Our recent meeting focused on Blockchains, as we discussed “chainifyDB: How to get rid of your Blockchain and use your DBMS instead” CIDR’21 paper. The presentation by Karolis Petrauskas is available here:
The paper argues for using existing and proven technology to implement a permissioned blockchain-like system. The core idea is to leverage relational SQL-99 compliant DBMSes that are very common in various IT architectures. The participants in the blockchain can then leverage the existing software stack to implement secure data-sharing or replication. Moreover, the authors argue that in practice different participants may run DBMSes of different versions or even different vendors, making the problem of syncing data between participants more challenging, as different versions/vendors may execute the same SQL transactions slightly differently. To address the heterogeneity issues, the paper proposes a “Whatever-Voting” model, where the system achieves consensus on the results of a transaction, and not on the transaction itself. This allows each node/organization to run the transaction in “whatever” way possible, as long as the final result of the transaction is agreed upon by the quorum of participants in the “voting” phase. If the voting phase does not pass, the node with a mismatched result must roll the transaction back (potentially more than one) and try to recover by reapplying it. To me this seems a bit naive — if a node could not produce the proper results to a correct, non-malicious transaction due to its vendor differences or “whatever” execution differences, it may get stuck in the infinite loop of rollbacks and reapplies until whatever phase is fixed to produce the correct results for a specific transaction. This can be a very error-prone, engineering-intensive process of constant fine-tuning and micromanaging the components.
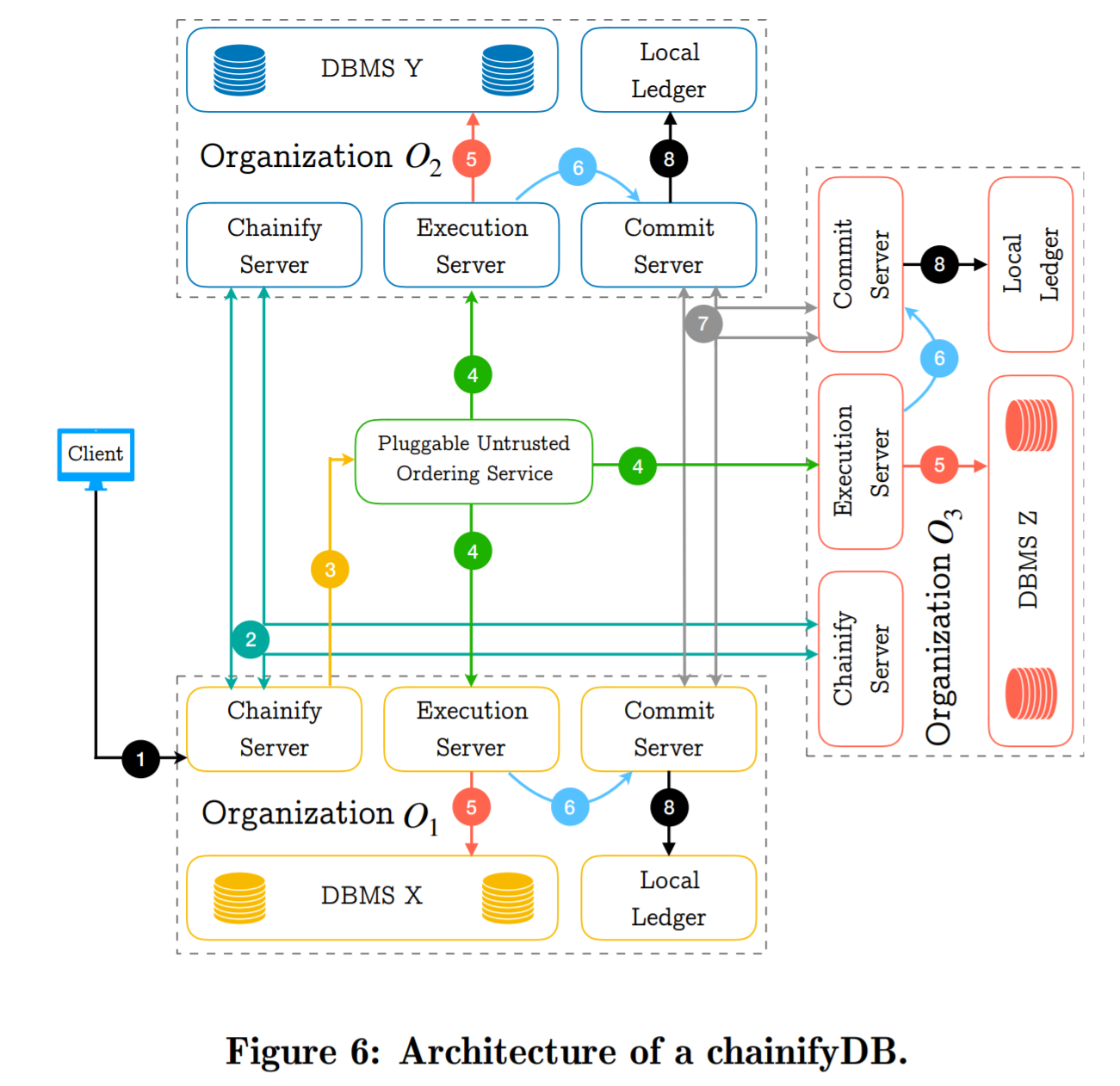
Since the proposed solution does not reach an agreement on transactions, the paper argues that it does not need complicated protocols to ensure that all correct nodes have correct transactions. If some entity issues different transactions to different participants, the results won’t match, missing the quorum agreement and causing a system-wide rollback and retry. However, the voting scheme should still be resilient to some cheating — a node must provide some proof or digest of the authenticity of its results.
The authors argue that their system does not have a centralized authority. However, it still has a centralized control component that batches the transactions and orders them. This component can be untrusted since the participants should catch mismatched batches and roll the state back as needed. That being said, a byzantine centralized batcher/sequencer (the paper calls it orderer) can cause liveness issues by sending garbage to participants causing constant recoveries. The paper does not specify the process of electing/replacing the orderer, so I think in practice it should be trusted for liveness purposes.
There is a lot more work involved to make the scheme work. For example, each node must remember the transaction batches to create the ledger. This also happens within the DBMS, and some precautions must be taken to ensure that the ledger is tamper-proof. The roll-back procedure is also complicated and must be carefully implemented to have good performance.
The authors conduct their evaluation on a limited scale with just 3 nodes/DBMS instances and show good scalability compared to Fabric and Fabric++. The evaluation focuses on increasing the number of clients interacting with the DBMSes, and not the number of DBMS instances. The paper does not mention the possibility to have Byzantine clients. Moreover, the evaluation does not consider any byzantine cases.
Discussion
1) Paper Quality. Our group’s collective opinion about the quality of the paper was not very enthusiastic. The paper’s premise is interesting and practical, however, it has way too many holes, missed promises, and unsubstantiated claims. These range from inadequate evaluation to relying on centralized unreplaceable “orderer” in a decentralized system to an underspecified voting protocol to glaring engineering holes in the “whatever” model that is prone to liveness issues due to bad implementations. There are way too many to list them all, so I will mention just one in a bit of detail.
A big undelivered promise is using the DBMSes as “black-box.” While the DBMS software does not need any modifications, the applications running on these DBMSes must be adjusted to accommodate the WV model. Although these adjustments may be relatively small (i.e. making the client talk to chainify server instead of DBMS), it appears that the “whatever” stage may need tweaks on a per transaction-type basis if the DBMSes are very different. This additional logic and tweaking is hardly a black-box approach from the application point of view. Other concerns here involve privacy. What if some tables at one organization are not supposed to be shared but transactions/queries from this same entity touch both shared and private tables? Addressing these may require even bigger application changes and rewrites. And of course, this is not to mention all the additional table chainifying introduces to the database.
2) Preventing Byzantine Behavior vs. Detecting Byzantine Behavior. An interesting point the paper raises (and I wish it was explored more) is whether we need to prevent byzantine actions from taking place or just being able to detect them. Unlike all (most?) of the blockchains, chainifyDB does not prevent bad behavior from executing, and instead, it tries to detect misbehavior and fix it by a reset and restore procedure. Is this approach cheaper on the fundamental level? What applications can it support? Obviously, chainifyDB argues that it supports the permissioned blockchains, but We’d love to see more rigor and research in that direction.
There are some potential issues with this approach, and the paper does not give many details on these. For example, a transaction may execute on all nodes and produce matching result digests for voting. However, if the transaction itself is malicious, and for instance, tries to create value or double-spend something, then the correct nodes must have a mechanism to abort such transaction before its execution (or detect and reset after?). Result voting may not sufficient here. Of course, it is possible to implement some pre-execution sanity check logic to verify that the transaction is compliant with all the rules and constraints. It appears that in chainifyDB this stage happens early and requires every participant’s vote (see Step 2 in the figure in the summary), but the paper is not very clear on the safety implication of this vote/abort decision collection. Also, what about fault tolerance if we need all nodes for this? Additionally, this, in a sense, creates some pre-execution voting that the paper claims to avoid.
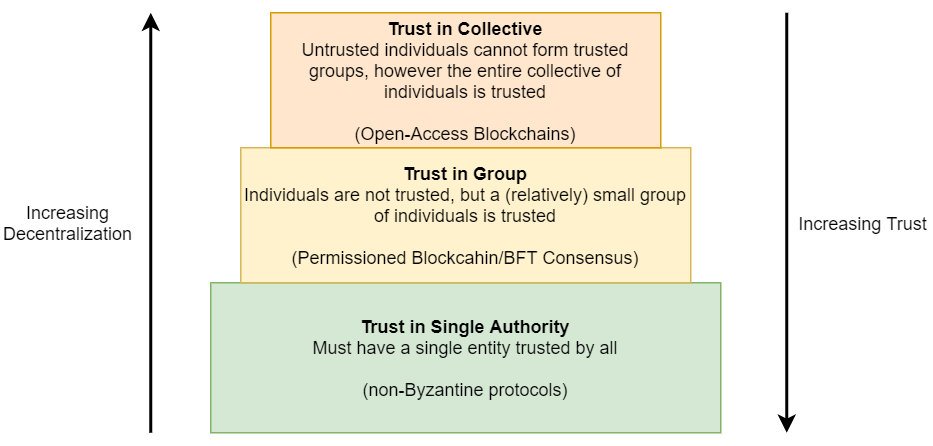
3) Issues of Trust. This is a bigger discussion on different types of storage systems and applications that need them. The most popular type of data systems is the ones with trust in a single participant/entity. This is not a problem for an in-house database for example. Many cloud data-intensive services rely on this model, where clients would trust the cloud provider and do not worry about the provider becoming malicious. This even works if the clients distrust each other, as long as they all trust the service provider. The latter is often sold as some form of a permissioned blockchain, but fundamentally it is just a database with an append-only log where safety is ultimately ensured by the trusted provider. Truly permissioned blockchains have no single trusted entity, however, a relatively small set of participants can be trusted as a group. The permissioned nature prevents Sybil attacks by spoofing many fake malicious participants to overtake the network, allowing to have small groups to be trustworthy despite having malicious individuals. Finally, open-blackchains are completely untrusted environments, where only the entire collective of all participants can be trusted. The figure here illustrates this.
One discussion question we had is when to use permissioned blockchain and why not to stick with open-access protocols instead. Of course, permissioned blockchains or BFT protocols are cheaper to run than open-access counterparts and often have better latency and higher throughput. But is it safe to have trust in a small group of participants? What applications are ok with that level of trust?