Last DistSys Reading Group we have discussed “FlightTracker: Consistency across Read-Optimized Online Stores at Facebook.” This paper is about consistency in Facebook’s TAO caching stack. TAO is a large social graph storage system composed of many caches, indexes, and persistent storage backends. The sheer size of Facebook and TAO makes it difficult to enforce meaningful consistency guarantees, and TAO essentially operates as an eventual system, despite having some stronger-consistency components in it. However, a purely eventual system is very unpredictable and hard to program for, so TAO initially settled for providing a read-your-write (RYW) consistency property. The current way of enforcing RYW is FlightTracker. FlightTracker is a recency token (Facebook calls these tokens Tickets) system running in every Facebook datacenter. Tickets keep track of recent writes performed by a datacenter-sticky user session. In a sense, the ticket is a set of tuples <Key, Key-Progress>, where the Key-Progress is some value to designate the recency of the write on the Key, like a version, timestamp, or a partition sequence number. The reads then include the ticket and propagate it across the stack to the nodes that serve the requests. With the recency information in the ticket, a server can make a local decision on whether it is sufficiently up-to-date. If the node is stale, it can forward the request to a higher-level cache or durable store to retrieve the data.
Many other systems use recency tokens, but they usually do not explicitly specify all writes done by the user. For example, a token may be a single number representing the last transaction id seen by the client. This is good for making sure the recency tokens are small, but it has a smaller resolution — such token will enforce a per partition recency instead of per key, and cause too many caches misses when the per-key RYW guarantees are needed.
However, keeping and transferring the explicit set of all client’s write is expensive, so FlightTracker uses a few compaction strategies. For one, it is only sufficient to keep track of the most recent write on the key. Secondly, in some workloads with a larger number of writes, FlightTracker may reduce the resolution and stop tracking individual writes and, for example, switch to a partition-level tracking by transaction id or sequence number. Finally, TAO stack enforces some bounded consistency of about 60 seconds, so the writes older than 60 seconds can be purged from the ticket.
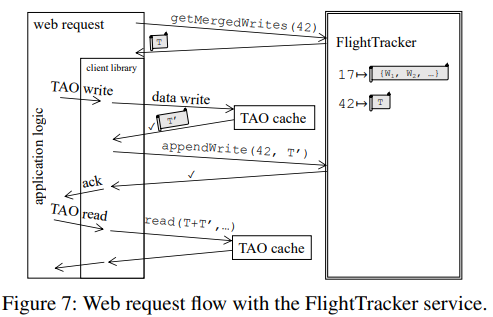
FlightTracker stores the tickets in simple replicated systems based on a distributed hashing. Upon reads, the ticket is first fetched from the FlightTracker, and then included with all the read operations. Since one request typically makes many reads, the cost of ticket fetching is amortized over many read operations. Nevertheless, the FlightTracker is fast to fetch tickets — it takes just ~0.3 ms. Whenever writes happen, a ticket for a particular user session is updated to include the new writes and exclude the compacted ones.
The paper has many details that I have left out of this summary and the presentation:
Discussion
1) What can go wrong if RYW is broken? The paper discusses the RYW topic quite substantially. One important point here is that RYW enforcement is “relatively” cheap — it provides some useful consistency guarantee without making cache misses due to consistency (i.e. consistency misses) too frequent. So it appears like a balance between the usefulness and the cost of consistency properties at the Facebook scale. However, the paper does not talk much about what can go wrong in Facebook (or more specifically in applications that rely on the social graph) if RYW does not hold. The paper mentions that it is a reasonable default consistency for developers and users. In our discussions, we think it is more useful for the end-users. If a person posted something on the site, then refreshed the page and the post does not appear because of RYW violation, the user may get confused whether the site is broken, or whether they pressed the right button. We do not think that in most cases there will be serious consequences, but since Facebook is a user-centric application, providing intuitive behavior is very important. Actually, the paper suggests that RYW violations may still happen, by saying that the vast majority of servers (>99.99%) are within the 60 seconds staleness window. This means that in some rare cases it is possible to have a “clean” ticket after compaction and hit one of these <0.01% of servers and get stale data.
2) Architectural style. So… this is a Facebook paper, and you can feel it. Just like many other Facebook papers, it describes the system that appears very ad-hoc to the rest of the stack. The original TAO is also a combination of ad-hoc components bolted together (does it still use MySQL in 2021?). The FlightTracker was added to TAO later as an after-thought and improvement. Not a bad improvement by any means. And having all the components appear separate and independent serves its purpose – Facebook can build a very modular software stack. So anyway, this appears like a very “engineering” solution, bolted onto another set of bolt-on components. And it servers the purpose. Having 0.3 ms (1-2 eye blinks) additional latency to retrieve a ticket and provide something useful to developers and users is not bad at all.
Another interesting point from this discussion is that Facebook is actually very conservative in its systems. Still, using PHP/Hack? MySQL? They create systems to last and then bolt on more and more components to improve. I guess at some critical mass all the bolted-on parts may start to fall off, but that only means it is time to rethink that system with something groundbreaking and new. So what about “Move fast and break things?” Does it contradict some of that conservativism? Or does it augment it? I think that latter — if something needs to change/improve, then just add another part somewhere to make this happen.
3) Stronger consistency than RYW? The paper says that FlightTracker can be used to improve the consistency beyond RYW. The authors provide a few examples of systems manipulating the tokens to get more benefits — indexes and pub-sub systems. With indexes, they actually bolt-on yet another component to make them work.
4) Cost of tickets. Since each ticket represents a set of recent writes, its cost is not static and depends on the number of writes done by the user session in the past 60 seconds. The main reason the cost of storing and transferring tickets does not explode is the 60-second global compaction, allowing to keep an average ticket size at 250 bytes. The median ticket size is 0 bytes, meaning that a lot of requests happen 60 seconds after users the last write. However, we do not think that a system like this will scale to a more write-heavy workload. TAO’s workload (at least in 2013 when the original paper came out) is 99.8% reads, so write are rare. With more writes, a constant-size ticket may start to make more sense, and we have a feeling that the cross-scope compaction when writes on a ticket are replaced with a more comprehensive/encompassing progress marker.
5) Cross-datacenter issues. One of the reasons for implementing FlightTracker was the fault tolerance, as the prior RYW approach that relied on write-through caches could not handle some failures that require changes in the write’s route through the caches to the storage. With FlightTracker, any TAO datacenter/cluster can serve reads while enforcing the RYW. This enables, in some rare cases, to even do reads from another datacenter if the local cluster is not available. However, it appears that the users are still sticky to the datacenter, as FlightTrakcer service lives independently on each datacenter. This means that a user’s request must come to the datacenter, retrieve the ticket, and only then it can cross the datacenter boundaries if there is a big outage locally. If the outage is so severe that the user cannot even reach its datacenter, then its request won’t get the ticket and may actually experience an RYW violation. Another nice Facebook paper talks in more detail about what happens to user requests before they reach datacenters.