Unlike many of my recent summarier, I will mskr this one short, I promise. “Unifying Timestamp with Transaction Ordering for MVCC with Decentralized Scalar Timestamp” NSDI’21 paper proposes a mechanism to order transactions in multi-version distributed data-stores. One of the problems with distributed transactions is the ordering required to achieve consistency. In particular, we often want to have some serial order of transactions to have an illusion that they could have executed one by one. This is hard to do in a scalable manner. One approach is to try to rely on the physical clocks of the machines, but this is unreliable due to clock skew and clock synchronization issues. Clock skew can introduce causality violations. For example, if transaction TXa happened-before TXb, but due to clock skew, transaction TXa got a larger timestamp than TXb, then we have a causality problem — the cause and effect are reversed if we follow the timestamp order. One way to avoid such causality issues is to rely on a centralized oracle to prescribe the transaction order. Quite a few systems do that, but for obvious reasons, a centralized approach may create scalability and reliability problems. There are a few other ordering mechanisms, such as vector clocks/version vectors and hybrid time.
The authors of the paper take the hybrid time approach that they call Decentralized Scalar Timestamp (DST). DST is a single number that represents the progression of history. It is decentralized, thus avoiding the problems with a single timestamp oracle, and it is smart enough to avoid causality problems. The authors marry the timestamp generation/progression with the concurrency control (CC) mechanism, such as 2PL, allowing CC to adjust the timestamp to match the execution order. Consider two write-conflicting transactions TXa and TXb. Both transactions have some initial timestamps ta and tb respectively. These initial timestamps are based on the timestamps of the last transaction known to the coordianator or client (and ultiamtely based on the lossely sycnhrnonized physical time). And then the authors propose to use CC to bump up the timestamps as needed to ensure that the timestamps follow the execution order managed by the concurrency control mechanism. So for example, if initially ta < tb, but TXb happened-before TXa, then we bump ta := tb + 1. The actual “bumping-up” is a bit more complicated since the time is stored as two components – physical time and logical one, but the result is that the new timestamps are ordered the same way as the transaction execution.
Since the system operates against a multi-version store, the versions from both transactions are preserved. This is important for performing reads that are based on consistent snapshots, so the latest state may advance forward, and a multi-version store ensures that the snapshot remains available for reads. The read-only transactions (ROTs) bypass some concurrency control and try to avoid locking in the paper. Read-only transactions, however, still need to ensure isolation, as it would be unacceptable to see a result of a partial write. To that order, ROTs have to actively write their read version on all objects and wait for locked objects to get unlocked before reading. This enables the consistent cut read and allows new writes to proceed without blocking but with a higher version than the read.
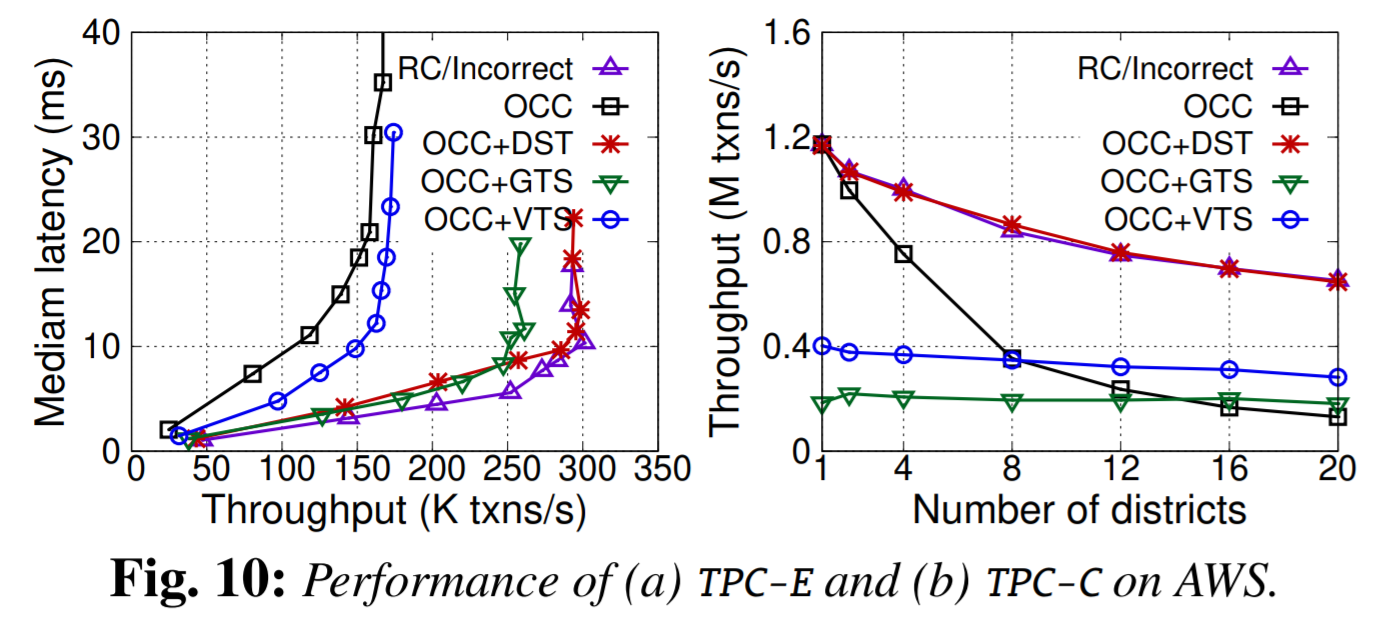
As far as evaluation, the paper presents multiple different environments and a few different benchmarks along with a pretty good breakdown of comparisons between different approaches.
We have had our own presentation by David Correa, the recording is available on the reading group’s YouTube:
Discussion.
1) HLC. The biggest discussion topic for this paper was a relation to the Hybrid Logical Clock (HLC). See, HLC is a well-known approach combining physical time and logical time. It keeps the affinity to physical time and maintains the causality just as Lamport’s logical clocks. The authors discuss that their DST approach is a combination of physical time and a logical one, just like HLC. However, the HLC work is never cited. It seems like the internal operation of the timestamp/clock is very similar. Moreover, there are well-described transaction protocols relying on HLC and MVCC described in the literature in great detail. It would be very interesting to see more about the DST clock operation and see its comparison with HLC. Similarly, it would be interesting to compare with transactions scheme by CockroachDB or YugabyteDB.
One bigger difference from typical HLC implementation is that DST increments/ticks only at significant events, such as transaction execution. HLC often tick at message passing in addition to significant events. This is a more general way to ensure clocks causally update on each communication, however, this is not a requirement for protocols with simple communication exchange patterns. In fact, Mongo updates HLC only at significant events.
2) Performance of Read-only Transactions. ROTs require a write of a timestamp on each object touched by the transaction. This is important for safety to make sure all new writes are ordered after the read-only transaction, so this version update of an object must be durable. We think that this may have a negative impact on performance, as each read includes a disk write in its path.
3) Evaluation. The group had some questions about the evaluation. In particular, the TPC-C benchmark is scaled with respect to districts. typical TPC-S benchmark tries a different number of warehouses, not districts. That being said, districts and warehouses are linked: “Each warehouse in the TPC- C model must supply ten sales districts.” This however raises additional questions, as 20 districts translate to just 2 warehouses, whereas many transactional papers go into 10s or even hundreds of warehouses.