For the 90th reading group paper, we did “Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amazon S3” by James Bornholt, Rajeev Joshi, Vytautas Astrauskas, Brendan Cully, Bernhard Kragl, Seth Markle, Kyle Sauri, Drew Schleit, Grant Slatton, Serdar Tasiran, Jacob Van Geffen, Andrew Warfield. As usual, we have a video:
Andrey Satarin did an excellent write-up on this paper, so I will be short here. This paper discusses the use of formal methods in designing, developing, and maintaining a new key-value storage subsystem in Amazon S3. In my opinion, the core idea and contribution of the paper is establishing engineering processes that ensure that implementation adheres to the specification.
See, using traditional formal methods is hard in practice. For example, using TLA+ to model the system creates a model that is detached from implementation. If something in the system changes, both need to be updated. Moreover, updating TLA+ would require experts in TLA+, creating a possibility of model and code diverging over time. Another problem is using the model to check the implementation. Since the two are detached from each other, this becomes rather difficult.
The paper proposes lightweight formal methods that can be integrated directly into the testing/build framework. The approach requires implementing a reference model for each component that captures the semantics/behavior of the component without any real-world concerns. For example, the model for LSM-tree is a hashmap — both have the same behavior and allow reads and writes of some key-value pairs.
Engineers use these references models n a couple of ways. First of all, the models act as mocks for unit tests. This increases the utility of the models and forces the engineers to keep them up to date. But of course, the main purpose of the models is to confirm the behavior of the real implementations. The gist of the conformance checking is verifying that the implementation’s behavior is allowed by the model. To do so, the same test, consisting of some sequence of operations, runs against the implementation and the model. The expectation is that both go through the same states and deliver the same outputs. Below I have an image borrowed from the author’s slides that illustrate the process.
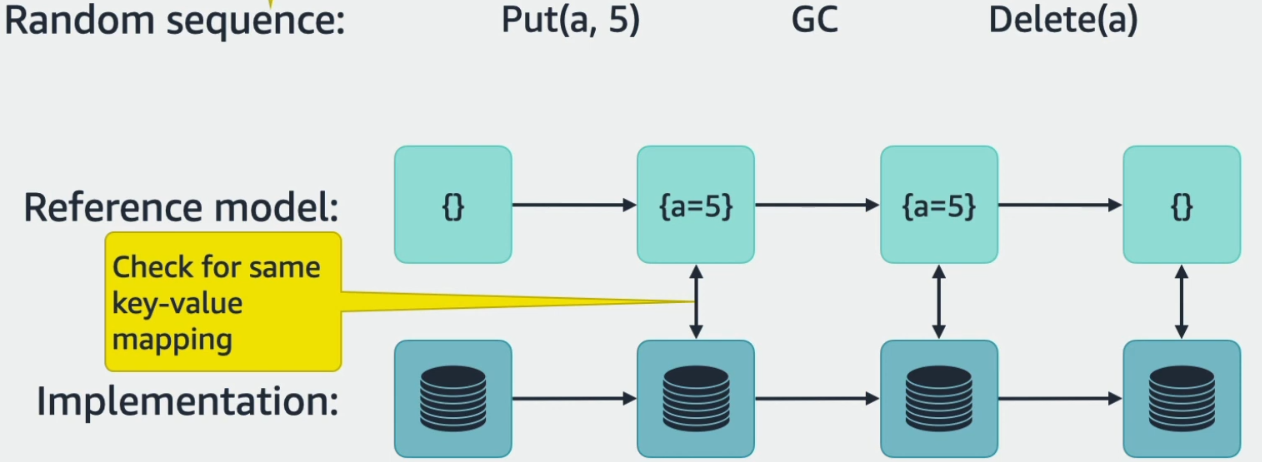
Of course, there are some challenges with running these tests. For instance, it is important to generate interesting scenarios/sequences of operations to test various behaviors. Another challenge is introducing failures into testing. And finally, sequential execution of some operations does not provide comprehensive coverage in modern, multi-threaded, or distributed code, requiring some concurrent testing as well. The paper talks more about these different scenarios in greater detail.
Discussion
1) Reliance on experts in formal methods. A big point made by the paper is about not having to rely on formal experts to maintain the models and verification. The paper says that while initially all models were written by experts, at the time of writing the paper, about 18% of the models were written by non-experts. To us, this sounded both as a big and small number. It is important to allow engineers to maintain the models and conformance checking framework, and the number clearly shows that the core engineers are getting onboard with the processes involved. At the same time, it is not clear whether a team can completely get rid of expert support.
2) Importance of processes. As we discussed the reliance on experts and reducing this reliance, it became clear that a big contribution of this paper is about the importance of engineering processes. And it is not just about having some processes/workflows to facilitate formal methods adoption. What is crucial is making these processes scale and thus not require significant additional effort from the engineers. For example, developing models to support formal methods is an extra effort. Using these models as mock components for unit tests amortizes such extra effort into almost no additional work. After all, we need to do unit testing anyway, and using mocks is a common practice.
3) TLA+? It is hard to discuss any formal methods paper in our reading group without having some discussion on TLA+. We have talked about the difficulty of keeping the models up to do date with the implementation. Using TLA+ does not seem to allow for a low-effort mechanism — there is a big overhead to having engineering processes/practices that keep the TLA model and implementation coherent.
4) Testing Reading List. Our presenter, Andrey, has compiled an extensive reading list on testing distributed systems. It is most definitely worth checking out.
5) Codebase size. The authors talk about using these lightweight formal methods on the codebase of about 40,000 lines of code. This is not that much code, to be honest. In fact, this is less code than a handful of my academic projects, not to mention the real software that I have worked on. So it would be interesting to see how these approaches can scale to bigger codebases and bigger teams with more people.