As trivial as it sounds, but keeping the data close to where it is consumed can drastically improve the performance of the large globe-spanning cloud applications, such as social networks, ecommerce and IoT. These applications rely on some database systems to make sure that all the data can be accessed quickly. The de facto method of keeping the data close to the users is full replication. Many fully replicated systems, however, still have a single region responsible for orchestrating the writes, making the data available locally only for reads and not the updates.
Moreover, full replication becomes rather challenging when strong consistency is desired, since the cost of synchronizing all database replicas on the global scale is large. Many strongly consistent datastores resort to partial replication across a handful of nearby regions to keep the replication latency low. This creates situations when some clients close to the regions in which data is replicated may experience much better access latency than someone reaching out from the other side of the globe.
Despite the obvious benefits of adapting to locality changes, many databases offer only static partitioning. Of course, some data stores have the migration capability, but still often lack the mechanisms to determine where the data must be moved. Quite a few orthogonal solutions provide capabilities to collocate related data close together or use days or weeks’ worth of logs to compute better data placement offline. Meanwhile, Facebook’s aggressive data migration helps them reduce the access latency by 50% and save on both storage and networking.
We (@AlekseyCharapko, @AAilijiang and @MuratDemirbas) investigated the criteria for quick, live data migration in response to changes on access locality. We posit that effective data-migration policies should:
- Minimize access latency,
- Preserve load balancing with regards to data storage and processing capacity
- Preserve collocation of related data, and
- Minimize the number of data migrations.
Policies
We developed four simple migration policies aimed at optimizing the data placement. Our policies operate at an arbitrary data-granularity, be it an individual key-value pairs, micro-shards, or the partitions. For simplicity, I say that policies work on objects that represent some data of an arbitrary granularity.
The main point we address with the policies is minimizing access locality, with each policy using a different heuristic to make a data-placement decision. Once the policy finds the most optimal location for an object, it checks the load balancing constraints to adjust the data migration decision as required.
Our simplest policy, the n-consecutive accesses policy, uses a threshold of consecutive accesses to the object to make the placement decision. Although simple, this policy works well for workloads with strong locality in a single region. Majority accesses policy keeps track of some request statistics and uses it to find the region with the most accesses to an object over some time interval. It then migrates the data over to that region.
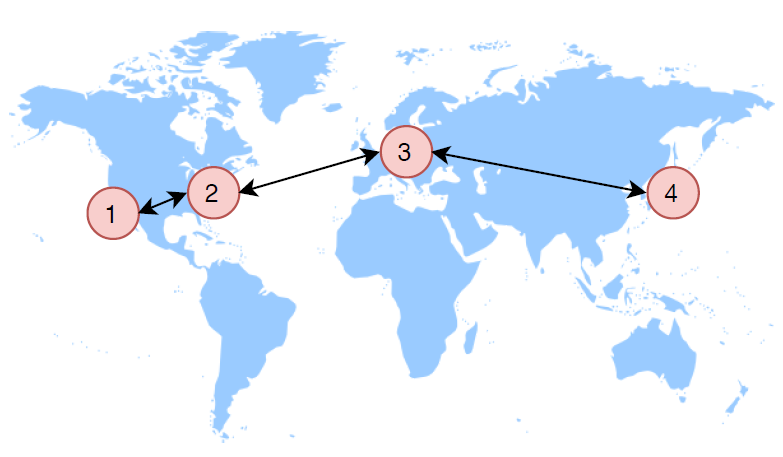
The exponential moving average (EMA) policy takes a different approach and computes the average region for all requests to the object. The average region is computed as an exponential moving average favoring the most recent requests. This policy can potentially find better placement for objects that have more than one high-access region. However, it requires the regions to have numerical IDs arranged in the order of region’s proximity to each other. This policy falters for deployments with complicated geography and may require multiple migrations to move data to the best location. Another disadvantage of EMA is that it takes longer to settle and requires many data migrations. Unlike other policies that can move the data directly to the desired region, EMA can only migrate objects to one of the neighboring regions, making adjustment such as going from region (1) to (3) include a temporary migration to region (2).
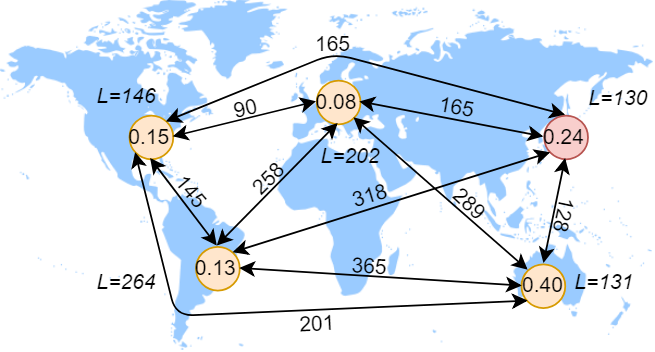
Finally, the center-of-gravity (CoG) policy calculates the optimal object placement by taking into account the distribution of all requests to an object and the distances between the datacenters. CoG policy calculates the region closest to the central location for any access locality workloads. CoG can collect the request statistics similar to the majority accesses policy and make a placement decision only after some time has elapsed since last decision. Alternatively, it can use a continuous metric to assign each region a score corresponding to its weight in the workload, adjust the score and recompute the best object placement with every request.
Some Evaluation
I’ve simulated protocols under different access locality scenarios and calculated the latency of inter-region access and the number of object movements each policy makes. In the simulations, I used 3000 distinct objects, initially assigned to a random region in the cluster of 15 regions. I used the AWS inter-region latencies to specify the distances between simulated regions. To my surprise, even the most basic policies showed good improvement over static random placement of data.
In the first experiment, the objects were accessed according to a normal distribution. Each object has a ID assigned to it, and some Normal distribution dictates the probability of the drawing the ID each region. All regions have distributions with the same variance, but different means, making each region predominantly accessing some of the objects, and having some group of objects being more-or-less shared across the regions with adjacent IDs.
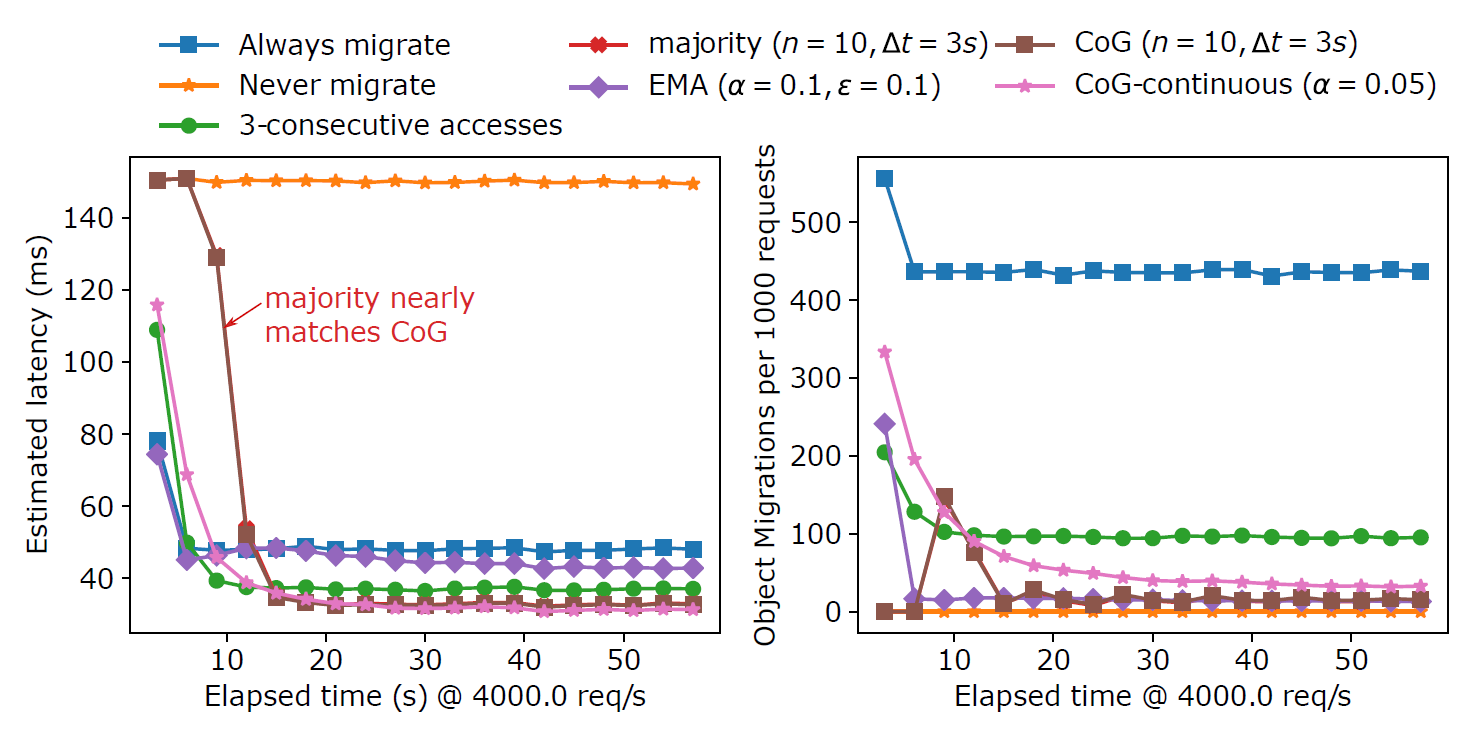
When the workload is no longer predominantly single region dominant for every key, single-region heuristic policies perform worse. For instance, equally sharing an object between utmost 3 regions out of 15 causes majority and 3-consecutive accesses policies to lock in to one of the sharing regions instead of optimizing the latency for all sharing regions. CoG policy can place the data in a region optimal for all 3 regions (and not even necessarily in one of the sharing regions) and optimize the latency better than a single-region heuristic, topology unaware policies. EMA policy is at a big disadvantage here, since it relies on ID assignments to dictate the proximity of regions. However, the complex geography of AWS datacenters makes a good ID assignment nearly impossible, causing EMA to sometimes overshoot the best region and settle in less optimal one.
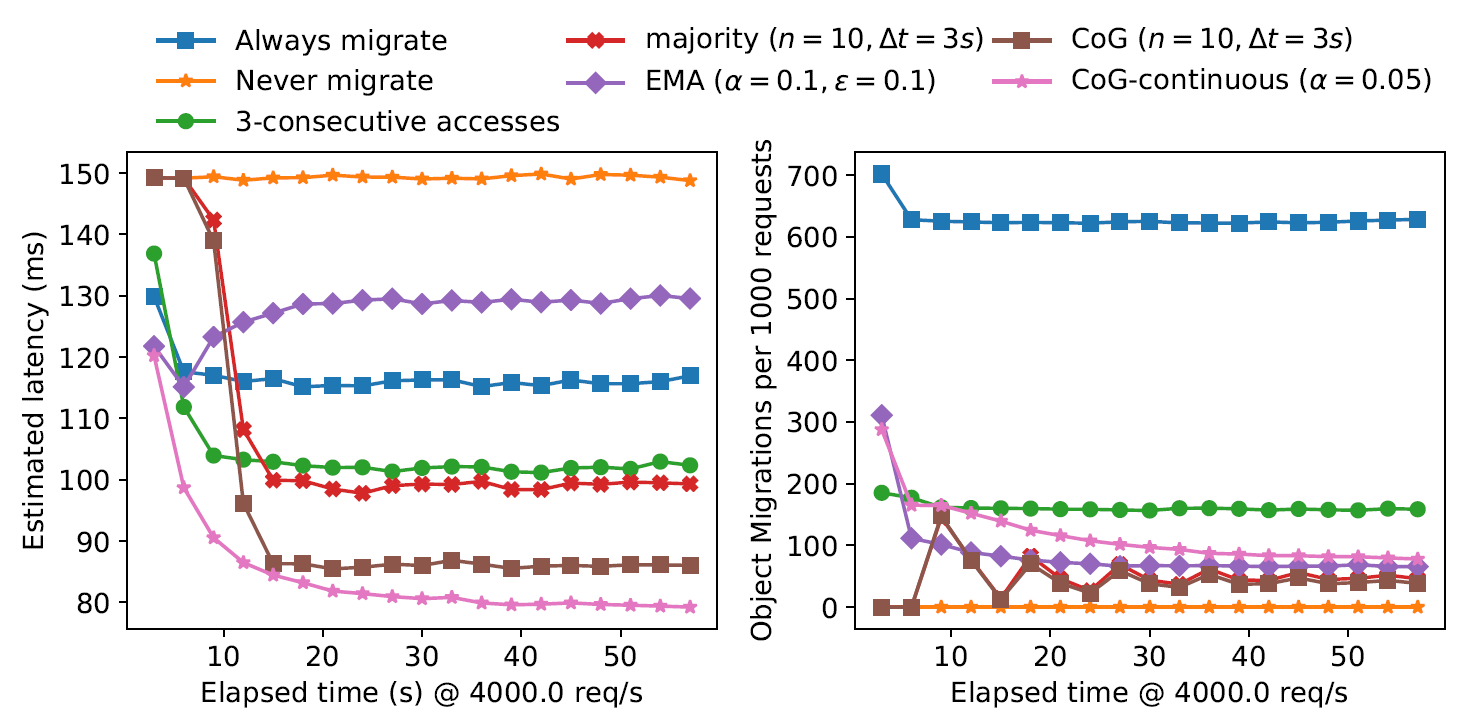
Access locality may fluctuate on a regular basis, and the policy needs to be able to adopt to such changes and adjust the system to keep the latencies low. In this experiment I gradually adjust the normal distribution used in the earlier experiment to make a gradual workload switch. In the figure below, the system ran for enough time to make all objects switch the access locality to the neighboring region. However, the policies adopt well to the change, keeping low latency despite the moving workload. EMA is one notable exception again, as it first gets better latency and the gradually degrades until reaching a steady state (In a separate experiment I observe EMA stabilizing over at around 59 ms of latency)
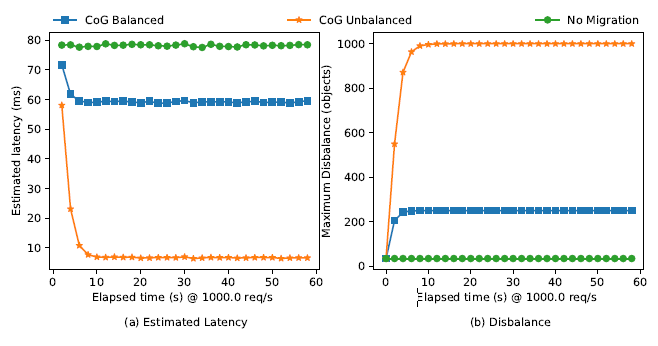
Previous experiments did not consider the effect of load balancing. However, a good data-migration policy should refrain from migrating data to overloaded regions. In the next experiment I applied load-balancing filter to the CoG policy to make the migration procedure first compute the best region for the object, check if that region has the capacity, and if no capacity is available, move the data to the next best region with enough processing/storage capacity. Here I used 5 regions and 1000 objects, and limited each region to storing at most 25% of all data. I ran a heavily skewed workload with 80% of all requests coming from a single region. Under these conditions the CoG policy achieves very low average latency. However, as evidenced by the disbalance graph, all objects migrate over to a single region. If load balancing is enabled, no region becomes overloaded, but latency improvement becomes more modest.
Concluding Remarks
Having data close to the consumers can dramatically improve the access latency. For some databases, this means doing full replication, for other this may involve moving data or the owner/write role from one region to another. It is important to make sure the data is moved to a right location. I have looked at four simple rules or policies for determining the data migration and ran some simulations on these.
There are a few lessons I have learned so far from this:
- Topology aware rules/polices work better for a larger variety of situations
- Simple rules, such as just looking a number of consecutive requests coming from a region or determining the majority accesses region can also work surprisingly well, but not always. These tend to break when access locality is not concentrated in a single region, but shared across a few regions in the cluster
- EMA looked interesting on paper. It allowed to have just a single number updated with every request to determine the optimal data placement, but it performed rather bad in most experiments. The main reason for this is complicated geography of datacenters.
- Optimizing for latency and adjusting for load balancing constraints to prevent region overload can be done in two separate steps. My simple two-stage policy (presently) looks at load balancing for each object separately. This becomes a first-come-first-serve system, but I am not sure yet whether this can become a problem.
- EMA policy takes multiple hops to move data to better region, while n-consecutive accesses policy has constant jitter for objects shared by some regions
I have not studied much about data-collocation in my experiments, nor designed the policies to take this into consideration. One of the reasons is that I think related objects will have similar access locality, causing them to migrate to same datacenters. However, this is just a guess, and I need to investigate this further.