Our 89th paper in the reading group was “Basil: Breaking up BFT with ACID (transactions)” from SOSP’21 by Florian Suri-Payer, Matthew Burke, Zheng Wang, Yunhao Zhang, Lorenzo Alvisi, and Natacha Crooks. I will make this summary short. We had a quick and improvised presentation as well. Unfortunately, this time around, it was not recorded.
The system presented in the paper, called Basil, proposes a sharded BFT transactional system. Basil is leaderless too, and overall reminds me of the Tapir/Meerkat line of work turned into the BFT setting. In these systems, clients do a bulk of the work, which definitely complicates things for BFT protocols — now we no longer have “dumb” clients who can be byzantine and instead rely on smart clients who can screw stuff up quite substantially.
The paper lists a few common assumptions for their system, such as the inability of Byzantine clients to cause a denial of service attack and having some degree of fault tolerance f in each shard with a shard of 5f+1 nodes. Also important are the definitions of byzantine isolation levels. In short, the paper aims to provide serializability, but only for correct clients. So byzantine participants cannot cause the reorder of operations observed by the well-behaved clients.
As I mentioned above, the actual protocol is very similar to Tapir/Meerkat. The clients run interactive transactions by reading from the involved partitions and buffering the writes locally. Once ready to commit, the clients run a two-phase commit protocol. Just like the CFT counterparts, the transactions are timestamp-ordered by clients, so clients must have synchronized time. Since the clients pick the timestamps, a faulty client can choose one far in the future, causing other dependent transactions to abort/hang. To avoid this, Basil replicas have a window of time in which they accept transactions. Replicas reject any transaction started by the client with a timestamp that is too much off from the replica’s time.
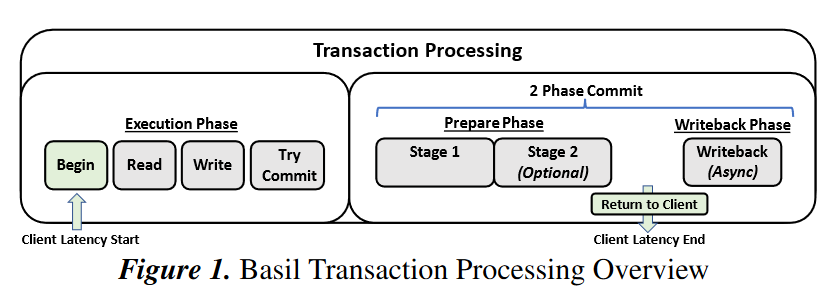
Another BFT issue that arises with running a two-phase commit is preparing a transaction with too many keys and not committing it. Similar to the timestamp problem, this can block any other dependent transactions. To mitigate the issue, the Basil protocol allows other clients to take over the stalled transactions. Such a takeover also solves client crash failure.
The version of the two-phase commit is where most of BFT magic is hiding, as this is not your vanilla 2PC. The prepare-phase consists of 2 stages: ST1 and ST2. In ST1, the protocol collects the votes to commit or abort from each shard, and in ST2, it makes such vote durable. The latter is needed if a new client coordinator needs to take over and reaches a different vote conclusion due to byzantine actors.
Again in the spirit of Tapir/Meerkat, the ST2 is optional if ST1 has completed with a fast unanimous quorum of 5f+1 nodes. The paper contains many interesting details about the stages of prepare phase. One curious part is that ST2 logs the voting results from all shards in just one shard. The aborts also have a fast and slow path, and the quorums are smaller for abort decisions than for commit.
The recovery protocol that allows other clients to take over can succeed by simply learning the decision from ST2 through the quorum of replicas in a shard that stored the vote. It is unclear what happens in the fast-path prepare that does not run ST2. However, if the votes for ST2 are divergent (which may happen due to a faulty behavior or multiple concurrent repairs), Basil falls back to a leader-based view-change protocol. And, of course, it is a bit more complicated to make it BFT.
On the evaluation side, Basil outperforms transactional BFT competitors but remains slower than the CFT counterparts. I also want to point out a low level of fault tolerance — out of six nodes in the cluster, only one node can be byzantine.
The version of the two-phase commit is where most of BFT magic is hiding, as this is not your vanilla 2PC. The prepare-phase consists of 2 stages: ST1 and ST2. In ST1, the protocol collects the votes to commit or abort from each shard, and in ST2, it makes such vote durable. The latter is needed if a new client coordinator needs to take over and reaches a different vote conclusion due to byzantine actors.
Again in the spirit of Tapir/Meerkat, the ST2 is optional if ST1 has completed with a fast unanimous quorum of 5f+1 nodes. The paper contains many interesting details about the stages of prepare phase. One curious part is that ST2 logs the voting results from all shards in just one shard. The aborts also have a fast and slow path, and the quorums are smaller for abort decisions than for commit.
The recovery protocol that allows other clients to take over can succeed by simply learning the decision from ST2 through the quorum of replicas in a shard that stored the vote. It is unclear what happens in the fast-path prepare that does not run ST2. However, if the votes for ST2 are divergent (which may happen due to a faulty behavior or multiple concurrent repairs), Basil falls back to a leader-based view-change protocol. And, of course, it is a bit more complicated to make it BFT.
On the evaluation side, Basil outperforms transactional BFT competitors but remains slower than the CFT counterparts. I also want to point out a low level of fault tolerance — out of six nodes in the cluster, only one node can be byzantine.
The version of the two-phase commit is where most of BFT magic is hiding, as this is not your vanilla 2PC. The prepare-phase consists of 2 stages: ST1 and ST2. In ST1, the protocol collects the votes to commit or abort from each shard, and in ST2, it makes such vote durable. The latter is needed if a new client coordinator needs to take over and reaches a different vote conclusion due to byzantine actors.
Again in the spirit of Tapir/Meerkat, the ST2 is optional if ST1 has completed with a fast unanimous quorum of 5f+1 nodes. The paper contains many interesting details about the stages of prepare phase. One curious part is that ST2 logs the voting results from all shards in just one shard. The aborts also have a fast and slow path, and the quorums are smaller for abort decisions than for commit.
The recovery protocol that allows other clients to take over can succeed by simply learning the decision from ST2 through the quorum of replicas in a shard that stored the vote. It is unclear what happens in the fast-path prepare that does not run ST2. However, if the votes for ST2 are divergent (which may happen due to a faulty behavior or multiple concurrent repairs), Basil falls back to a leader-based view-change protocol. And, of course, it is a bit more complicated to make it BFT.
On the evaluation side, Basil outperforms transactional BFT competitors but remains slower than the CFT counterparts. I also want to point out a low level of fault tolerance — out of six nodes in the cluster, only one node can be byzantine.
Discussion
1) Low fault-tolerance. Requiring six nodes to tolerate one failure (5f+1 configuration) is a rather fault-tolerance threshold. To double the fault tolerance, we need 11 replicas! For comparison, the HotStuff protocol, which authors use as a baseline, needs a cluster of size 3f+1. Requiring more nodes also raise some questions about efficiency — while the performance is good, the protocol also needs more resource to achieve it.
2) More fault-tolerance? In a few places in the paper, it is mentioned that up to f votes can be missed due to asynchrony, and another f due to byzantine behavior: “A unanimous vote ensures that, since correct replicas never change their vote, any client C′ that were to step in for C would be guaranteed to observe at least a Commit Quorum of 3f + 1 Commit votes; C′ may miss at most f votes because of asynchrony, and at most f more may come from equivocating Byzantine replicas.” This suggests that the practical fault tolerance may be better than just f.
3) Unanimous fast quorum. The unanimous fast quorum is another potential problem for performance when things are not going well. The sole faulty client will throw the protocol off the fast-path prepares, requiring more resources to prepare each transaction. Not to mention, waiting for a timeout on a faulty replica does not improve the latency.
4) Questions about recovery. We had some questions about the recovery procedure. It seems like the first step is to try to recover by reading the recorded prepare vote, and if everything is good, simply finish the commit for the transaction. However, it appears that durably recording votes in one place is an optional stage: “If some shards are in the slow set, however, C needs to take an additional step to make its tentative 2PC decision durable in a second phase (ST2).” As a result, under normal conditions, there may not be votes from ST2 to recover from one shard/partition. Does the recovering client then need to contact all partitions of a transaction?