On Wednesday, we had our 26th reading group meeting, discussing RocksDB with a help of a recent experience paper: “Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience.” Single-server key-value storage systems are crucial for so many distributed systems and databases. For distributed folks like myself, these often remain black-boxes that you pick up and use. That is until something in your system starts to crumble peculiarly, and you dive in to investigate…
Anyway, what I want to say is that KV-stores are important. Their performance matters a lot in the world of fast CPUs and fast networks, where every millisecond of slowdown at storage can no longer be “masked” by other “slow” components. This is where this paper takes us — improving the performance, reliability, and feature-set of RocksDB over the years as technology and demands have evolved.
To understand the experiences and lessons of the paper, we first need to look at the underlying technology behind RocksDB. In a nutshell, RocksDB is an LSM-tree (Log-Structured Merge tree) key-value storage. LSM trees have been used in storage for quite some time, as they are relay good for write-intensive workloads. The basic idea of the LSM tree is that data are stored sorted by key. These sorted files are called sorted-strings tables or SSTables for short.

Now, maintaining SSTables requires that data are written to storage sequentially in such a sorted state. Of course, the data does not come pre-sorted to a database, so the system needs to do something else before writing these sorted files to disk. The storage system will keep an in-memory buffer, called memtable, of some relatively large number of updates. This memtable can be represented as some tree structure to allow for efficient insertions. Before each operation is added to a memtable, it is written to a write-ahead-log (WAL) for durability. The WAL reconstructs a memtable in the event of a failure. Once memtable reaches a certain size, it is flushed to disk in a sorted manner. At this time a new empty memtable can start. An important aspect of writing these sorted files is keeping track of their recency order.
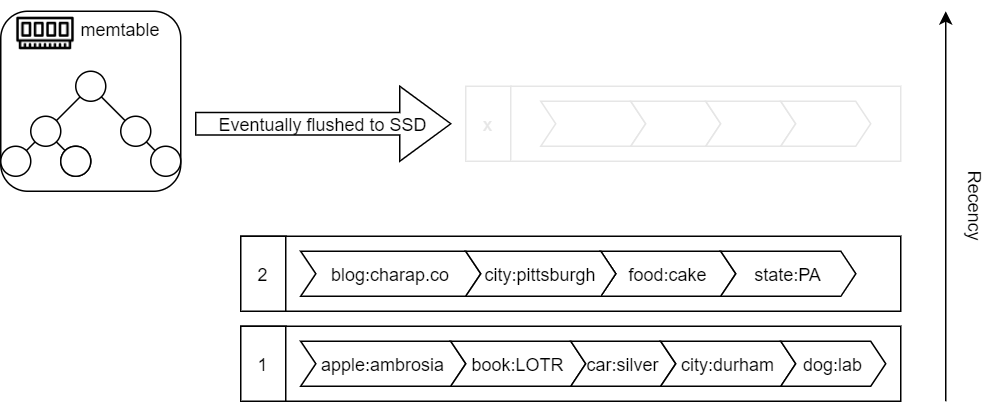
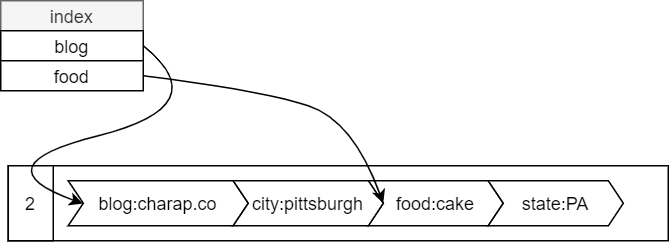
When a read request for a key arrives, the system first looks at the memtable to see if data is there. Memory lookup is relatively cheap since no disk access is needed. However, if the requested key is not in the memtable, then we must search on disk, starting from the most recent SSTable segment. Looking up data on a disk can be slow since the system needs to scan a good chunk of a file to find the spot where the key might exist in the sorted list. Naturally, we want to take advantage of the sorted nature of the file. For this, a system maintains a sparse index for each file with the offsets to narrow down the search. Then the system only needs to scan a portion of a file between the two offsets where the key may exist. If the data is missing in the most recent file, then a search continues in the next most recent one and so on. This process results in some peculiar behaviors. For instance, it generally takes less time to find more frequently used data. But it also takes a lot of time to find out that the data is missing entirely. Fishing for non-existent data is a waste of time, so an additional index, a bloom filter, can be used to tell whether the key is guaranteed to be missing.
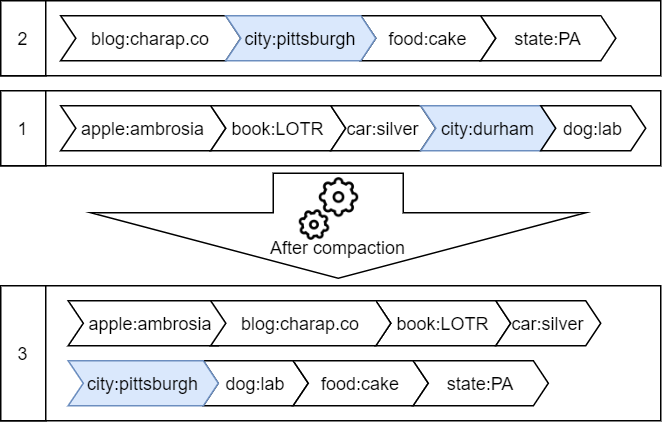
Another caveat the sequential writes create for us is dealing with old versions of data. See, when we write an SSTable to disk, it is immutable, and when an update or delete to a key comes in, this update will eventually flush to a more recent file. This influx of new data creates a situation where old data that is no longer needed keeps occupying space and potentially increases search time. So the system needs to clean up old data frequently. A compaction procedure mitigates the space amplification by cleaning up old data. It essentially takes multiple files and merges them into one bigger file.
So, my oversimplified descriptions of LSM storage is not necessarily how RocksDB operates, but it should give enough intuition for us to proceed and dive into the lessons and experiences of Facebook engineers working with RocksDB.
Resources: IOPS vs Space vs CPU
The paper starts by exploring resource efficiency and how optimization priorities were changing over time. RocksDB runs best on SSDs, and these storage devices have a limited lifespan bound by the number of write cycles. Naturally, engineers focused on issues of write amplification (the same data rewritten multiple times) to make sure SSDs do not die prematurely. Interestingly enough, the paper almost makes it sound like write-amplification mitigation efforts were largely wasted. The authors state that the workloads used at Facebook are not too IOPS-heavy (does it meant they are not very write-heavy for write-optimized storage?), and storage space was a more pressing concern. Because of this, the engineers have shifted their efforts to the space-amplification problem (a key occupies more space than it needs to, for example, due to having multiple old versions of it).
Another issue brought up is the CPU utilization. Here, again, the paper states that CPUs are rarely a bottleneck. However, to me, it seems like these represent a delicate resource trade-off. For example, to reduce space consumption, we may need to use more aggressive compression that uses more CPU cycles and more aggressive compaction that needs both CPU and IOPs (and increases write-amplification). So I am not sure about the correctness of saying whether some resource here is a bottleneck or not. They all can be a problem, and it seems more about the ability to reach some balance for a given workload and infrastructure. I believe the need to find such balance in different applications is part of the reason behind the multiple compaction strategies mentioned in the paper.
A significant portion of the paper then focuses on dealing with resources at scale. For example, many instances of RocksDB may coexist on one server, requiring resource management to prevent one instance from hogging all the resources. Other resource-related aspects involve the treatment of write-ahead logs (WALs). For example, it is possible to completely turn off RocksDB’s internal WAL to conserve resources. Of course, this leaves the system vulnerable to data loss in the event of a crash, but this may not be a problem if an application using Rocks has its own WAL for things like transactions or replication. An interesting mention for resource management is rate-limiting file deletion. This issue seems a bit specific, but the authors explain how file deletion can be costly and impact other tenants using the same SSD.
Features
The paper also extensively talks about new features and their significance. Similar to how the authors have approached resource efficiency, these features largely stem from operating at scale. Many of the points simply make sense when I read them, but I suspect that these realizations were not as easy in practice and carry some production pain points. For example, we usually expect backward compatibility, but designing forward compatibility, where an older version should be compatible with a newer one, is definitely a result of sleepless nights after unrolling from some newer but buggy version and realizing that data files changed to the point that the old version no longer understands them.
The flexibility of RocksDB is another weaved-in theme of the paper. Since the storage system is used in a variety of applications with a variety of needs, this again makes total sense. It appears that the main goal of many features is to make the system more extensible and fit into many different contexts without creating any roadblocks on purpose. One such example is improvements to configuration management that went from “in-code” configuration to having configuration files. However, one big configuration problem directly stems from the flexibility goal — too many different parameters to tune, and it seems like there is no good solution for this.
The paper presents a few other examples of flexibility features meant to help build apps on top of RocksDB. If implemented, native versioned storage can greatly help systems relying on multi-version concurrency control (MVCC). This, however, may come with a performance penalty. At the same time, MVCC systems have already been relying on RocksDB for storage, since the “no roadblocks” principle provides great flexibility in how keys and values are encoded, allowing versioning information to be a part of the key.
Replication and backup support got their own subsection in the papers, but this is nothing but a trivial “you can copy the files to another machine to start a new replica” approach. This is hardly a feature, but again, it plays nicely with the idea of designing a system with as few roadblocks as possible and letting users/engineers be creative with using it.
Reliability
Reliability is a big topic in the paper. We want the data stored in the database to remain correct and intact. Luckily, there is a very concise summary for this — use checksums! The authors point out that their checksum procedures only work for data already in storage and that they are still working on checking the integrity of data in memtables. This memory corruption may not be that big of a problem though. Thankfully, unlike our personal computers, servers rely on ECC memory that can handle some memory issues all by itself.
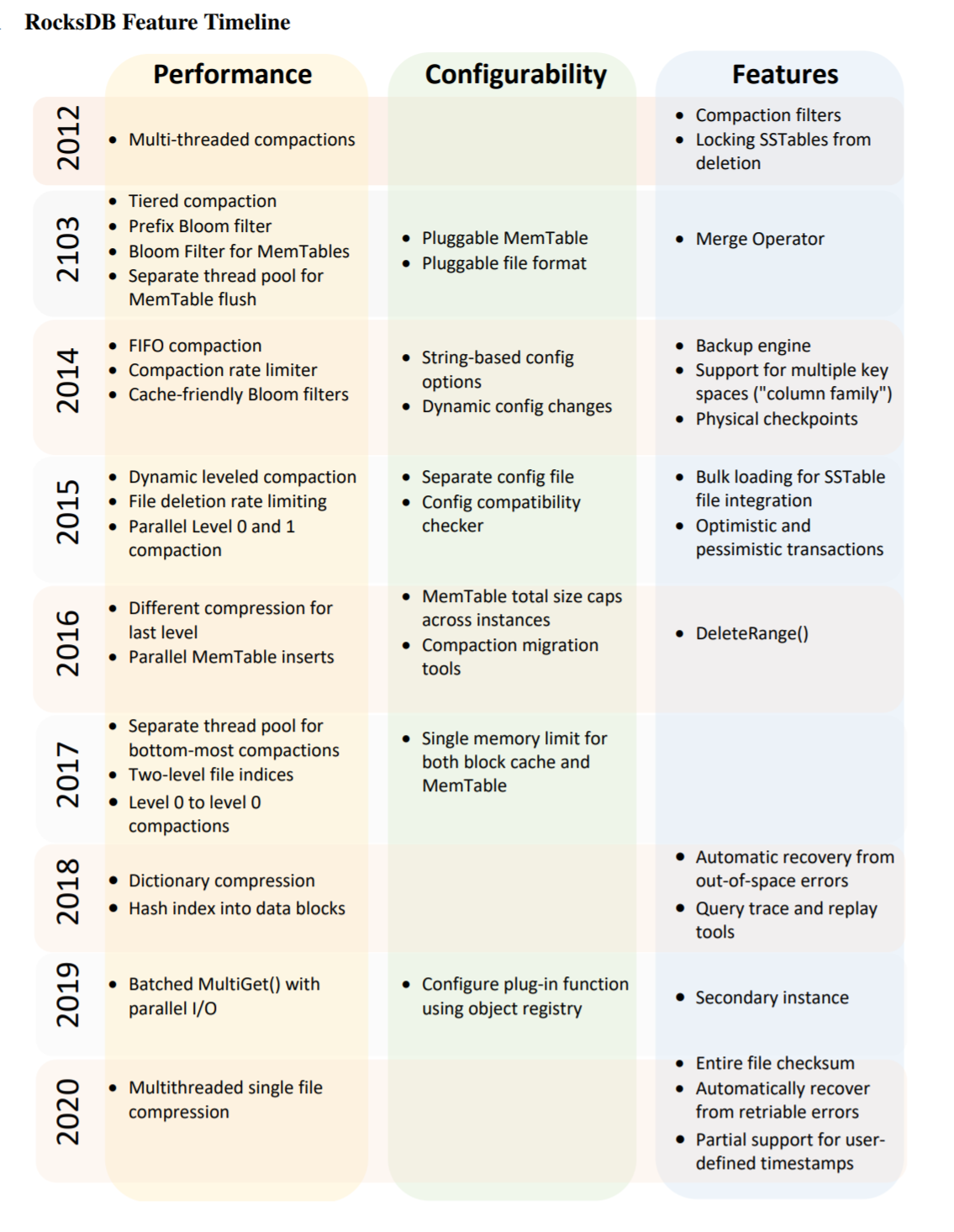
I will finish my summary with a large table of features and changes to RocksDB straight from the paper.
And as always, we have our groups presentation by Rohan Puri available on YouTube:
Discussion
We had a very long discussion after the presentation. I think it lasted almost an hour, just talking about KV-stores in general and RocksDB in particular. There is no way I can possibly summarize every discussion point, but I will try to pick the important ones (by my judgment of their importance)
1) Scratching the surface. This point started in our pre-presentation discussion. While the paper talks about many different features and issues and tries to explain the reasons for the decisions taken, some explanations barely scratch the surface. Of course, it would be rather difficult to talk about eight years of development and go into deep technical discussions. However, what interested the group the most are some rather odd talking points throughout the paper. For example, talking about rate-limiting file deletions is oddly specific. Why not have rate-limiting for all tasks that may have a high impact on IOPS? These oddly specific examples scream about rather interesting back-stories that are obviously missing from the paper.
2) Checksums. The checksum discussion was rather interesting. There are multiple layers of checksums. For example, block checksums make a lot of sense, as they are written when an SSTable block flushes to disk. One observation made in the reading group is that the file checksums were added late in the RocksDB lifecycle. A plausible explanation for this is file checksums are rarely needed, as they would come in handy when, for example, copying the entire SSTable file from one machine to another to start a new replica. And in this hopefully rare occasion, we can check the integrity of the data the long way — open the file and go block by block and check block checksums.
3) Replication. Obviously, RocksDB is a single-server system, but it serves as a store for many replicated systems. In the group, we found it interesting that the paper still talks about replication. However, the replication discussions in the paper boil down to designing the permissive systems that allow to built replicated solutions on top.
4) Too flexible? One of the bigger goals of RocksDB is its flexibility to fit into different applications with different requirements. This creates a system that has too many features, with any application only using a handful of them. However, this ability to tune and have all these features complicates the configuration and management of the system. One notable example is CockroachDB that developed its own in-house replacement for RocksDB with fewer features, and having fewer features seems to be a big bragging point for Cockroach folks.
5) Impact of Facebook hardware infrastructure. One concern raised during the discussion was the impact of hardware infrastructure at Facebook on the overall design trajectory described in the paper. Of course, it is true, that Facebook deploys RocksDB in their systems and their own infrastructure. But it also means that other non-Facebook users have to adjust to decisions made with Facebook-grade infrastructure in mind.
One such example is the write-amplification vs space-amplification discussion in the paper. While Facebook engineers have concluded that on their SSDs (and their workloads), write-amplification does not pose a serious risk of premature SSD failures, the same may not be the case for other users who may have lesser quality SSDs or more write-demanding workloads. It is a serious enough concern that authors acknowledge the existence of LSM-tree solutions with better write-amplification mitigation strategies. Moreover, at least some of these solutions have been put into production use already.