I am very behind on the reading group summaries, so this summary will be short and less detailed. In the 67th reading group meeting, we discussed the “When Cloud Storage Meets RDMA” paper from Alibaba. This paper is largely an experience report on using RDMA in practical storage systems.
Large-scale RDMA deployments are rather difficult to manage and maintain. This is the result of RDMA over Converged Ethernet (RoCE), which requires a Priority Flow Control (PFC) mechanism to prioritize the RDMA traffic and prevent frame loss on RDMA traffic due to congestion. PFC includes the mechanisms to pause network nodes (i.e switches, NICs, etc) from sending data to an overwhelmed nodes. This can also create backpressures in the network and can cause degraded operation, dropped frames, and even deadlocks. So anyway, while RDMA needs PFC, it can cause major reliability issues even for large companies.
Alibaba paper presents a handful of engineering solutions and workarounds to deliver RDMA performance while maintaining high reliability. I will mention two general approaches the paper takes.
First, the authors do not try to make every machine accessible via RDMA from anywhere in a data center. Instead, the network/datacenter is divided into podsets, and machines within a podset can take advantage of RDMA when talking to each other, while communication between podsets relies on good-old TCP. I suspect this provides a lot of isolation and greatly limits the extent to which PFC problems can go.
The second approach is to fail fast. To support tight SLA, Alibaba engineers prefer to failover the problematic connections quickly. For that, upon detecting problems with RDMA, the podset falls back to using TCP. As a result, the Pongu system operates in this kind of hybrid mode — whenever possible, RDMA is used for low latency and high throughput, but TCP connection is always ready as a backup.
The paper talks about a few other engineering solutions and optimizations aimed at improving reliability and performance. For example, the network is built with redundant switches, including Top-of-Rack switches. One important performance optimization is offloading as much work away from the CPU and onto special-purpose hardware. The paper specifically talks about CRC computations offloaded to NIC to save memory bandwidth and CPU cycles. Kernel bypass (DPDK) is used as well. Many of these and other (i.e. user-space SSD optimized file system, RPC thread management) optimizations reside in the User Space Storage Operating System (USSOS) part of Pangu.
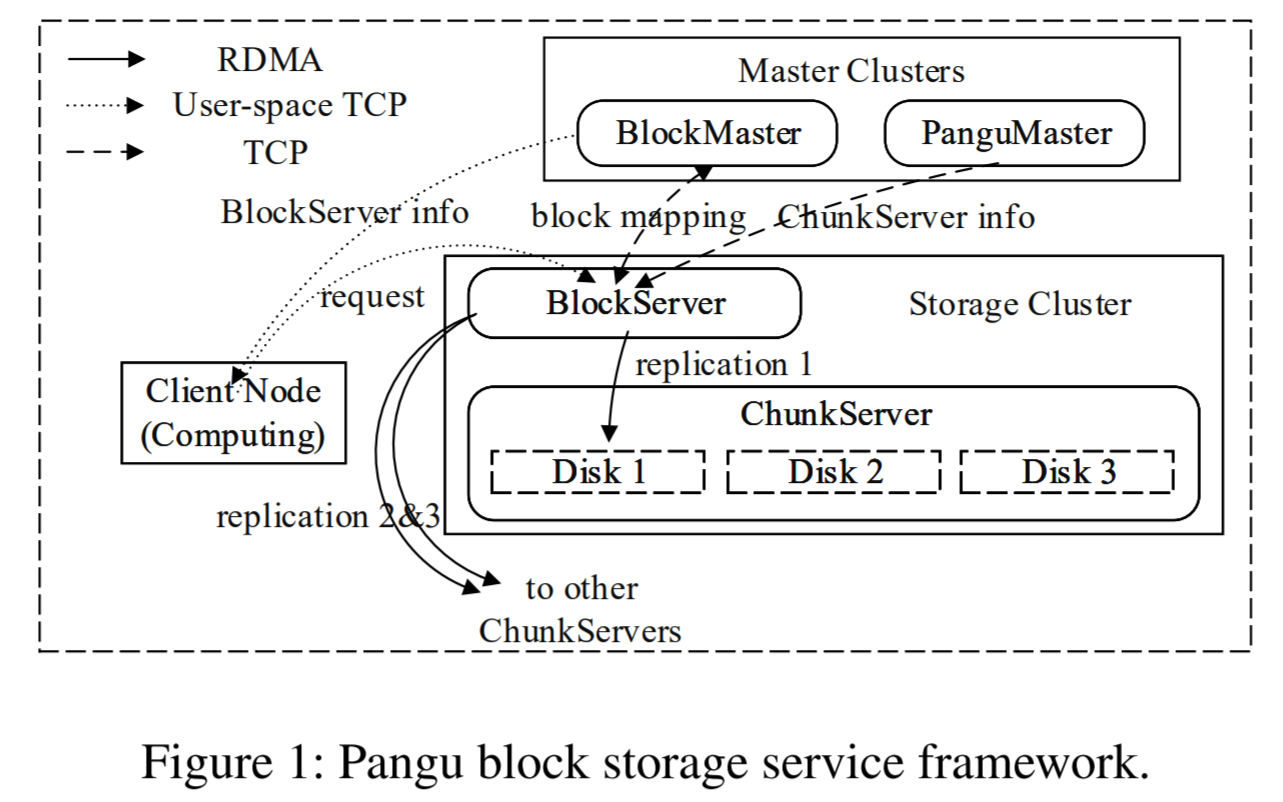
Now I realized that I actually have not talked about the Pangu storage system itself. The image taken from the paper is a decent summary. In short, the storage cluster runs in a podset, so BlockServers can access storage with RDMA. There can be many storage clusters, each cluster in its own podsets. The storage clusters, however, do not talk to the clients using RDMA, and the clients communicate with storage using TCP. So, in the best-case scenario, a client’s request will have one TCP hop and one RDMA hop inside the storage cluster instead of two TCP hops. The experimental data from the paper largely supports this, as latency is essentially halved for clients when RDMA is used. Similarly, the Pangu Master Cluster services communicate with storage and clients using TCP.
As always, we had a paper presentation in the group. Akash Mishra presented this time:
Discussion
1) Bi-model operation. The fail fast and switch to a backup mode of operation allow for a more reliable operation of the system. However, having these two distinct modes and the spectrum of performance between them may present additional problems. Metastability may come to play here as the system transitions from fast mode to degraded mode due to some external trigger. If the system becomes overwhelmed in this degraded mode, it may develop a positive feedback loop that feeds more work and keeps it overwhelmed. In general, having distinct performance modes is a flag for metastability, and extra care must be used when the system transitions from fast to slow operation.
2) RDMA at other companies. The paper cites Microsoft’s experience report with RDMAquite extensively when talking about reliability issues of using RDMA at scale. So it is obvious that the experience is shared, and it may be the reason for RDMA being largely not offered in the public cloud. The last time I checked, Azure had a few RDMA-capable VM instances, while AWS EC2 had none (instead, EC2 offers its own tech, called EFA).
3) Offloading CPU. This was an interesting point as well. The paper notes that RDMA is so fast that the memory bandwidth becomes a bottleneck! To limit memory usage, Pangu offloads data verification through CRCs away from the CPU and onto smart NICs. This saves quite a bit of memory roundtrips on accessing messages/payload to compute/verify CRCs. Using various accelerators is a common theme in many large systems.