Our 82nd reading group paper was “Running BGP in Data Centers at Scale.” This paper describes how Facebook adopted the BGP protocol, normally used at the Internet-scale, to provide routing capabilities at their datacenters. They are not the first to run BGP in the data center, but the paper is interesting nevertheless at giving some details of how BGP is used and how Facebook data centers are structured. As a disclaimer, I am not a networking person, so I will likely grossly oversimplify things from now on.
BGP protocol provides routing service between different Autonomous Systems (ASes). These ASes are some contained networks. For example, on the internet, an ISP network may be its own AS. The protocol relies on peering connections to discover different ASes and what addresses are contained/reachable in these ASes. With this information, the protocol can route the packets to the destination ASes.
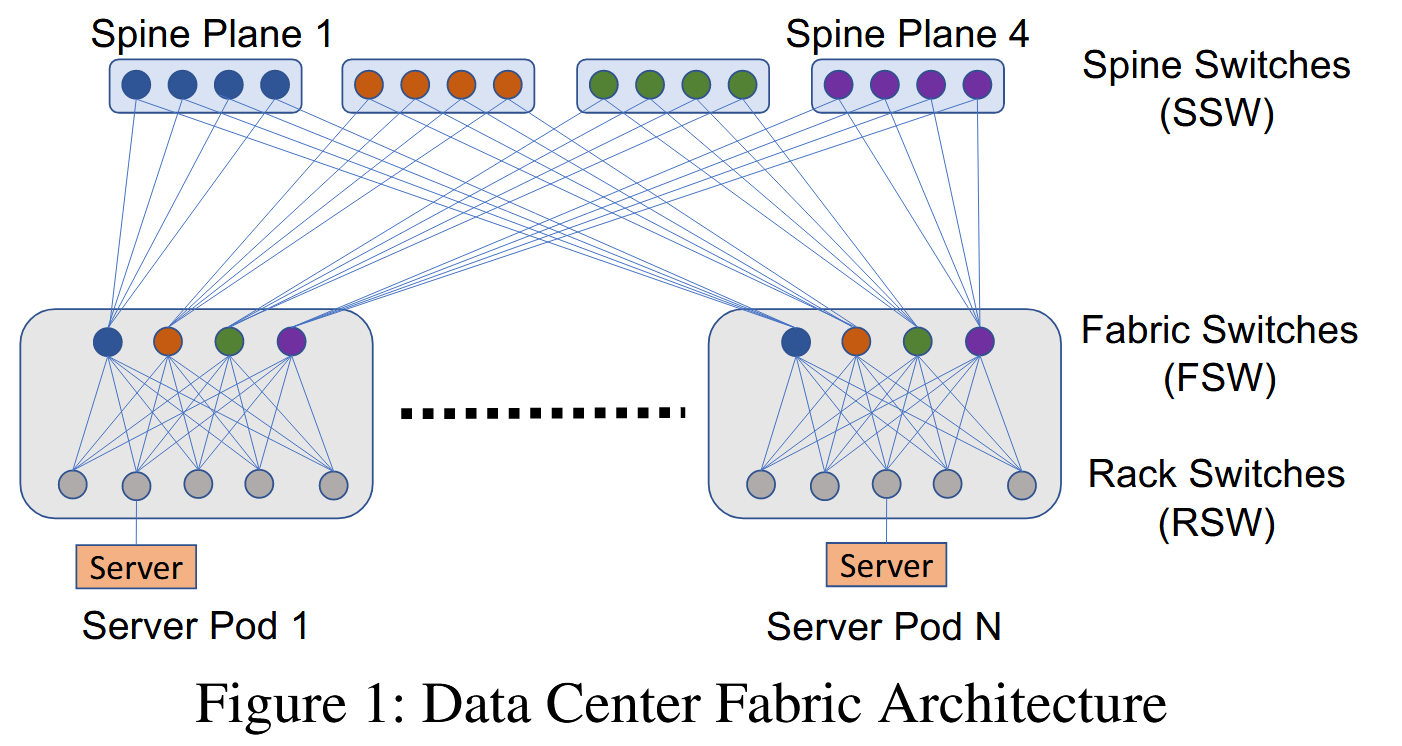
BGP is a kind of high-level protocol to route between ASes, but how the packets navigate inside each AS is left to the AS itself. Facebook uses BGP again inside its data centers. Here, a bit of Facebook’s data center architecture can help with the story. As seen in the image I borrowed from the paper, the data center consists of multiple “Server Pods,” and Server Pods are connected to each other via multiple “Spine Planes.” Each Server Pod has Fabric Switches (FSWs) that communicate with the Spine Plane, and Rack Switches (RSWs) that can reach individual servers.
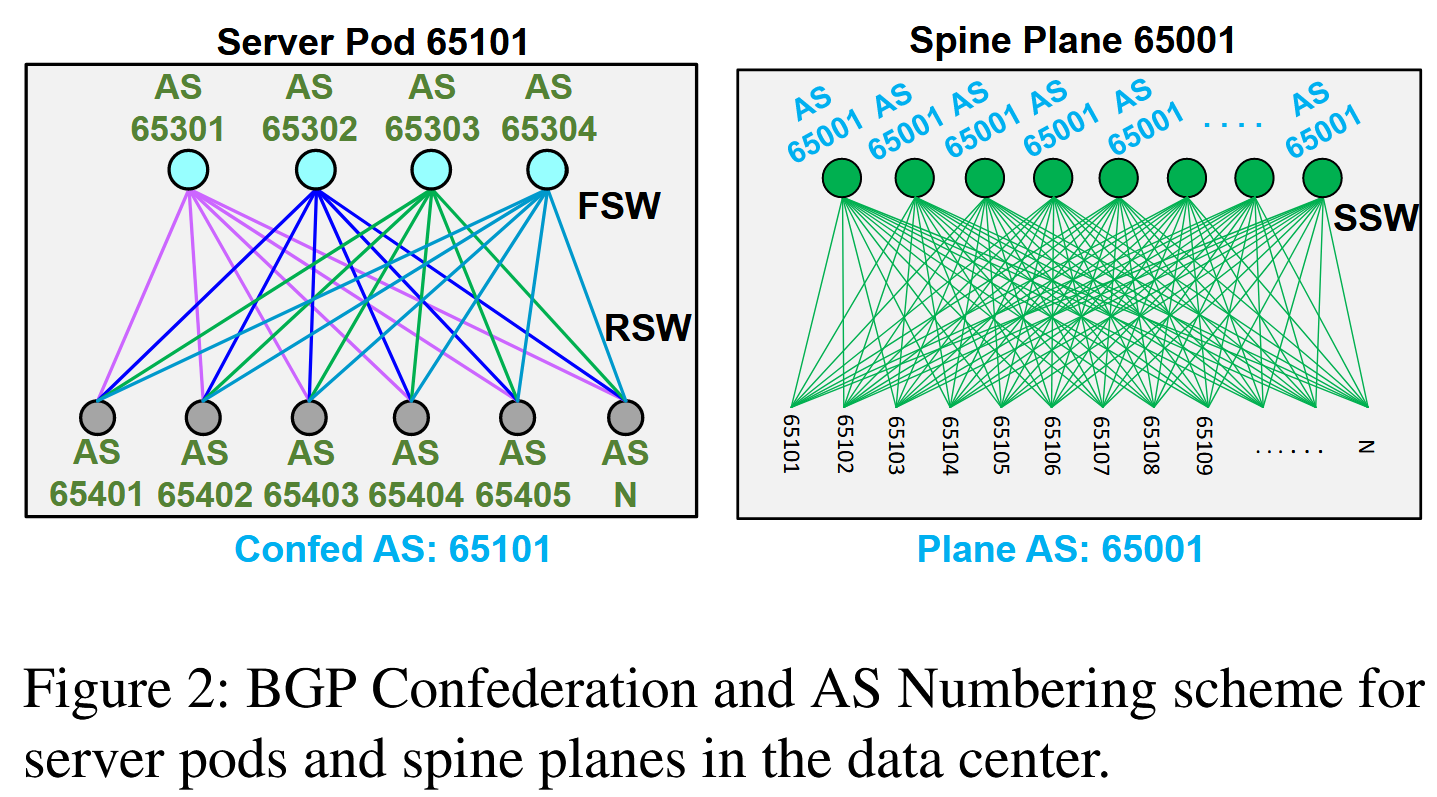
Each Server Pod is given an AS number and further subdivided into sub-ASes, with different Rack Switches having theirs AS numbers. Similarly, Fabric Switches also have their AS numbers. This concept of hierarchically dividing ASes into sub-ASes is often referred to as BGP confederations. Anyway, the AS numbering is kept uniform in Facebook datacenters. For instance, the first Spine Plane is always given the number 65001 in each data center. Similar uniformity exists with Server Pods and their sub-ASes. Such uniformity makes it easier to develop, debug and troubleshoot the network.
Unlike the Internet use of BGP, Facebook has complete control over all of the ASes in their datacenter network. This control allows them to design peering and routing policies that work best in their specific topology. For instance, “the BGP speakers only accept or advertise the routes they are supposed to exchange with their peers according to our overall data center routing design.” The extra knowledge and uniformity also allow the system to establish backup routes for different failures. These backup routes can be very carefully designed to avoid overloading other components/networks or causing other problems.
The system design is also scalable. Intuitively, adding more servers should be as simple as adding another Server Pod to the network. The hierarchical nature of the BGP confederations means that a Pod can be added easily — the rest of the network only needs to know about the Pod and not all the ASes inside the Pod.
The paper talks about quite a few other details that I have no time to list or mention all of them. However, a few important parts stuck with me. First is the implementation. Facebook uses a custom multi-threaded implementation with only the features they need to support their data center networks. The second point I want to mention has to do with maintainability. Testing and deployment are a big part of the reliability and maintainability of the network. The entire process is approached similarly to the regular software development and deployment process. New versions are tested in simulations before proceeding to the canary testing and, finally, before gradual production roll-out. Recently I have been going through a bunch of outage reports for one of my projects, and some of them mention “network configuration change” as the root cause of the problem. I think these “configuration change” issues could have been mitigated with proper testing and deployment processes.
We had our group’s presentation by Lakshmi Ongolu, available on YouTube: