85th DistSys reading group meeting discussed “Exploiting Nil-Externality for Fast Replicated Storage” SOSP’21 paper by Aishwarya Ganesan, Ramnatthan Alagappan, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. The paper uses an old trick of delaying the execution of some operations to improve the throughput while maintaining strong consistency. Consistency is an externally-observable property, and simple strategies, like batching, can improve the throughput by making all concurrent operations wait a bit and replicate/execute in bulk. Some other solutions may delay some operations in favor of others when conflicts arise. For instance, the PQR approach may delay reads to allow writes to finish first. This paper takes the “delay-some-reads” mechanism one step further to enable clients to directly replicate certain writes/updates to the nodes in the cluster for 1 RTT client observable latency. At the same time, the leader orders the operations in the background and potentially delays reads for objects that have pending un-ordered, un-executed writes.
A core observation of the paper is that not all operations expose the system’s state upon acking their completion back to the clients. For example, a simple insert or replace command may only acknowledge its success without exposing any state. This behavior is normal, even expected, since we know what state a system should assume (at least for that particular object) after a successful write. The paper calls these operations nil-external. Since the nil-external command does not return any state, we do not really need to execute it right away, at least not on a critical path, as long as we can ensure that the command won’t be somehow forgotten after acking success to the client. The authors claim that nil-external operations are common in many production-grade systems, presenting an opportunity for improvement.
Skyros, the system presented in the paper, breaks down replication and execution of nil-external commands. The clients write their nil-external operations directly to the replicas, with each replica placing the command in the pending log, called d-log. Obviously, different nodes may have the same operation in different slots in the d-log due to races with other concurrent clients. From the client’s perspective, once a super-majority of replicas, including a leader replica, has acked the command to the client, it can consider the nil-external operation completed. This is because the operation is replicated and won’t get lost even under failures. However, the command has not been executed yet; moreover, its execution order has not been set either.
In the “happy case,” the command order mismatch in d-logs between replicas is irrelevant. Skyros is a leader-based protocol, and the leader periodically tells the followers to commit the commands from d-log to a commit log, or c-log, in the leader’s order. This part of the protocol looks like a Multi-Paxos or Raft, with the leader essentially replicating only the order of operations and not the operations themselves. Upon committing to c-log, the nodes remove the commands from d-log. This process is illustrated in the figure, which I compiled/borrowed from the author’s presentation of the paper.

However, when a leader fails, then the system has no authority to order the operations from the d-log. Intuitively, before the leader’s failure, the leader was the only node to receive all client requests. Moreover, the quorum requirement guarantees the leader to receive each request before the operation is acked on the client-side. After the system picks a new leader, it needs to establish the order of d-log operations to commit, but it is not safe to go with the order the new leader has. The reason is that we have no guarantee that all the commands in the new leader’s d-log have been added there before the operation was acked on the client. Here is an example, let’s say some operation “a” has reached a leader and 3 other nodes in a 5 nodes cluster. The client will consider this operation completed. Now consider another client starting a new operation “b” after “a” has been successfully acked. The operation “b” gets to a leader and 3 other nodes, however, it is possible that a set “3 other nodes” for “b” is not the same as it was for “a.” There can be a node that participated in the quorum for “b,” but not in the quorum for “a.” So the leader (and other nodes in the intersection of quorums for “a” and “b”) will see the order as “a, b”, while the node excluded from quorum “a” may see the order as “b, a” if somehow message “a” was delayed long enough. So now, if a leader failed, and the node with “b, a” d-log gets elected as the leader, it will commit the order that does not respect the real-time order of operations, violating linearizability.
Naturally, to be safe, Skyros needs to recover the real-time ordering. This is the reason for having a larger “supermajority” quorum. This trick has been pulled from Fast Paxos in several papers/protocols. Essentially, the supermajority quorum allows Skyros to recover the partial order of commands that have a happens-before relationship by simply looking at the majority of nodes in the majority quorum used for recovery. This majority of majority setup (i.e., 2 nodes out 3 nodes majority in a 5 nodes cluster) will have correct hb relations because of the quorum intersections. So, if “a” happened-before “b”, then this partial order will be captured in at least 2 nodes in any 3 nodes majority quorum in 5 nodes setup.
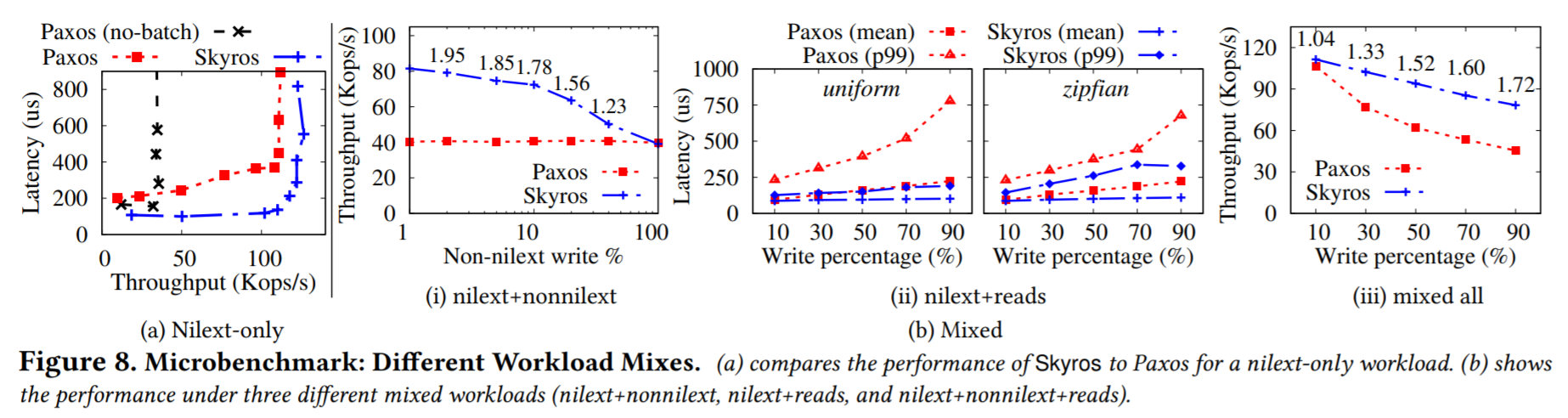
The evaluation is a bit tricky here. When testing with all nil-ext operations, Skyros beats MultiPaxos by a wide margin both in terms of latency and throughput (left-most figure). However, such workload consists of only writes/updates, so it is not very realistic. Adding some nonnil-ext operations to the mix changes things a bit (second from the left), with Skyros degrading down to Paxos performance when all operations are nonnil-ext. Also interesting to note is that this comparison does not really agree with the nilext-only experiment. See, there batched Paxos was operating at a maximum throughput of over 100k Ops/s, but in the nonnilext experiment, it is doing only 40k Ops/s, allowing authors to claim 2x throughput advantage of Skyros. I have a feeling that this experiment was done at some fixed number of clients, and with Skyros having lower nil-ext write latency, the same number of clients can potentially push more operations. Three right-most figures show the performance with reads added to the mix.
As usual, we had a presentation in out group:
Discussion
1) Five nodes. The system is described with a 5-nodes example. It makes sense when we need a supermajority quorum. Three nodes clusters are common and tend to provide better performance for MultiPaxos/Raft systems. However, three nodes setup will require a quorum of all nodes as a supermajority, making the system non-tolerant to any machine slowdowns.
2) Failures? When one node fails, this is not a bit problem. A follower failure is masked by the quorum, and the leader failure will require a new leader election, however, the cluster can continue fine after with just four nodes. Two nodes out of five failings will prevent any supermajority, so the system needs to have a mechanism to detect this efficiently and fall back to regular Multi-Paxos. Timeouts on every operation before fall-back is not a performant option, and without this discussed, the protocol hardly tolerates f nodes failing out of 2f+1 nodes cluster.
3) Orchestrating an overload? The read operations have the potential to cause foreground synchronization when a read tries to access an object with an operation still in the d-log. This means that a workload that writes and immediately reads the same object can cause too many of these transitions to the “foreground.” These explicit syncs not only impact the latency of the reads but is also likely to reduce the ordering batches and cost more processing resources, reducing the system’s maximum capacity. So, by a simple workload, it may be possible to overload the system possible into a failure.