Our 43rd reading group paper was about an extremely low-latency consensus using RDMA: “Microsecond Consensus for Microsecond Applications.” The motivation is pretty compelling — if you have a fast application, then you need fast replication to make your app reliable without holding it back. How fast are we talking here? Authors go for ~1 microsecond with their consensus system called Mu. That is one-thousandth of a millisecond. Of course, this is not achievable over a regular network and network protocols like TCP, so Mu relies on RDMA.
In my mind, Mu maps rather perfectly to Paxos/MultiPaxos, adjusted for the RDMA usage. Accept phase is pretty much Paxos phase-2. The leader directly writes to the follower’s memory. Mu does not use protocol-specific acks, but there is still an RDMA-level ack for successfully writing memory and thus completion of phase-2. Of course in Paxos, followers must check the ballot before accepting an operation in Phase-2. This requires processing and will negate the benefits of direct memory access. To work around the problem, Mu uses RDMA permissions to control whose memory writes are accepted in phase-2. The bottom line, however, is that we have a single round trip phase-2 capable of rejecting messaging from “wrong” leaders, just like in Paxos.
Paxos elects a leader in phase-1. In Mu, the equivalent of phase-1 consists of 2 sub-phases. First, a prospective leader contacts the quorum of followers and tells them to change the permissions from an old leader to itself. This prevents the old leader from writing to a quorum and makes it stop. This quorum becomes “the leader’s go-to quorum”, as it can only write to the nodes from that quorum due to permissions. In the second sub-phase, the prospective leader learns of the past proposal/ballot number and any past operations to recover. The leader then picks a higher proposal number and writes it back. Just like in Paxos/MultiPaxos, the leader must recover the learned commands.
Another prominent part of the paper is the failure detector. The authors claim that it allows for fast leader failover. The detector operates by a pull mechanism — a leader maintains a heartbeat counter in its memory, and increments it periodically, the followers read the counter and depending on the counter’s progress adjust the “badness” score. If the counter moves too slow or does not move (or not readable at all?), the badness score becomes high, causing the follower to decide that a leader has failed and try to take over.
As always, the paper has way more details than I can cover in a short summary. Our group’s presentation by Mohit Garg is available on YouTube:
Discussion
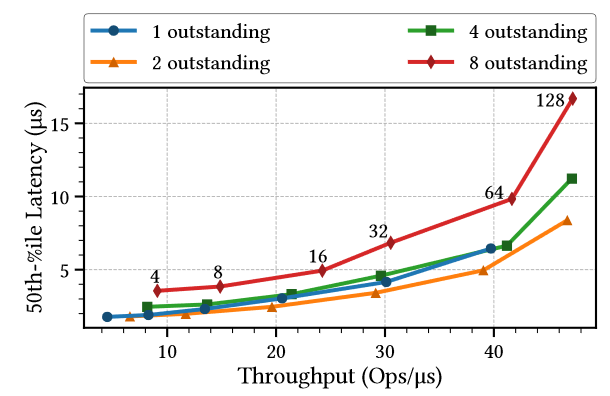
1) Performance. Microsecond latency covers only replication and does not include any of the client interactions or request capture. These components may add a significant delay to the client-observed latency. Moreover, the throughput figure has latency that is at least somewhat close to 1 microsecond only at the low-end of the throughput curve. Pushing more operations degrades latency quite significantly — up to 15 microseconds. Of course, it is worth noting that this is with batching enabled, so still pretty impressive.
2) Use of RDMA permissions for leader enforcement. This looked familiar to me… Until I was reminded that in the 17th reading group meeting we looked at the “Impact of RDMA on agreement” paper by the same authors.
3) Quorums. Since the protocol relies on the permissions to be explicitly granted to a leader when it contacts a quorum, that leader cannot use any other quorum, as it won’t have permissions to access it. We were not very sure why a leader cannot contact all nodes and try to get permissions to all of them. It still needs only the majority to succeed, but having more than the quorum of nodes who can accept writes from leader may be handy, since trying to write to more nodes than the minimal quorum can be useful for controlling the tail latency and tolerating strugglers.
4) Flexible Quorums. This continues the above point about quorums. Flexible quorums are quite useful in trading off fault tolerance and scalability. Since Mu is restricted to just one quorum that granted the write permissions, it cannot take advantage of flexible quorums, such as grids.
5) Failure detector. Failure detector is one of the most interesting and controversial features in Mu. We have spent quite a bit of time discussing it. First of all, what does the pull model give us? Every follower keeps pegging the leader and reading some counter. But what if the leader is actually totally and utterly down, how can you read the memory of the crashed server to learn its counter and compute the badness score from it? Of course, if a follower cannot read, then it can conclude that the leader is down and start the leader election, but this is not explicitly mentioned in the paper. So what is the purpose of reading a counter and having the counter increase then? Being able to read the counter clearly means the leader is up, at least in some capacity. The counter and badness score computed from it is not so much the proxy of the node’s overall up/down status, but the proxy of the node’s health/performance. The paper briefly alludes to this when talking about replication being stuck, eventually causing the heartbeat counter to stop as well and trigger an election, despite the leader not being completely down.
In the discussion, we came up with a different heartbeat mechanism, that avoids the “read from dead node” issue. If we make the leader write its counter to the followers’ memory, and followers read their local copy of the leader’s counter, then a leader crash will stop the counter progress, and followers can detect it by reading their local memory. Quite honestly, this scheme sounds cleaner to us than the follower pull/read approach used in the paper. The authors claim that the pull mechanism provides better detection latency, but this is not backed up experimentally in the paper.
6) “Dumb” acceptors. Mu is not the only protocol that assumes “dumb” Paxos acceptors/followers that simply provide a write/read interface with very little capacity to run any “logic”. Disk Paxos assumes separate sets of processors and disks. One processor can become a leader, and disks are the followers. Disk Paxos, of course, would not provide the same low latency, as in each phase a processor needs to both write and read remote disks/storage. The paper briefly mentions Disk Paxos. CPaxos is a WAN Paxos variant built using strongly consistent cloud storage services as acceptors. Similarly, the storage service provides limited ability to run any logic and the leader must jump through some hoops to maintain safety. Another one mentioned in the discussion was Zero-copy Paxos.
7) Ordered communication for correctness. We spent a bit of time talking about the importance of ordered communication (FIFO) for the correctness of the protocol. If not for FIFO, there could have been some interesting corner cases around the leader churn. I usually do not fully trust papers that just state the assumptions of the FIFO channels and move on, since traditionally you may have quite a few corner-cases with systems built on FIFO network protocols, like TCP, and have messages reordered. One common reason is that applications often have complex and multi-threaded logic, and may reorder messages internally after the messages have left the TCP stack. Here, however, there is no logic at the followers, and it makes the ordered network all you need (assuming there are no other corner-cases in the network, like dropped connections and re-connections).