This paper (Ring Paxos: A high-throughput atomic broadcast protocol) has been out for quite some time, but it addresses a problem still relevant in many distributed consensus protocols. Ring Paxos aims to reduce the communication load in the Paxos cluster and provide better scalability. As we have shown in our SIGMOD 2019 paper, communication is a great limiting factor in scalability of Paxos-like protocols.
Ring Paxos reduces communication overheads with a twofold approach. First, it uses ip-multicast to substitute direct node-to-node communication wherever possible with a broadcast type of communication. Second, Ring Paxos overlays a ring topology over (parts) of the Paxos cluster to control the message flow and prevent communication bottlenecks from forming.
Ring Paxos operates very similarly to regular Paxos, with differences being mainly in the communication part of the protocol. One node acts as a designated coordinator that receives proposals from the clients. However, the coordinator must confirm itself as a valid coordinator using the phase-1 of Paxos. To that order, the coordinator uses ip-multicast to send the message with some ballot/round number to all acceptors. This message also contains the ring configuration, including the node designated as the beginning of the ring. The acceptors receive the message and compare the ballot with their knowledge and only accept the node as new coordinator if the received ballot is the highest an acceptor has seen so far. Each acceptor is going to reply independently to the coordinator (not shown in the figure), and with these replies the coordinator will learn whether it has succeeded. Additionally, the coordinator also learns of any unfinished/uncommitted values that must be recovered.
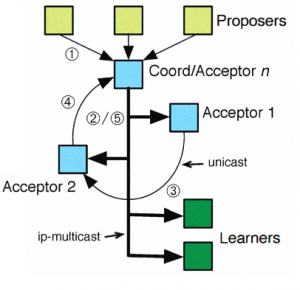
Upon successfully getting a quorum of confirmations, the coordinator moves on to the phase-2 of Paxos, illustrated on the figure on the right. During this phase, the coordinator replicates the commands/log entries to the acceptors. Similarly to the phase-1, the coordinator uses ip-multicast to send this message to the acceptors (message #2 in the figure). The acceptors (and learners) get the value/command to be replicated, but that value is not committed just yet. Along with the value, acceptors also receive the value-id (c-vid), a unique identifier for the value, and they set their working value-id (v-vid) to c-vid. The acceptors do not reply individually to the coordinator. Instead, the first coordinator in the ring sends a reply, containing the c-vid to its successor (message #3 in the figure). The acceptor receiving such reply will compare its v-vid and the c-vid from the reply message. The two value-ids match when the acceptor is not aware of any other value/coordinator is acting concurrently. In this case it forwards the message further down the chain. This chain forwarding in the ring happens until the reply reaches the coordinator (message #4), which sits at the tail of the chain. The protocol terminates the message propagation across the ring when the acceptor’s v-vid and c-vid from the reply message are different, leaving the coordinator to wait for a timeout and retry the protocol from the beginning with a higher ballot. Node failures produce similar outcome, since a failure completely hinders message propagation across the ring. As a result, the new phase-1 of Paxos must include a different ring configuration to try avoiding the failed node. When the coordinator receives the reply from the ring/chain, it sends the commit message to all acceptors and learners with the ip-multicast (message #5). The protocol may be extended for running multiple slots in parallel by ensuring the c-vid and v-vid comparisons happen within the same slot.
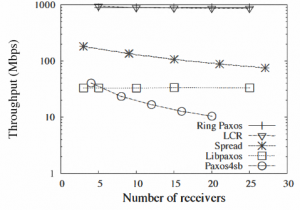
The performance of Ring Paxos is better that standard Paxos implementations, such as Libpaxos (uses ip-multicast), and Paxos4sb (unicast). It appears that Ring Paxos is capable of saturating most of the network bandwidth, with only LCR protocol pushing a bit more throughput.