
This is a short follow-up to Murat’s PigPaxos post. I strongly recommend reading it first as it provides full context for what is to follow. And yes, it also includes the explanation of what pigs have to do with Paxos.
Short Recap of PigPaxos.
In our recent SIGMOD paper we looked at the bottleneck of consensus-based replication protocols. One of the more obvious observations was that in protocols relying on a single “strong” leader, that leader is overwhelmed with managing all the communication. The goal of PigPaxos is to give the leader a bit more breathing room to do the job of leader, and not talking as much. To that order, we replaced the direct communication pattern between leader and followers with a two-hop pattern in which a leader talks to a small subset of randomly picked relay nodes, and the relays in turn communicate with the rest of the cluster. PigPaxos also uses relays to aggregate the replies together before returning to the leader. On each communication step, PigPaxos uses a new set of randomly picked relay nodes to both spread the load evenly among the followers and to tolerate failures.
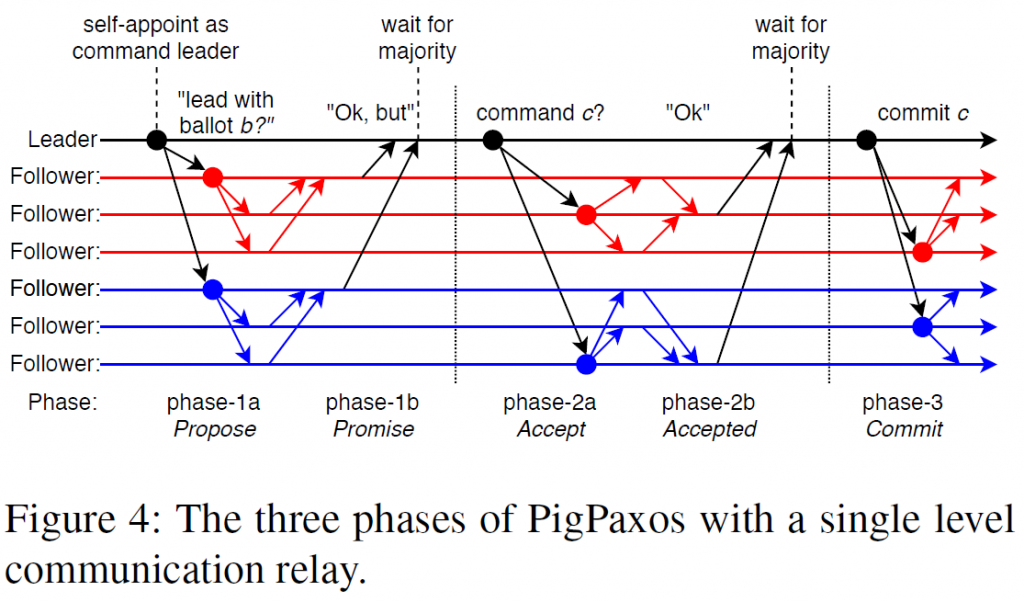
By randomly rotating the relays and enforcing timeouts and including some other optimization on how many nodes to wait at each relay node, we can provide adequate performance even in the event of node crashes or network partitions. The fault tolerance limit of PigPaoxs is similar to Paxos, and up to a minority of nodes may fail with the system still making some (limited if implemented naively) progress.
Some More Results
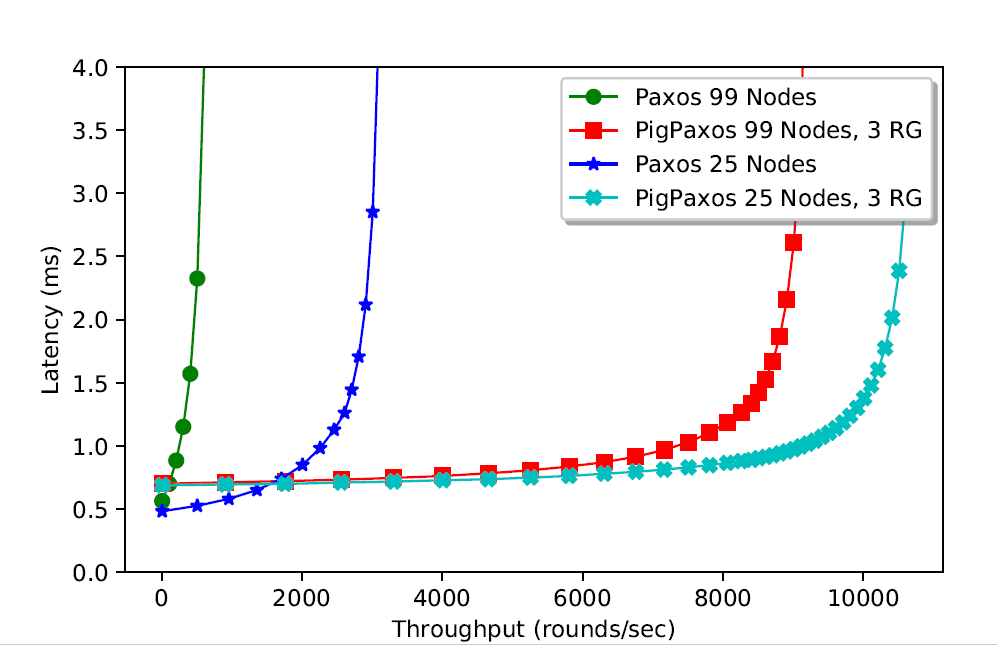
In the original PigPaxos post, we have not talked about scaling to super large clusters. Well, I still do not have that data available, but following the footsteps of our SIGMOD work, we have developed a performance model that, hopefully, is accurate enough to show some expected performance on the bigger scale.
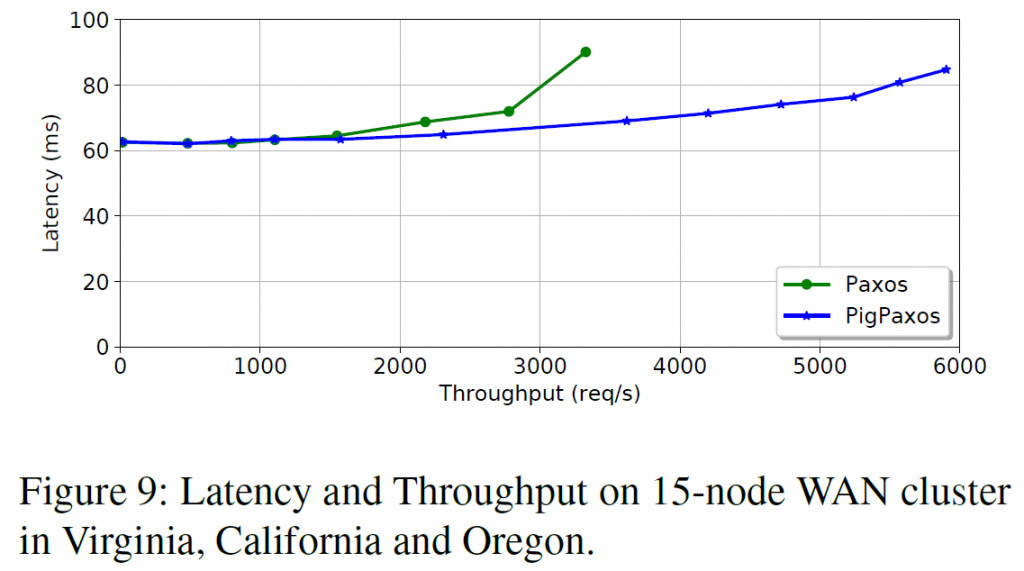
Network uniformity is not a requirement for PigPaxos. In fact it is perfectly ok to have some links slower than the others. However, some arrangement of relay groups may be required to get the best performance when links between nodes have different speed or capacity. The most pronounced real-world example of this non-uniformity is the wide area networks. When we deployed real, not-simulated PigPaxos in such geo-distributed environment, it no longer had the disadvantage of slower latency, as the latency became dominated by much slower geo-links. We took advantage of natural division between fast and slow links, and made all nodes in every region to be part of the same relay group. Another advantage of this setup is the amount of cross-region traffic flowing, as data moves to each region only once regardless of how many replicas are there.
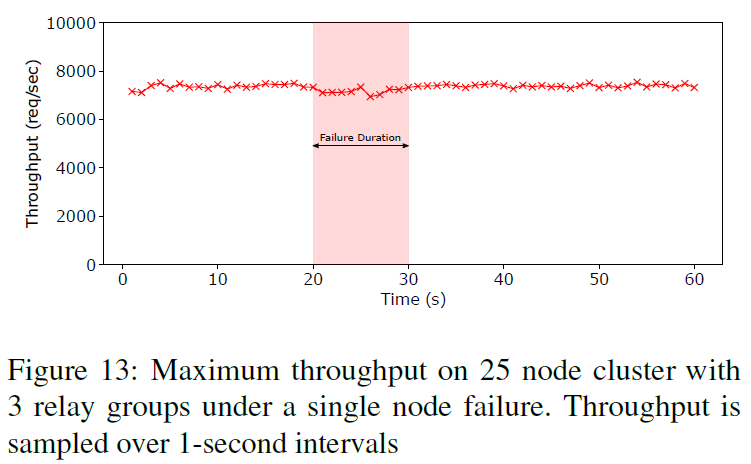
On the fault tolerance front, relay nodes definitely introduce more ways for the protocol to stumble. Crash of a relay node makes the entire relay group unavailable for that communication attempt. Crash of a non-relay node causes timeout which may add to the operation latency. The core principle behind PigPaxos’ fault tolerance is to repeat failed communication in the new configuration of relay nodes. Eventually, the configuration will be favorable enough to make progress, given that the majority of nodes are up. However, this process can be slow when many nodes are crashed, so some orthogonal optimization can help. For example, it is worth remembering nodes temporarily down and not use these nodes for relays or otherwise expect them to reply on time. Another approach is to reduce the wait quorum of the relay group to tolerate strugglers, or even use overlapping groups for communication redundancy. However, even with all these ad-hoc optimizations turned off, PigPaxos can still mask failures originating in the minority of relay groups without much impact on performance. For example, in the experiment below we have one relay group experiencing a failure on every operation for 10 seconds without much detriment to overall performance.
Why Scaling to This Many Nodes?
One of the most important questions about PigPaxos is “why?” Why do you need this many nodes in Paxos? Well, the answer is not simple and consists of multiple parts:
- Because we can!
- Because now we can tolerate more nodes crashing
- Because now we can make services like ZooKeeper or even databases to scale for reads just by adding more nodes. ZooKeeper reads are from a single node. And so are many databases that provide some relaxed consistency guarantees.
- Because it allows bigger apps with more parties that require consensus. And it is done by a single protocol.