Last week we discussed the “FoundationDB: A Distributed Unbundled Transactional Key Value Store” SIGMOD’21 paper. We had a rather detailed presentation by Moustafa Maher.
FoundationDB is a transactional distributed key-value store meant to serve as the “foundation” or lower layer for more comprehensive solutions. FoundationDB supports point and ranged access to keys. This is a common and decently flexible API to allow building more sophisticated data interfaces on top of it.
FoundationDB is distributed and sharded, so the bigger part of the system is transaction management. The system has a clear separation between a Paxos-based control plane and the data plane. The control plane is essentially a configuration box to manage the data plane. On the data plane, we have a transaction system, log system, and storage system. The storage system is the simplest component, representing sharded storage. Each node is backed by a persistent storage engine and an in-memory buffer to keep 5 seconds of past data for MVCC purposes. The storage layer is supported by sharded log servers that maintain the sequence of updates storage servers must apply.
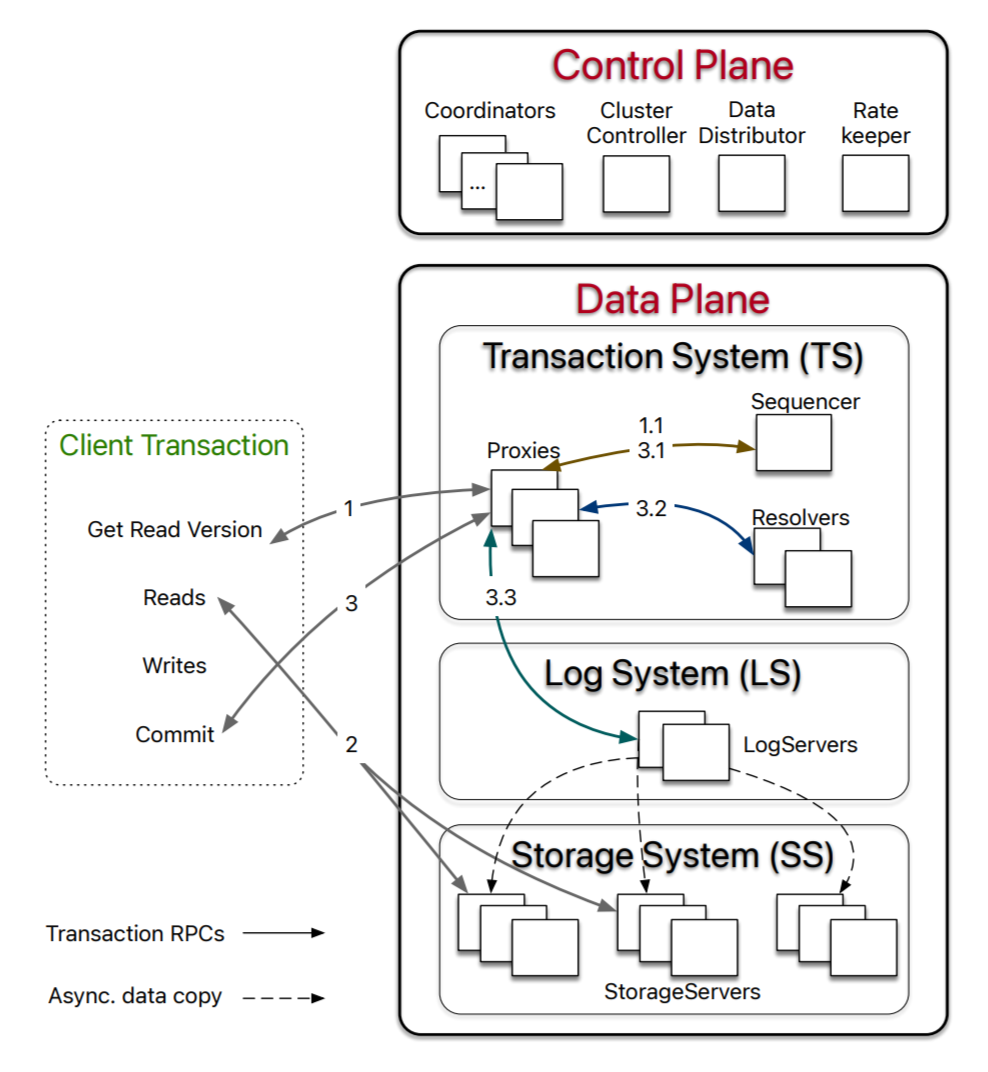
The interesting part is the transaction system (TS) and how clients interact with all the components on the data plane. The client may run transactions that read and/or update the state of the system. It does so with some help from the transaction system, which also orchestrates the transaction commit. When a client reads some data in a transaction, it will go to the transaction system and request a read timestamp or version. On the TS side, one of the proxies will pick up the client’s request, contact the sequencer to obtain the version and return it to the client. This version timestamp is the latest committed version known to the sequencer to guarantee recency. Thanks to MVCC, the client can then reach out directly to the storage servers and retrieve the data at the corresponding version. Of course, the client may need to consult the system to learn which nodes are responsible for storing particular keys/shards, but the sharding info does not change often and can be cached.
Writes/updates and transaction commit procedure are driven by the TS. The client submits the write operations and the read-set to the proxy, and the proxy will attempt to commit and either return an ack or an abort message. To commit, the proxy again uses the sequencer to obtain a commit version higher than any of the previous read and commit versions. The proxy will then send the read and write set along with the versions to the conflict resolver component. The resolver detects the conflicts; if no conflict is detected, the transaction can proceed, otherwise aborted. Successful transactions proceed to persist to the log servers and will commit once all responsible log servers commit. At this point, the sequencer is updated with the latest committed version so it can continue issuing correct timestamps. Each transaction must complete well within the 5 seconds of the MVCC in-memory window. Needless to say, read-only transactions do no go through the write portion of the transaction path since they do not update any data, making reads low-weight.
The failure handling and recovery is an important point in any distributed system. FoundationDB takes a fail-fast approach that may at times sound a bit drastic. The main premise of failure handling on the transaction system is to rebuild the entire transaction system quickly instead of trying to mask failure or recover individual components. The committed but not executed transactions can be recovered from the log servers and persisted to storage, in-progress transactions that have not made it to the log servers are effectively timed out and aborted. Transactions that partly made it to the log servers are also aborted, and new log servers are built from a safe point to not include the partial transactions. Here I just scratched the surface on the recovery, and the paper (and our group’s presentation) is way more accurate and detailed.
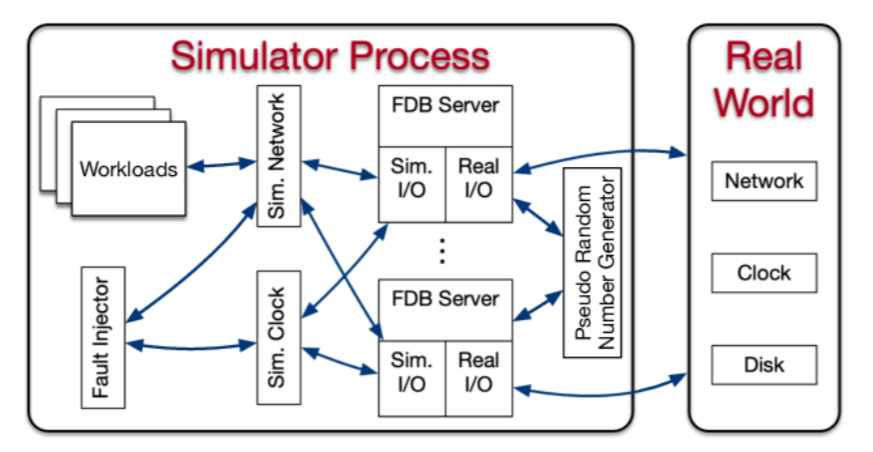
Another important point in the paper is the testing and development of FoundationDB. The paper talks about simulator testing. In a sense, the simulator is an isolated environment for development and testing the full stack on just one machine. It comes with a handful of mock components, such as networking and a clock. All sources of non-determinism must be mocked and made deterministic for reproducibility. The paper claims that the simulator is very useful for catching all kinds of bugs with a few exceptions, such as performance bugs.
Discussion.
1) Flexibility of FoundationDB. Our previous paper was on RocksDB, a key-value single server store. It is meant as the building block for more complex systems and applications. This is very similar in spirit to FoundationDB that is meant as a “foundation” for many more complex systems. However, FoundationDB is way more complex, as it implements the data distribution/replication and transactions. This can potentially limit the use cases for FoundationDB, but obviously, this is done by design. With replication and transactions are taken care of, it may be easier to build higher-up levels of the software stack.
2) Use cases. So what are the use cases of FoundationDB then? It is used extensively at Apple. Snowflake drives its metadata management through FoundationDB. In general, it seems like use cases are shaped by the design and limitations. For example, a 5-seconds MVCC buffer precludes very long-running transactions. The limit on key and value size constrains the system from storing large blobs of data. Arguably, these are rather rare use cases for a database. One limitation is of particular interest for me, and this is geo-replication.
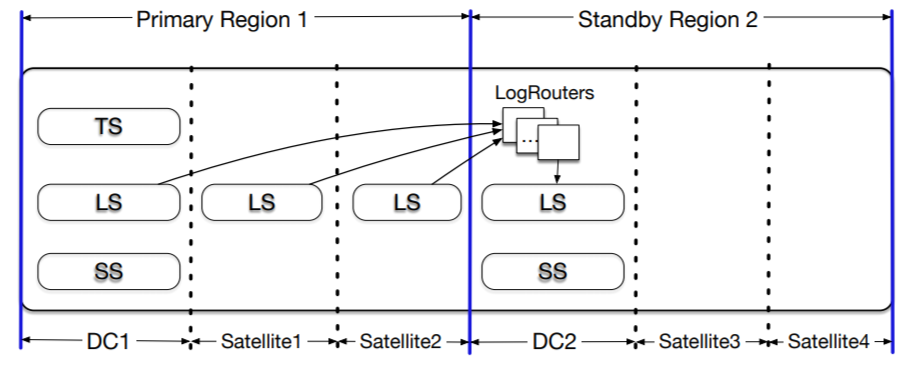
3) Geo-replication. The paper touches on geo-replication a bit, but it seems like FoundationDB uses geo-replication mainly for disaster tolerance. The culprit here is the sequencer. It is a single machine and this means that geo-transactions have to cross the WAN boundary at least a few times to get the timestamps for transactions. This increases the latency. In addition to simply slower transactions, numerous WAN RTT to sequencers can push the transaction time closer to the 5-second limit. So it is reasonable to assume that the system is not designed for planetary-scale deployment.
4) Simulator. We discussed the simulator quite extensively since it is a cool tool to have. One point raised was how a simulator is different from just setting up some testing/development local environment. The big plus for a simulator is its ability to control determinism and control fault injections in various components. There are systems like Jepsen to do fault injection and test certain aspects of operation, but these tend to have more specific use cases. Another simulator question was regarding the development of the simulator. It appears that the simulator was developed first, and the database was essentially build using the simulator environment.
We were also curious about the possibility of a simulator to capture error traces or do checking similar to systems like Stateright. It appears, however, that this is outside of the simulator capabilities, and it cannot capture specific execution traces or replay them. It is capable of controlling non-deterministic choices done in mock components, making a failure easier to reproduce. One somewhat related point mentioned was eidetic systems that remember all non-deterministic choices made in the OS along with all inputs to be able to replay past execution, but this seems like an overkill to try to build into a simulator.