In our 33rd reading group meeting, we discussed “Aria: A Fast and Practical Deterministic OLTP Database.” by Yi Lu, Xiangyao Yu, Lei Cao, Samuel Madden. We had a very nice presentation by Alex Miller:
Quick Summary
Aria is a transaction protocol, heavily influenced by Calvin, and it largely adopts Calvin’s transaction model, with one big difference. In Calvin, read and write sets of a transaction must be known beforehand, but Aria has no such strict requirement, allowing for generally more flexible transactions. Aria’s main goal is parallelizing transactions as much as possible to maximize the throughput. To that extent, Aria adopts batching and processes multiple transactions in each batch concurrently.
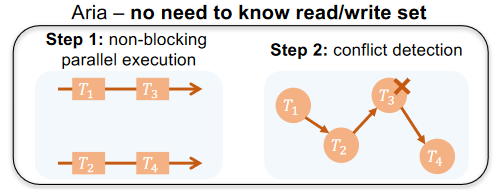 Each batch operates in two phases: execution and commit. All transactions in a batch start the execution phase from the same snapshot (the result of committing and applying the previous batch). In the execution phase, each transaction concurrently executes and produces the new state, which is stored temporarily. Once all transactions in a batch have finished executing, the protocol moves into the commit phase, where Aria aborts any transaction that has a Write-after-Write(WAW) conflict or Read-after-Write(RAW) conflict. Aria uses unique and sortable transaction IDs to determine the order of transactions within the batch to find these conflicts. Any aborted transaction goes to the future batch, while the remaining successful transactions commit and apply their temporary execution results. Once the commit has finished, a new batch can start, and the protocol keeps moving in these lock-steps, synchronizing after each step. Every replica can run the protocol without synchronizing/communicating with other replicas unless the system is sharded/partitioned and one replica need to read data from another shard. An important optimization of Aria is deterministic reordering, where transactions within a batch can be reordered (i.e. not follow the order of their TIDs) to reduce the number of aborts, and consequently, reduce the amount of wasted work in the execution phase.
Each batch operates in two phases: execution and commit. All transactions in a batch start the execution phase from the same snapshot (the result of committing and applying the previous batch). In the execution phase, each transaction concurrently executes and produces the new state, which is stored temporarily. Once all transactions in a batch have finished executing, the protocol moves into the commit phase, where Aria aborts any transaction that has a Write-after-Write(WAW) conflict or Read-after-Write(RAW) conflict. Aria uses unique and sortable transaction IDs to determine the order of transactions within the batch to find these conflicts. Any aborted transaction goes to the future batch, while the remaining successful transactions commit and apply their temporary execution results. Once the commit has finished, a new batch can start, and the protocol keeps moving in these lock-steps, synchronizing after each step. Every replica can run the protocol without synchronizing/communicating with other replicas unless the system is sharded/partitioned and one replica need to read data from another shard. An important optimization of Aria is deterministic reordering, where transactions within a batch can be reordered (i.e. not follow the order of their TIDs) to reduce the number of aborts, and consequently, reduce the amount of wasted work in the execution phase.
Discussion Points
We had good participation and touched on quite a few things in the discussion, but to the credit of the paper, we were able to find lots of answers there just by reading more carefully.
1) Transaction Serializability. Paper claims serializability, but it applies a bunch of transactions to the same snapshot. How does it compare to snapshot isolation? and what is the difference that allows serializability?
We think the batch processing and addition of RAW conflict within the batch makes a difference. Snapshot Isolation checks for WAW conflicts only and allows some artifacts. By also disallowing RAW conflicts, we can eliminate the problem. However, there are nuances with how a read set can be defined for conflict resolution. For example, What is a read set in a transaction running UPDATE items SET x=0 WHERE x=1? It can be either all items, or only items with x=1 if some indexing is used, and this difference may result in serializability issues. For the paper’s defense, it does not explicitly consider a SQL model, and also mentions that things like the above are up to the users to decide, and a fall-back to Calvin-like approach.
2) Batch size. This is a batched protocol, so the batch size may play a role in the performance. Batches that are too small will have more frequent barriers between batches and phases. Batches that are too large have a higher chance of having a super long transaction that stalls the entire batch, impacting the performance. The paper mentions that the transactions should take about the same time to execute for best performance to avoid the case when one slow transaction stalls the entire batch.
3) Paper readability. The overall consensus in the group was that this was one of the easier transaction appears to read.
4) Comparison with other transaction systems. SLOG paper we discussed a few months ago also uses determinism on each node to run transactions. Unlike Aria though, SLOG uses determinism for execution order, while Aria executes unordered (from the same state) and deterministically aborts the conflicting transactions. Overall it seems that Aria’s use of determinism is more extensive – the same snapshot, transactions are deterministic themselves, deterministic conflict search and abort, etc.
There was also a mention of CockroachDB’s transactions, since they also use snapshot, and produce temporary results, but Cockroach is more optimistic than deterministic. Also, Cockroach is more interested in low-latency transactions, while Aria is all about high throughput even at the expense of latency.
5) Deterministic reordering. The paper mentions that the reordering is a best-effort algorithm and not the most optimal one. It also seems that reordering plays a big role in having high throughput, so can we squeeze more performance with a better reordering algorithm? Obviously, it is not efficient to brute-force all possible permutations, but maybe some better heuristic approach?
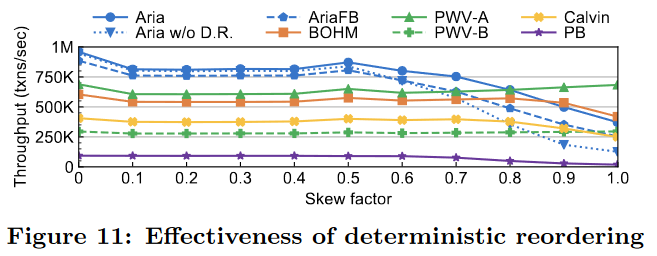
6) Performance variance under conflict. Aria works best for workloads with not a lot of conflict between transactions. Reordering helps, but not in all cases, as evidenced in the evaluation.
Join our reading group on slack for more discussions, paper schedule, and zoom participation.