Metastability is a stable state of a dynamical system other than the system’s state of least energy.
– Wikipedia
Distributed systems often fail spectacularly and unpredictably. They are a cause for a headache and sleepless on-call nights for way too many engineers. And this is despite lots of efforts to understand the failures, and all the tools and “best practices” we have to contain and/or prevent them.
Today I want to talk about failures that may occur on a nearly healthy system with no perceived major bugs or design flaws. We describe this type of failure in our HotOS’21 paper. This work is in collaboration with Nathan Bronson, Abutalib Aghayev, and Timothy Zhu. It is largely based on Nathan’s observations and experiences.
So how does a “healthy” system fail? Naturally, something needs to happen for a failure to occur. We call this something a trigger. Lots of things can act as a trigger (GC, network blips, software pushes, configuration changes, load spikes, etc.). Triggers are impossible to avoid in our multi-tenant unreliable systems.
Triggers cause backlogs or errors and make the system temporarily less happy. In some cases, however, they cause the system to spiral into the abyss and practically halt any useful work or goodput. When the trigger is removed (it was transient, or removed by the engineers), the system does not recover by itself. So we end up in a peculiar situation when the condition that caused a failure is no longer present, all system’s components seem to be functioning correctly, all servers/nodes are up, the code is working, but nothing useful is actually getting done and goodput remains negligible.
We call this failure pattern a metastable failure, or rather we say that a system has entered a metastable failure state. The culprit behind metastable failures is a sustaining effect that prevents the system from leaving a bad/failed state even after the initial trigger is removed.
To understand more about the importance of triggers and sustaining effects, we need to look at how most distributed systems are deployed. Resource utilization is a major factor for large systems, as achieving better utilization can save a lot of money at scale. This means that systems often have little extra resources to spare when some unexpected load increase occurs. These systems operate in a metastable state that we call a metastable vulnerable state, as the system is vulnerable to a failure if enough of a trigger disturbs its stability.
Of course, having some unanticipated extra load applied to the system is not sufficient for a metastable failure to occur. In fact, even if the load pushes the system to run at its maximum capacity (or tries to run above the capacity), we should only see an increase in latency, and maybe some goodput degradation. When the extra load is removed, the system should return back down to normal operation all by itself.
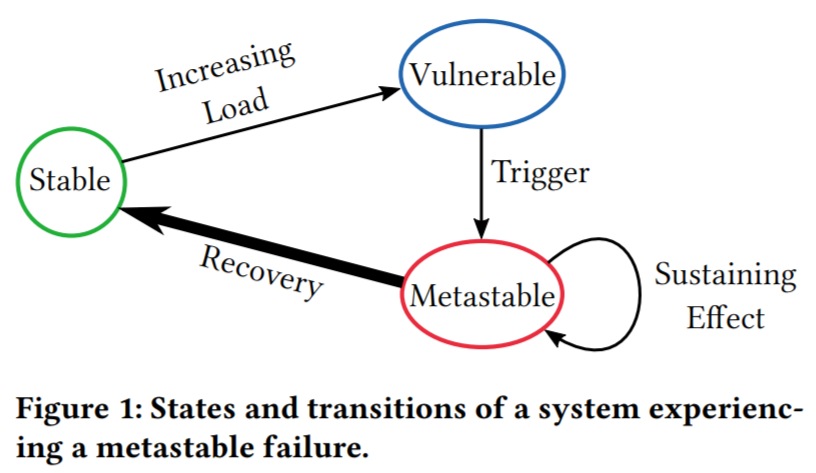
In metastable failure, the extra unanticipated load activates a positive feedback loop that creates more load. This positive feedback loop is the sustaining effect that prevents the system from recovering when the initial trigger is resolved. We say that a system is in a metastable vulnerable state when it is possible to activate such a sustaining effect loop using a strong enough trigger. This state typically occurs at the higher system utilization, as the system has fewer spare resources to absorb the extra load of the trigger without activating the positive feedback mechanism. Opposite of metastable vulnerable state is a stable state, where the positive feedback loop is not possible, allowing the system to recover by itself when the extra load is removed. Note that a system in a stable state may still have a sustaining effect mechanism, but it is not strong enough to feed on itself and diminishes over time when the extra load is removed.
Let’s look at a hypothetical idealized example of a metastable failure. Consider a web application that uses a database capable of serving up to 300 queries per second (QPS). If more than 300 QPS are tried, the latency goes up by an order of magnitude, causing the web application to retry once after a 1-second timeout (when a retry fails, the system errors out). The web servers for the application produce a 280 QPS workload, which falls nicely below the database’s serving capacity.
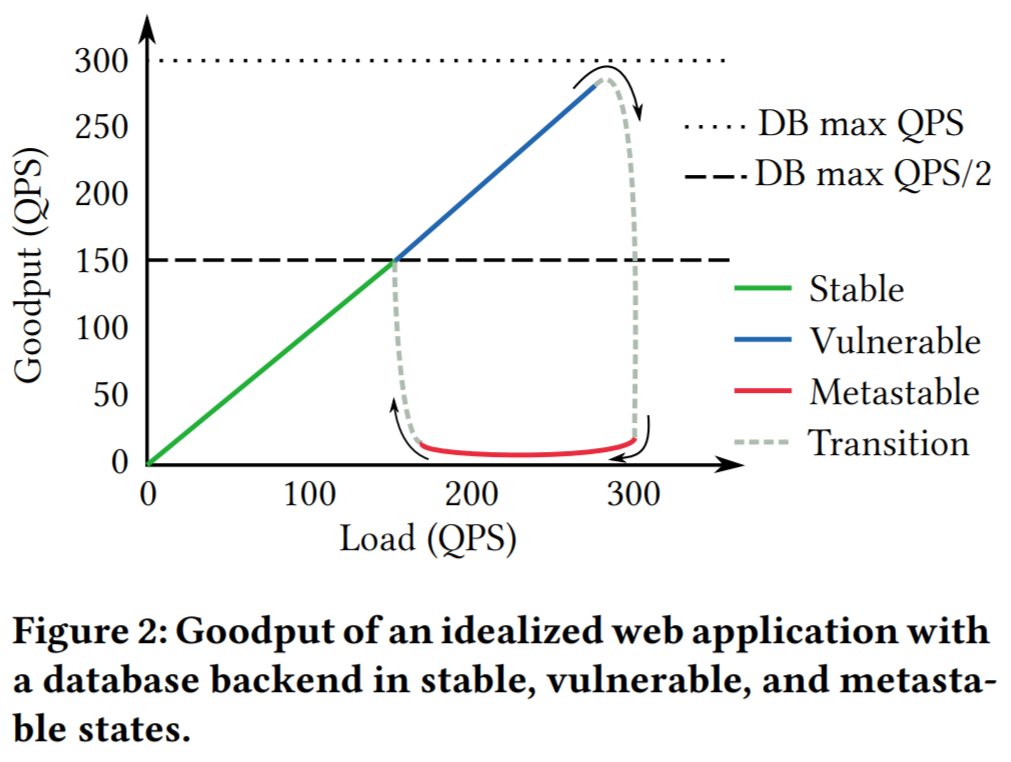
Now let’s say there was a network glitch lasting a few seconds between the web servers and the database. After the network is fixed, all the delayed packets reach the database, resulting in a flooding manner, exceeding the database’s capacity of 300 QPS. This, in turn, increases the latency above the retry threshold at the web application, causing any new, post-network-glitch queries to retry as well. So now we have a backlog of queries from the network glitch and an effective new query load of 560 QPS (280 queries from the workload + 280 query retries). With such a high and sustained load, the database will not return to a normal state all by itself. This results in a maxed-out system that clears 300 QPS of load (smaller than the amplified load) and produces very little goodput since most of the queries take too long to process and get timed-out or discarded by the time the database returns them. This can continue indefinitely until either the offered workload reduces to under 150 QPS or a retry policy is changed/suspended.
Our simple example illustrates key metastable concepts and principles. In a stable state, a system can (gradually) return to normal operation. In the example, workload under 150 QPS is stable, since even with the workload amplification caused by the retry policy, the database will receive fewer new requests than it can handle each second, allowing it to gradually clear up the backlog and return to normal operation. While the system is clearing the backlog, its goodput, however, may remain compromised. Systems often operate in the vulnerable state because it seems from all metrics like the stable state is wasting resources, and the vulnerability is not known. This, however, leaves very little spare resources to absorb the extra load spikes caused by the trigger events. Once a system enters into a metastable failure state, it will feed onto itself until there is some sort of intervention. This intervention is costly, as it generally requires either reducing the offered load on the system or finding ways to break the positive feedback loops.
Another possible intervention approach is to increase the capacity of the system to push it into a stable state, but this can be challenging since the triggers are unanticipated. Such unpredictability makes it impossible to reconfigure to add capacity beforehand. And once the system is already in a metastable failure state, it may not have any resources to spare to run the reconfiguration procedure. In fact, a reconfiguration may even increase the workload amplification and make the whole situation worse.
In the paper, we discuss a few other hypothetical and anecdotal scenarios that are a bit more complicated. But the problem is not anecdotal by any means, as there are quite a few failure cases that surely look a lot like metastable failures “in the wild”:
- Google App Engine Incident #19007. Trigger: Configuration change. Sustaining Effect: cascading load amplification. Fix: Reduce traffic level.
- Amazon SimpleDB Service Disruption. Trigger: power loss crashing multiple servers. Sustaining Effect: load amplification due to a timeout. Fix: Change in timeout policy & introduction of additional capacity.
- Cassandra Overload because of hint pressure + MVs. Trigger: rolling restart. Sustaining Effect: Few nodes could not catch up with hinted hand-off, preventing them from fully joining, causing the system to generate more hints. Fix: Policy change – disable hinted handoff.
With metastable failures affecting real systems, we need to have more understanding of the problem and processes involved to develop better coping and prevention strategies. A recurring pattern in our experience is that changes meant to improve the common case behavior of a system tend to increase the strength of the sustaining effects. Fast paths, caches, retries, failover, load balancing, and autoscaling all make the failure state less resource-efficient relative to the normal state, which makes the feedback loop worse. Beware of very high cache hit rates!
Metastable failures are over-represented in large site outages because the strength of the sustaining effect depends on scale. For example, if the feedback loop requires overloading a network fabric then small-scale stress tests will never trigger it. The sustaining effect may also act as a means of contagion so that the problem spreads across machines or shards. This means that the first occurrence of a novel metastable failure may be a major outage even in a hyper-scale distributed system.
Current approaches for handling metastability often lack the full comprehension of the problem and its causes. For example, engineers often focus on the trigger that causes the failure and fail to realize the complicated positive feedback loops that are responsible for the scale of the failure. Fixing a trigger is a temporary solution that may only push the system higher into the metastable vulnerable zone and make the next crash even more severe.
Unfortunately, replicating the failures and feedback loops is difficult, as many of the issues only manifest themselves at scale. This makes it ever so harder to fully understand the failures and develop efficient techniques for dealing with them. Furthermore, predicting the possibility of failure is difficult too. For instance, one can look for unexpected performance variations, and try to correlate them with other things going on in the system to learn the potential future triggers, but this still does not give the full predictive power of when a failure may happen. Improvements in our ability to predict and avoid metastable failures will also translate directly to efficiency gains because it will let us operate systems closer to their natural performance limits.
I think this is an exciting area for research. As the industry makes bigger and bigger systems and pushes them to work as cheaply as possible, we need to develop a proper understanding of how these critical systems fail at scale so we can continue improving the reliability.