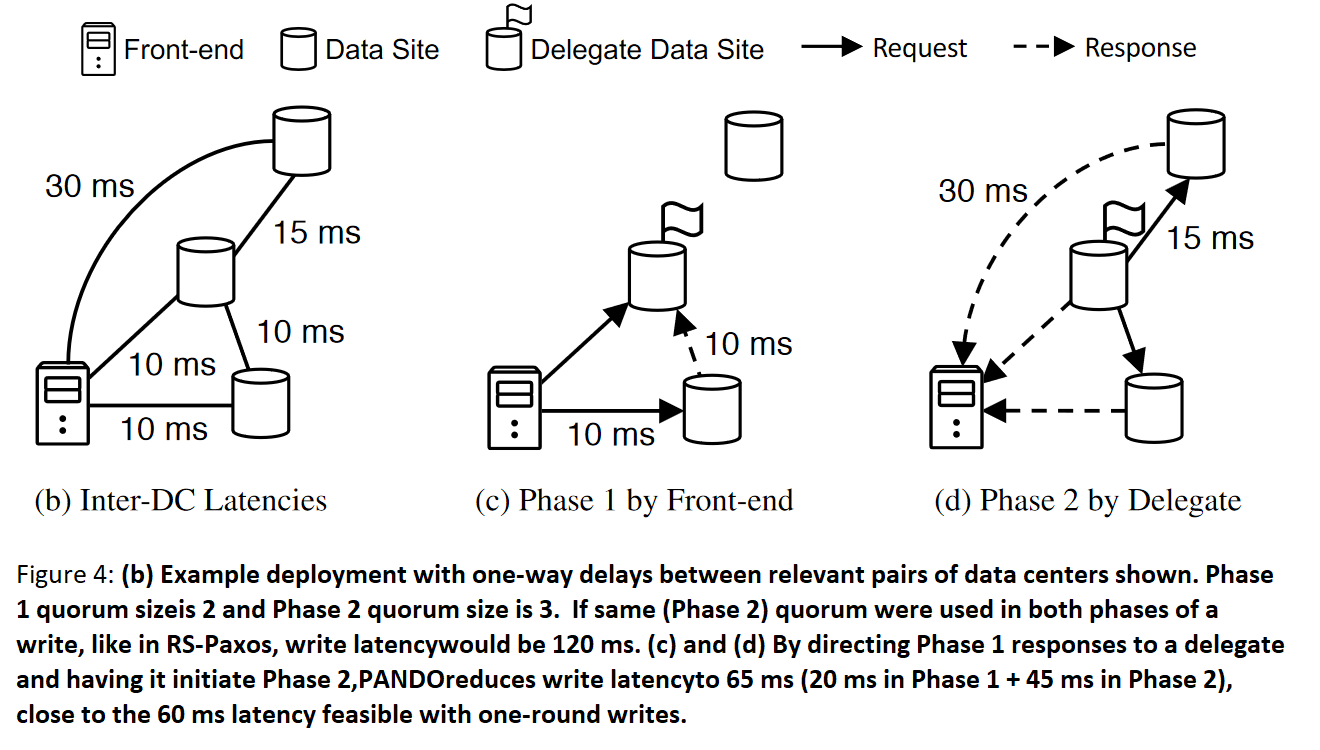 Yesterday we discussed Pando, a geo-replication system achieving near-optimal latency-cost tradeoff in storage systems. Pando uses large Flexible Paxos deployments and erasure coding to do its magic. Pando relies on having many storage sites to locate sites closer to users. It then uses Flexible Paxos to optimize read and write quorums to have the best latency for a particular workload. Finally, erasure reduces the cost associated with having many storage sites. There are a few caveats to the paper. First is the slowness of the (Flexible) Paxos protocol, as it requires two phases to complete an operation. Pando addresses this issue with a cool use of delegate nodes — one of the nodes from phase-1 quorums acts as a delegate on behalf of the client-proposer to collect phase-1 acks and start phase-2. This can save significant latency, getting the full two-rounds in geo deployments closer to the one round RTT of a regular proposer-driven Paxos. The second problem is the quorum overlaps when using erasure coding. If the data is split into k parts, we need to ensure the k-nodes overlap between the read and write quorums, making erasure coding detrimental to achieving low latency. This k-nodes overlap is needed to restore the latest version of the data, as having fewer than k-nodes with the latest version is not enough to reconstruct the data. Pando, however, first tries to read from a smaller quorum that guarantees just one node overlap and hopes that there will be enough nodes that have received the update by the time a read is issued. If there are no k nodes to reconstruct the data, Pando continues waiting for more nodes to respond to get to that large quorum with k-nodes overlap.
Yesterday we discussed Pando, a geo-replication system achieving near-optimal latency-cost tradeoff in storage systems. Pando uses large Flexible Paxos deployments and erasure coding to do its magic. Pando relies on having many storage sites to locate sites closer to users. It then uses Flexible Paxos to optimize read and write quorums to have the best latency for a particular workload. Finally, erasure reduces the cost associated with having many storage sites. There are a few caveats to the paper. First is the slowness of the (Flexible) Paxos protocol, as it requires two phases to complete an operation. Pando addresses this issue with a cool use of delegate nodes — one of the nodes from phase-1 quorums acts as a delegate on behalf of the client-proposer to collect phase-1 acks and start phase-2. This can save significant latency, getting the full two-rounds in geo deployments closer to the one round RTT of a regular proposer-driven Paxos. The second problem is the quorum overlaps when using erasure coding. If the data is split into k parts, we need to ensure the k-nodes overlap between the read and write quorums, making erasure coding detrimental to achieving low latency. This k-nodes overlap is needed to restore the latest version of the data, as having fewer than k-nodes with the latest version is not enough to reconstruct the data. Pando, however, first tries to read from a smaller quorum that guarantees just one node overlap and hopes that there will be enough nodes that have received the update by the time a read is issued. If there are no k nodes to reconstruct the data, Pando continues waiting for more nodes to respond to get to that large quorum with k-nodes overlap.
The presentation video:
Discussion
1) ConfigManager. ConfigManager is a component of Pando that computes desirable quorums and delegates for each key and key’s access pattern. We felt like this ConfigManager is very important for the performance of Pando, and it was rather under-specified in the paper. For example, we were wondering if it is possible to make the ConfigManager dynamic and make it learn the workload paters and adjust as needed.
2) Read consistency. Pando uses quorum reads while using Paxos for writes. Naively reading from a quorum is dangerous and can lead to linearizability problems, yet the reads are not discussed in detail in the paper. The paper briefly in one sentence mentions that to enable quorum reads a global acknowledgment is needed to make sure all nodes know a value has been committed. But Pando does not explain how such commitment works and does not study the performance consequences of this. For example, if a value has been accepted by all nodes, but the commit message is still in flight, does the client read the previous value, or does it retry? If the read quorum has some nodes that have received the commit messages, and some that do not, is it safe to read a new value, or a retry is needed? We do not think it is safe to read, and the paper seems to mention that in passing as well. There are quite a few more questions around the reads and their safety here, so we wished the paper addressed the reads in greater detail.
3) Rare conflicts. One of the motifs in the paper is that conflicts are rare in scenarios Pando is designed for. This influences a lot of design, as most of the systems are written to work well in the conflict-free case, and somehow address conflict case. For example, when two clients try to write on the same key/document, that will cause a conflict, and Paxos is not very good at handling it due to the dueling-leader problem. Same for the read problem above in (2), as we feel like conflicts will cause the retries, significantly impacting the performance. What is interesting is that despite largely conflict-free evaluation, Pando did better than Fast Paxos in latency, a protocol designed for 1 RTT consensus in conflict-free cases. We feel like the reason is that Pando can get its writes close to 1 RTT with the clever delegates trick, while it can keep the read quorums small to optimize for latency, while Fast Paxos approach is stuck with larger quorums for reads.
4) Quorum Size. We have spent quite a bit of time discussing quorum sizes. We were confused a bit about the quorum descriptions from the paper, but in the end, we were able to figure out our misunderstanding.
5) Comparison with Atlas. Pando extensively compares with EPaxos. Atlas is a newer, EPaxos-influenced protocol, so we were curious about how the two would compare.
6) Scalability. Reducing latency is very important for WAN setups, however, we felt that the paper is not addressing the throughput question. Having too many nodes may have an impact on scalability/throughput. Since Pando uses the clients as proposers, the grunt of dealing with too many storage replicas goes to the clients, and scalability should not be impacted that much. However, the delegates may become the bottlenecks for some workloads.
7) Delegates for throughput. Pando uses delegates to improve latency. We noticed that a somewhat similar idea is used in Compartmentalized Paxos and PigPaxos to improve the throughput instead.
Next Meeting
As always, next week we will continue looking at more great distributed systems papers. We are starting with the OSDI 2020 bunch of papers, and in our next meeting, we will discuss “Fault-tolerant and transactional stateful serverless workflows.” Please join our slack to participate in the discussions and Zoom meetings.