In the last reading group meeting, we discussed MongoDB‘s replication protocol, as described in the “Fault-Tolerant Replication with Pull-Based Consensus in MongoDB” NSDI’21 paper. Our reading group has a few regular members from MongoDB, and this time around, Siyuan Zhou, one of the paper authors, attended the discussion, so we had a perfect opportunity to ask questions and get answers from people directly involved.
Historically, MongoDB had a primary backup replication scheme, which worked fine most of the time, but had a few unresolved corner-cases, such as having more than one active primary at a time due to the failures and primary churn. Having a split-brain in systems is never a good idea, so engineers looked for a better solution. Luckily, there are many solutions for this problem — an entire family of consensus-based replication protocols, like Multi-Paxos and Raft. MongoDB adopted the latter protocol to drive MongoDB’s update replication scheme.
At this time, I might have finished the summary, congratulated MongoDB on using Raft, and moved on. After all, Raft is a very well-known protocol, and using it poses very few surprises. However, Mongo DB had a couple of twists in their requirements that prevent using vanilla Raft. See, the original MongoDB primary backup scheme had a pull-based replication approach. Usually, the primary node (i.e., the leader) is active and directly prescribes operations/commands to the followers. This active-leader replication happens in traditional primary backup, in Multi-Paxos, Raft, and pretty much any other replication protocol aside from pub-sub systems that rely on subscribers pulling the data. In MongoDB, the primary is passive, and followers must request the data at some repeated intervals. In the figure below, I illustrate the difference between the push-based (active leader) and pull-based (active follower) approaches.
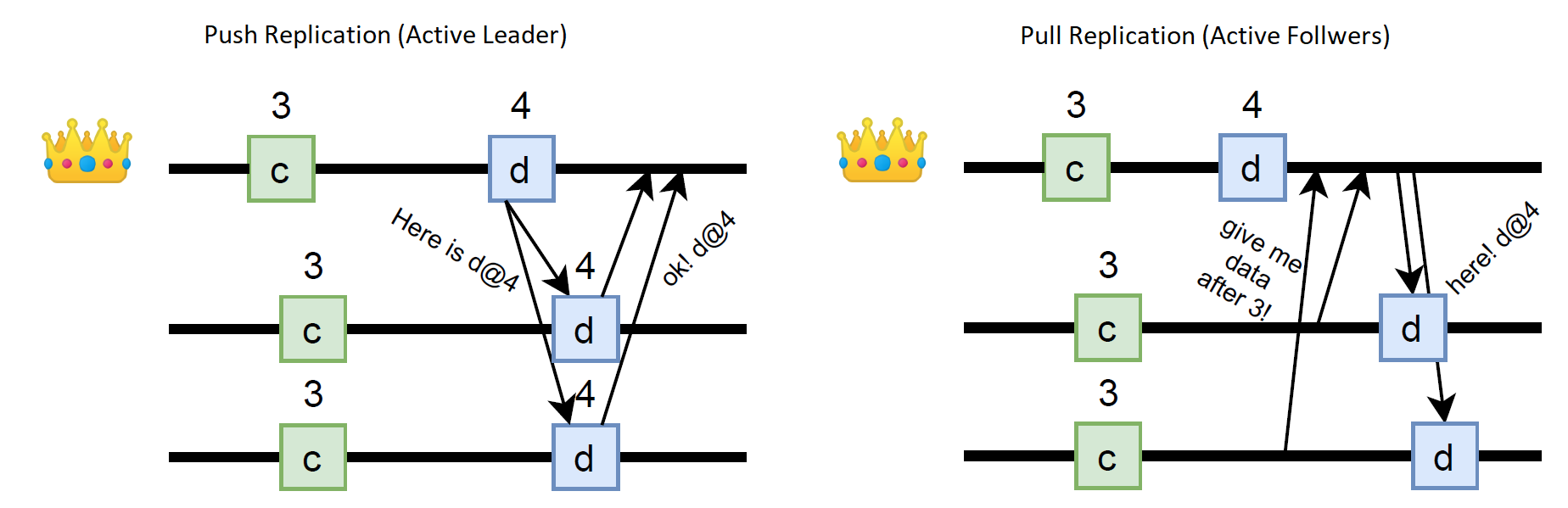
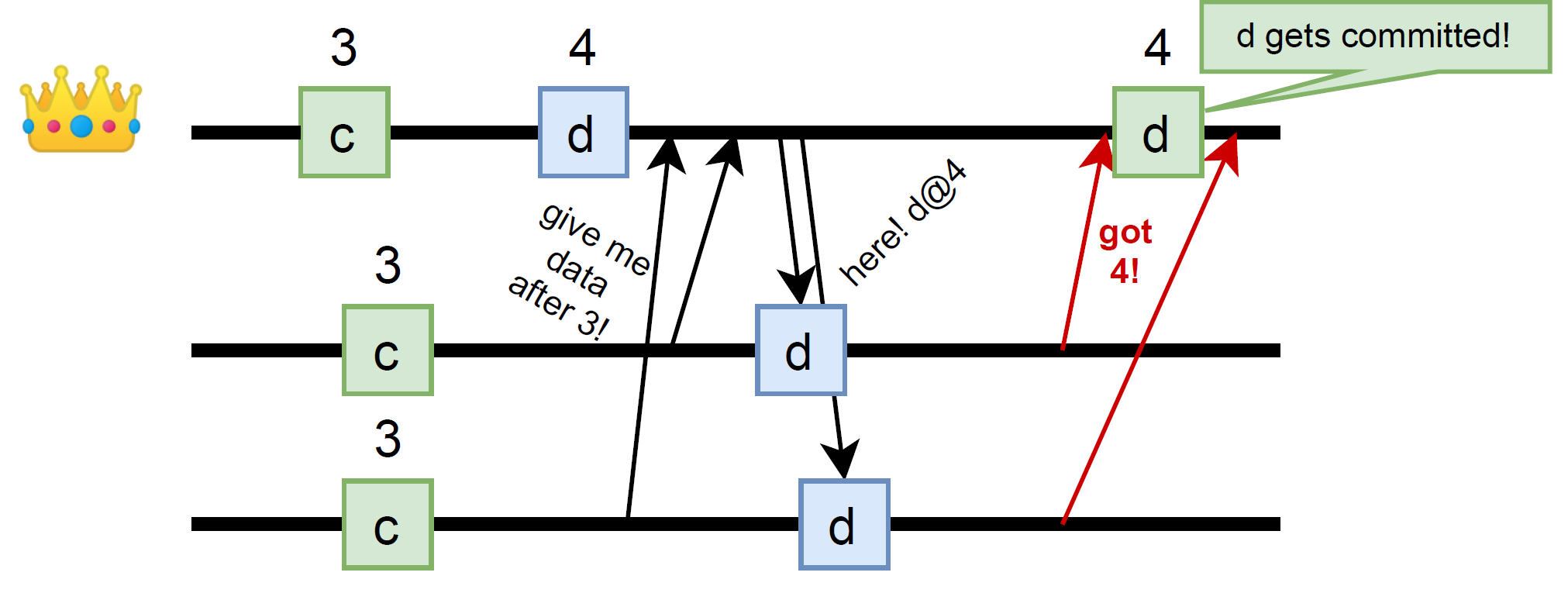
In both cases, the followers can learn new data from the leader. The pull-based approach, however, requires a bit more work. The leader has to compute the data batch for each follower individually, because followers may all have slightly different progress due to the differences in polling schedule. Also, there is another problem with the pull solution: the primary has no way of knowing whether the followers have received the operations during the pull. And this is important since the primary needs to count replicas accepting each operation to figure out the quorum and ultimately commit the operations. In traditional Raft, the result of AppendEntry RPC carries an ack for a successful operation, allowing the primary to count successful nodes and figure out when the quorum is satisfied. With flipped pull-style communication, there is no reply to the primary, and so we need to add some additional mechanism to propagate this information, as shown in the figure here. Adding more communication is costly, but the extra message can be piggybacked into the consecutive pull request at the expense of latency.
Now let’s diverge a bit and discuss why MongoDB picked a pull-based approach despite added complexity/cost. The traditional Pull-based solutions are centered around the primary or leader node, creating a star topology. In fact, unless you use something like Pig primitive from our PigPaxos paper, star topology is pretty much all you can have. This is not very good in some scenarios where links may be congested or cost a lot of money. Consider a WAN scenario where two nodes may exist in another region for geo-redundancy to minimize data loss in the event of regional failure. With star topology, the same payload will travel across WAN twice to each of the two replicas, consequently costing twice as much to replicate. With a pull-based approach, it is easier to orchestrate other replication topologies. All we have to do is to instruct one node to pull data from its regional peer instead of the leader across WAN. Naturally, this creates a longer replication chain but saves the WAN link bandwidth, cost, and potentially some resources at the primary.
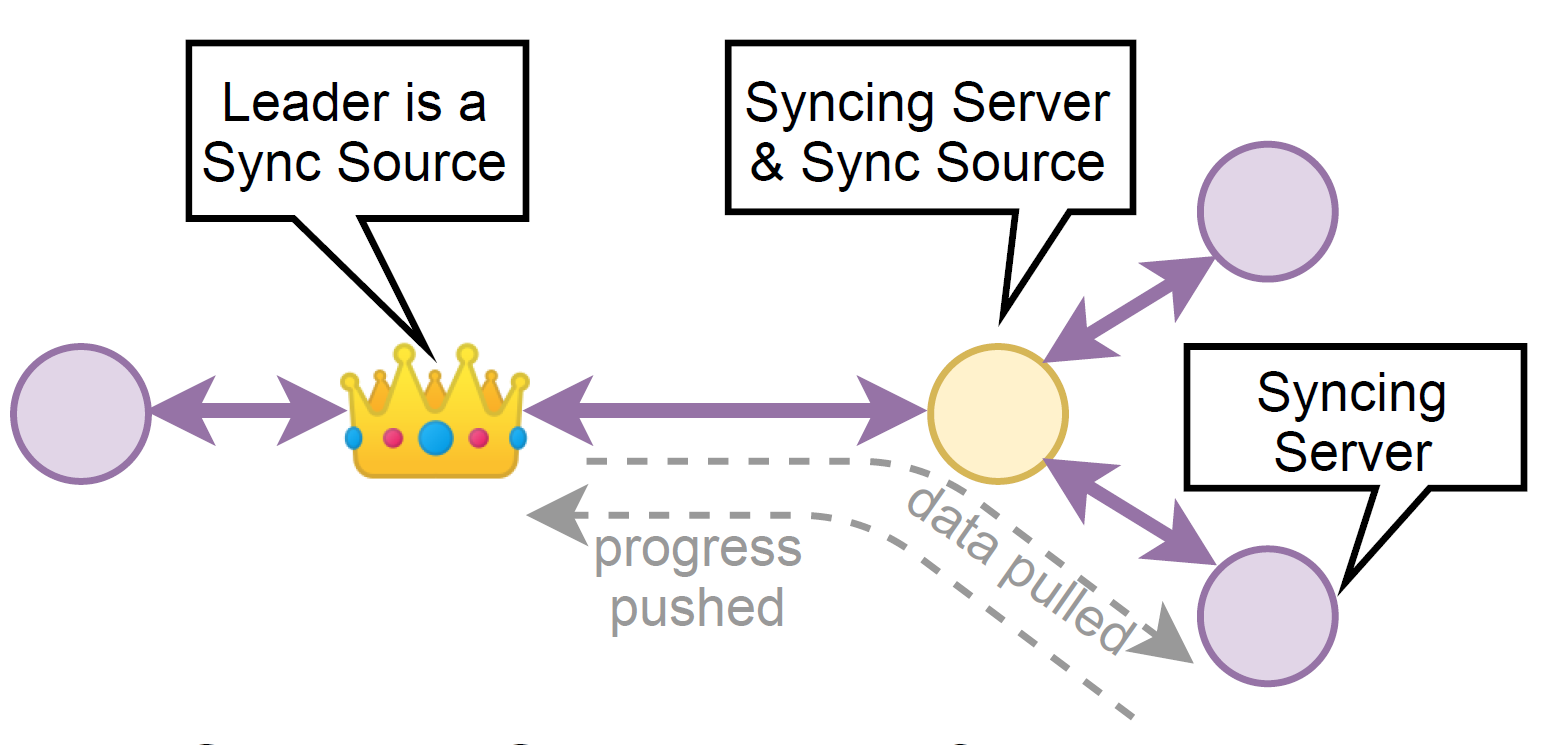
MongoDB’s pull-based solution enables such chaining by allowing some non-primary nodes to act as sync sources. Sync source is a node that provides data to syncing servers in response to a pull request. Of course, the primary is always a sync source. The high-level overview of node interactions is a follow:
- Syncing server asks for new log entries from its sync source.
- Sync source replies with a sequence of log entries.
- Syncing server appends the log items if items follow the same history.
- If source and server logs diverge, the syncing server may have uncommitted data and must clean the divergent suffix. The detection of log divergence is based on matching the last log entry of syncing server with the first entry of the log segment sent by the source. If they match, then the source has sent a continuation of the same history.
- Syncing server notifies its sync source of how up-to-date it is, including syncing server’s term.
Unlike vanilla raft, the syncing server does not check the term of the source, so it may be possible for a server to accept log entries from a source in some previous term. Of course, this can only happen if the log entries follow the same history. I think MongoDB Raft does so to make sure that the syncing server learns about legit updates from the previous leader even if it has already participated in the new leader’s election round. What is important here, is that the syncing server sends its higher term back to the source (which should propagate to the source’s source, etc, until it reaches the leader for the source’s term). These term messages act as a rejection for the old leader, so it won’t count the syncing server as accepting the message and being a part of the quorum. As a result, if the data from the old-termed sync source was committed, the syncing server has received it and will eventually receive the commit notification from the new leader. If that data is uncommitted by the old leader (i.e., a split-brain situation), then no harm is done since the syncing server does not contribute to the quorum. The syncing server will eventually learn of proper operations instead.
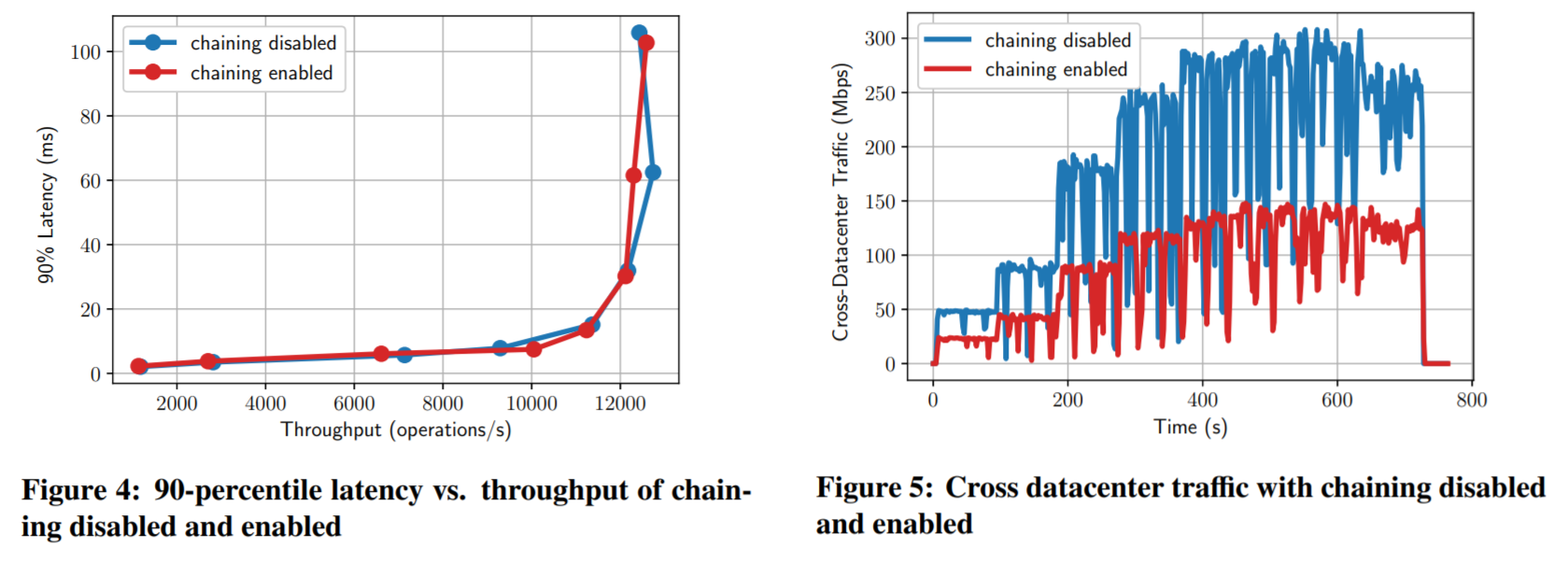
Now speaking of performance, the paper does not provide any comparison between push- and pull-based solutions, so we are left wondering about the impact of such drastic change. However, some experiments illustrate the comparison of star topology and chained replication in a 2-regions WAN setup. While chaining does not seem to increase the performance (unless the cross-region bandwidth is severely restricted), it predictably lowers the WAN bandwidth requirements. As far as maximum performance, the paper mentions that the limiting factor is handling client requests and not replication, and this is why one fewer server pulling from the leader does not impact throughput. I am not sure I am very comfortable with this explanation, to be honest.
The paper talks about a handful of other optimizations. I will mention just one that seemed the most interesting — speculative execution. With speculative execution, the nodes do not wait for a commitment notification to apply an operation, and speculatively apply it to the store right away. Since the underlying storage engine is multi-version, the system can still return strongly consistent reads by keeping track of the latest committed version. The multi-version store also allows rollbacks in case some operation fails to commit.
You can see my presentation of the paper on YouTube:
Discussion
1) Cost of pull-based replication. The performance cost of the pull-based solutions was the first big discussion topic that I raised in my presentation. As I mentioned, there is an extra communication step needed to allow the primary to learn of quorum acceptance. This step either adds additional message round/RPC call or adds latency if piggybacked to the next pull request. Another concern is pulling data when there is no new data, as this will be wasted communication cycles.
Luckily, we had MongoDB people, including Siyuan Zhou, one of the paper authors, to shed some light on this. To make things a little better and not waste the communication cycles, the pulls have a rather long “shelf life” — if the source has no data to ship, it will hold on to the pull request for up to 5 seconds before replying with a blank batch.
Another big optimization in the MongoDB system is a gradual shift to the push-based style! This somewhat makes the entire premise of the paper obsolete, however, this new “push-style” replication is still initiated by the syncing server with a pull, but after the initial pull, the source can push the data to the syncing server as it becomes available. So this allows building these complicated replication topologies while reducing the latency impact of a purely pull-based solution.
Another aspect of cost is the monetary cost, and this is where chained replication topologies can help a lot. Apparently, this was a big ask from clients initially and shaped a lot of the system architecture.
2) Evolution vs Revolution. So, since the original unproven replication approach was pull-based to allow chained topologies, the new improved and model-checked solution had to evolve from the original replication. One might think that it would have been easier to slap a regular push-based Raft, but that would have been a drastic change for all other components (not to mention the features). This would have required a lot more engineering effort than trying to reuse as much of the existing code as possible. This brings an interesting point on how production software gradually evolves and almost never drastically revolves.
3) Evaluation. The evaluation is the biggest problem of the paper. It lacks any comparison with other replication approaches except old MongoDB’s primary backup scheme. This makes it hard to judge the impacts of the changes. Of course, as we have seen from the discussion with the authors, the actual implementation is even more complicated and evolved. It tries to bridge the gap between pull and push replication styles, so a clear comparison based on MongoDB’s implementation may not have been possible at all.
That being said, I had some questions even about the provided self-comparisons. See, I would have expected to see a bit of throughput increase from chaining, similar to what I observe in PigPaxos, but there is none. The paper explains it by saying that replication at the sync source takes only 5% of a single core per syncing server, which would amount to just 20% of a core in star topology leader. Roughly, given the VMs used, this is around 5% of the total CPU used on replication, with the paper claiming that all remaining CPU is used to handle client requests. Assuming there is sync every 2 ms, we have about 2000 syncs per second at the leader for 12000 client requests. Doing some napkin math, we can see that there are 6 times more requests than replications per second, yet requests use 19 times the CPU, making each request roughly 3 times more expensive than each replication. Given that replication messages are not super cheap and require querying the log, and serializing the data, the performance cost difference sounds excessive to me, despite considering that client requests have a few writes in them (i.e., write to the log, and operation execution).
Siyuan explained that there is a bit more work on the request path as well. Not only the log is written (and persisted for durability), but there are also some additional writes for session maintenance and indexes. Moreover, the writes in the underlying WiredTiger engine are transactional, costing some performance as well.
4) PigPaxos? Throwing this out here, but there are push-based solutions that can have more interesting replication topologies than a star. Our PigPaxos, in fact, solves a similar issue of cross-regional replication at a low network cost.
5) Other pull-based systems. Finally, we try to look at other solutions that may use pull-based replication, but there are not many. Pub-Sub systems fit the pull model naturally as subscribers consume the data by pulling it from the queue/log/topic. Pull-based replication can be handy in disaster recovery when nodes try to catch up to the current state and must ask for updates/changes starting some cursor or point in history.
6) Reliability/Safety. As the protocol makes one important change of not rejecting the data from the old-termed source, it is important to look at the safety of this change. The paper claims to model the protocol with TLA+ and model checking it. Intuitively, however, we know that even though the node takes the data from the old source, it actively rejects it by sending its higher term. This, intuitively, should be enough to ensure that the old leader does not reach a quorum of accepts (even though there can be a majority of nodes that copied the data) and does not reply to a client of commitment. The rest is taken care of by Raft’s commit procedure upon the term change.