This paper by Matthew Burke, Audrey Cheng, and Wyatt Lloyd appeared in NSDI 2020 and explores an interesting idea of a hybrid replication protocol. The premise is very simple – we can take one protocol that solves a part of the problem well, and marry it with another protocol that excels at the second half of the problem. This paper tackles replication in geo-distributed strongly consistent storage systems. The authors argue that consensus, when used in storage systems with predominantly read and write operations, is inefficient and causes high tail latency.
A system presented in the paper, called Gryff, takes advantage of predominantly read/write workloads in storage systems and exposes these two APIs via a multi-writer atomic storage ABD protocol. ABD operates in two phases both for reads and writes. On writes, ABD’s coordinator retrieves the latest version of the register from all nodes and writes back with a version higher than it has seen. On reads, ABD’s coordinator again retrieves the register, writes the highest version back to the cluster to ensure future reads do not see any previous versions, and only then returns back to the client. The write-back stage, however, can be skipped if a quorum of nodes agrees on the same version/value of the register, allowing for single RTT reads in a happy case.
Unfortunately, ABD, while providing linearizability, is not capable of supporting more sophisticated APIs. Read-modify-write (RMW) is a common pattern in many storage systems to implement transaction-like conditional updates of data. To support RMW, Gryff resorts back to consensus and in particular to Egalitarian Paxos (EPaxos) protocol. Choice of EPaxos allows any node in the cluster to act as the coordinator, so it does not restrict writes to a single node like with many other protocols. The problem of this hybrid approach is then the ordering of operations completed with ABD protocol and RMW operations running under EPaxos. Since EPaxos side of Gryff works only with RMWs, it can only order these operations with respect to other RMW operations, but what we need is a linearizable ordering of RMWs with normal writes and/or reads. To keep the ordering, Gryff uses tuples of ABD’s logical timestamp, process ID and the RMW logical counter, called carstamps. Carstamps connect the ABD part of the system with EPaxos – only ABD can update ABD’s logical clock, and only EPaxos updates RMWs counter.
When we consider the interleaving of writes and RMWs, the write with higher ABD’s logical time supersedes any other write or RMW. This means that we actually do not need to order all RMWs with respect to each other, but only order RMWs that have the same base or ABD’s logical time. EPaxos was modified to allow such partial ordering of commands belonging to different bases, essentially making the protocols to have different dependency graphs for RMWs applied to different ABD states. Another change to EPaxos is the cluster-execute requirement, as the quorum of nodes need to apply the change before it can be returned to the client to make the change visible for subsequent ABD read operations.
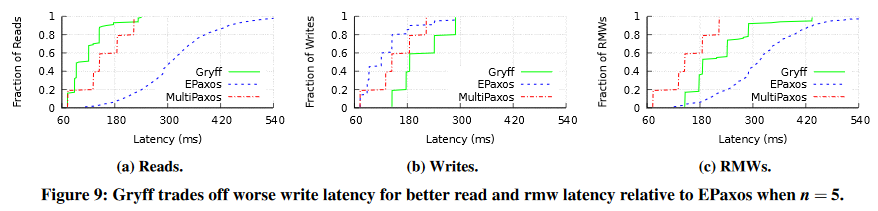
So, how does Gryff do with regards to performance? Based on the author’s evaluation, it is doing very well in reducing the (tail) latency of reads. However, I have to point out that the comparison with Multi-Paxos was flawed, at least to some extent. The authors always consider running a full Paxos phase for reads, and do not consider the possibility of reading from a lease-protected leader, eliminating 1 RTT from Paxos read. This will make Paxos minimum latency to be smaller than Gryff’s, while also dramatically reducing the tail latency. Gryff also struggles with write performance, because writes always take 2 RTTs in the ABD algorithm. As far as scalability, authors admit that it cannot push as many requests per second as EPaxos even in its most favorable configuration with just 3 nodes.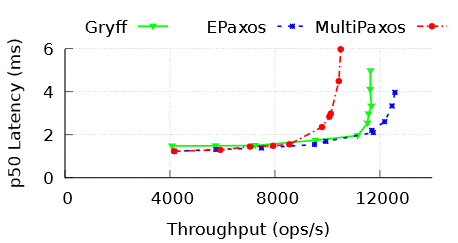
Can Paxos do better? We believe that our PQR optimization when applied in WAN will cut down most of the reads down to 1 quorum RTT, similar to Gryff. PQR, however, may still occasionally retry the reads if the size of a keyspace is small, however this problem also applies to Gryff when the cluster is larger than 3 nodes.
What about Casandra? Cassandra uses a protocol similar to ABD for its replication, and it also incorporates Paxos to perform compare-and-set transactions, which are one case of RMW operation, so in a sense Gryff appears to be very similar to what Cassandra has been doing for years.