In the 122nd reading group meeting, we read “The Case for Distributed Shared-Memory Databases with RDMA-Enabled Memory Disaggregation” paper by Ruihong Wang, Jianguo Wang, Stratos Idreos, M. Tamer Özsu, Walid G. Aref. This paper looks at the trend of resource disaggregation in the cloud and asks whether distributed shared memory databases (DSM-DBs) can benefit from memory disaggregation (MD) to become the next “hot” thing in the database world.
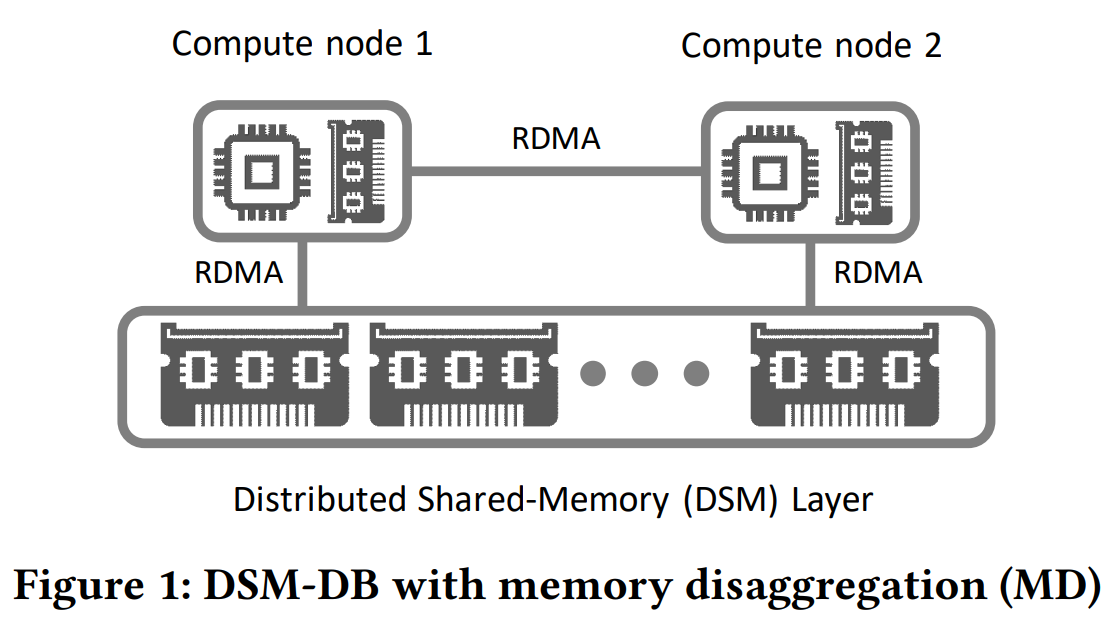
The idea, on the surface, is simple — decoupling compute from memory enables the creation of databases with many separate stateless compute workers for query processing that share a remote memory pool. According to the authors, the driving force for this is RDMA, as it allows relatively comparable latency and bandwidth to local memory. On top of that, such a system can also use disaggregated storage for durability. The bulk of the paper then focuses on challenges for such disaggregated design without going in-depth into the database architecture itself. The paper also does not go deeply into the design of the disaggregated memory system, although it points to a few issues to solve.
The first challenge listed by the authors is the lack of appropriate APIs to access memory. In particular, the paper suggests having APIs that are more in line with how memory is managed locally — memory allocation APIs. In this disaggregated memory pool case, the memory allocation must work with the virtual address space of the memory system. The authors also suggest data transmission APIs facilitate moving data for local caching at compute nodes. Finally, function offloading API can move some simple compute to the memory systems (does not this defeat the purpose of memory and compute disaggregation?)
The second important set of challenges deals with the disaggregated memory system itself. How does such a system handle node failures and still remain available and durable? Sadly, the paper does not provide any concrete details aside from hinting at high-level solutions, all of which will cost the performance — backup on storage, erasure coding, replication, etc.
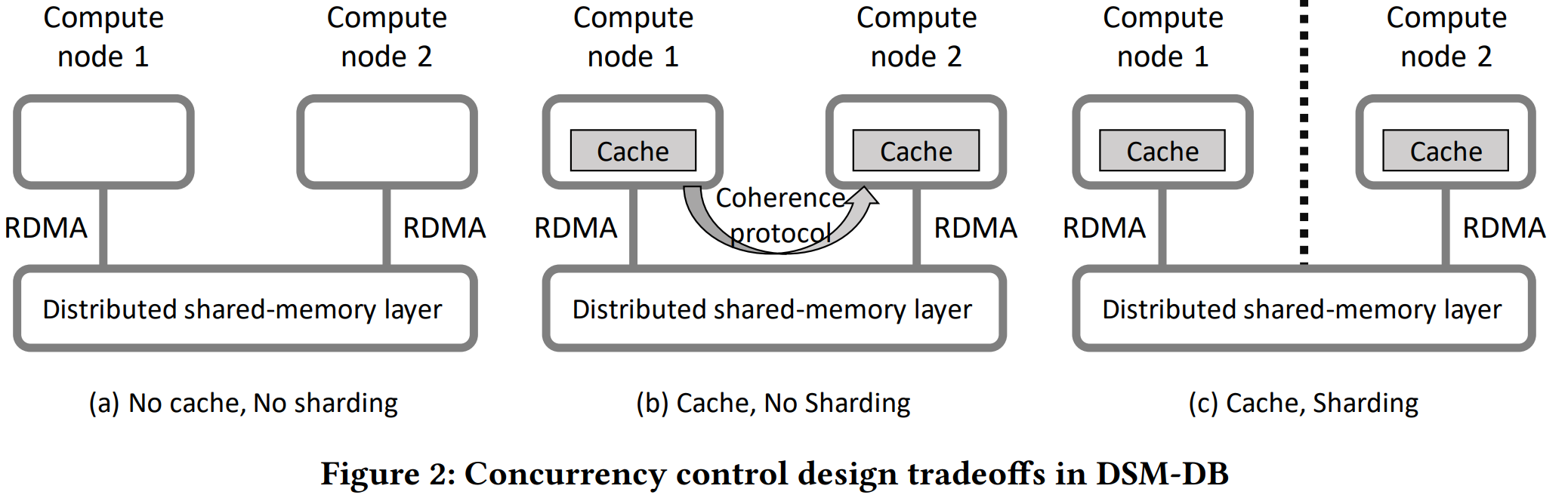
The third block of challenges has to do with concurrency control. If the database system caches data locally at worker/compute nodes, then we need to worry about cache coherence when multiple workers can access the same memory. Here we see that memory disaggregation is still slow — local cache can be an order of magnitude faster. This is a smaller difference than, let’s say, going from SSD to memory, but it is still substantial. Authors suggest that reduced speed differences in this new memory hierarchy will require new caching protocols, prioritizing execution time and not cache hit rate.
Another concurrency challenge has to do with transactions, as now we have the potential to fit all data in one large memory pool with many workers accessing it concurrently. Again, the paper does not have many concrete solutions but suggests “rethinking distribute commit.” Similar is the “solution” for concurrency control. It is costly to implement locks over RDMA, so we need to rethink CC as well, preferably without locks. Lastly, this all needs to work with thousands of compute nodes.
The last set of challenges is indexing-related. This, again, can get into the tricky RDMA performance limitations, so we need to have an RDMA-conscious index design. Also, the index needs to work well under high concurrency.
Discussion
1) Details. Our group collectively found the paper to be rather shallow on details of how these systems may work. While the paper examines some literature on the shared memory databases of the past, it lacks depth and connections with this new paradigm of disaggregated memory used over RDMA. We are especially curious about more depth for concurrency issues and solutions, as many stated issues may have been solved in prior shared memory databases, albeit at a smaller scale.
One example where the paper is very shallow is disaggregated memory system itself. Stating there are challenges with availability and durability in a core component for all DSM-DBs is not going to cut it — the entire premise of the paper depends on such a disaggregated memory system to be fast and reliable. Without these basics, the rest of the discussion becomes largely irrelevant.
2) Memory Disaggregation. We discussed the memory disaggregation idea in general and whether it can become a mainstream technology. See, storage disaggregation is kind of ubiquitous — you create a VM in some cloud, be it AWS or Azure or GCP, and the storage this VM gets is likely to be in a different box (or rather a set of boxes) than your VM’s CPU or memory (think of EBS volumes on AWS EC2). We are ok with this, as this storage is plenty fast and behaves just as if it was located in the same servers as the rest of the virtual hardware. This whole memory disaggregation with RDAM does not work this way, creating a lot of challenges. Most importantly, this disaggregated memory cannot be made (yet?) as universal as disaggregated storage. We won’t run code from it or use it for anything that needs to copy/change contents a lot. As a result, this disaggregated memory, at best, will look like another “storage” solution to systems that use it — something that may be faster than durable storage, but still not fast enough for general use.
Personally, I see more utility in the future with memory disaggregation using CXL. There was a paper at the recent USENIX ATC on the topic. Such a solution may act more like additional memory on-demand that a shared pool of memory between processors/nodes, but it will also not have issues with cache coherence, difficulty, and limitation of RDMA and RDMA’s reliability. I can envision a top-of-rack memory pool, that tenants can tap into if they need more memory or if we need to have a cloud VM product that can scale memory and CPU cores independently of each other.