In our recent reading group meeting, we discussed “Aggregate VM: Why Reduce or Evict VM’s Resources When You Can Borrow Them From Other Nodes?” by Ho-Ren Chuang, Karim Manaouil, Tong Xing, Antonio Barbalace, Pierre Olivier, Balvansh Heerekar, Binoy Ravindran. This EuroSys’23 paper introduces the concept of Aggregate VM to allow the pooling of small unused chunks of resources from multiple physical servers to create one VM.
We had no volunteer for this paper, so I put a quick presentation myself:
The problem Aggregate VMs solve is resource fragmentation. Let’s say a cluster has some unused resources, such as CPU and memory, lying around on multiple servers. These may be too small for a bigger VM, yet abundant across many physical servers. The authors propose pooling these smaller chunks of resources together into one bigger VM. For instance, getting 1-core and 2 GB of RAM from 3 physical servers to create a 3-core VM with 6 GB of memory.
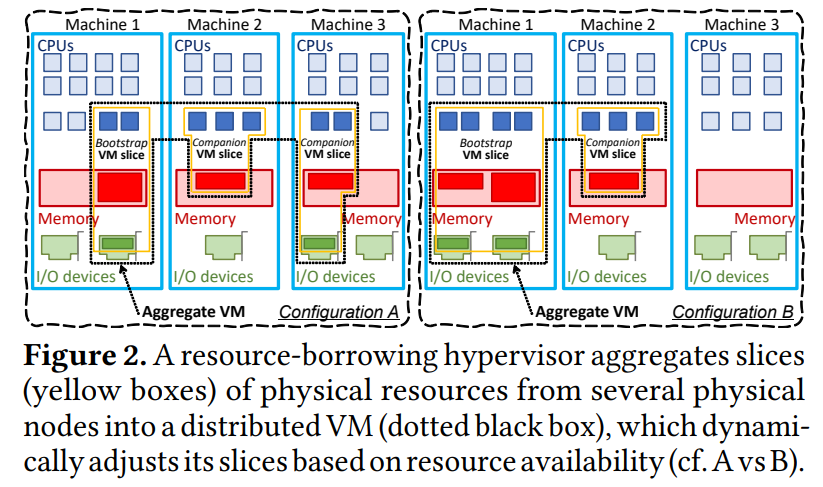
From the get-go, this may not sound like a good idea for performance, given the disaggregation of memory and compute resources over the network. The paper is very defensive about this topic and identifies several workloads where this may not be a problem — the key is to have workloads that require little memory sharing between threads, as sharing memory between cores on different physical servers over the network would be a disaster for performance.
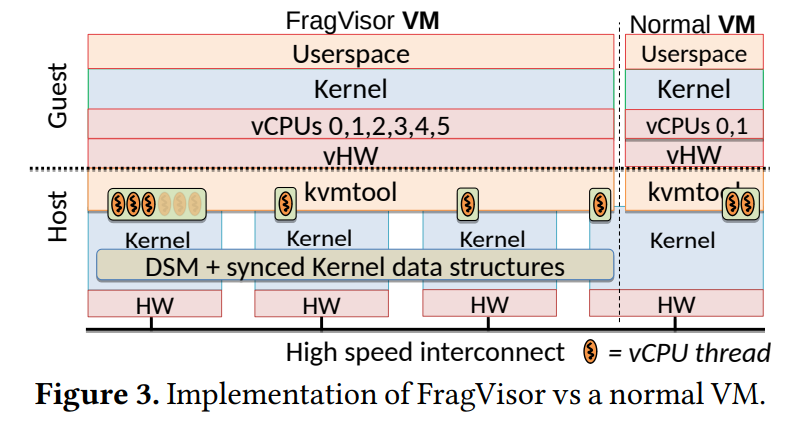
The paper introduces a new FragVisor, a new hypervisor built on top of KVM and Distributed Shared Memory (DSM). FragVisor runs on that DSM layer; however, FragVisor nodes on different physical servers can also communicate with messages passing over the network. Without going into too many details, the DSM and the behind-the-scenes FragVisor communication enables the Aggregate VMs. The FragVisor communication glues the individual FragVisor nodes into one hypervisor. The DSM acts as a single address space for the guest OS, divided into multiple NUMA domains to let the guest OS know of memory speed limitations and boundaries. The paper also talks about several optimizations to DSM to get better performance for the guest OS.
One important aspect I want to discuss is sharing IO devices, such as network cards, between physical fragments. See, if the aggregate VM has access to a network interface on one physical node, the other node needs to leverage DSM to interact with that network card — the card may have send/receive ring buffers in memory. These buffers, however, become the points of memory sharing, slowing down the Aggregate VMs. The paper proposes using a multi-queue interface, so each core (or at least a physical server?) has its own send and receive buffers. This way, while buffers still rely on DSM, cross-core (or rather cross-server) sharing of buffers is avoided. The paper also explores the idea of DSM-bypass for these tasks, avoiding relying on DSM for managing such buffers and using FragVisor message exchange capability instead.
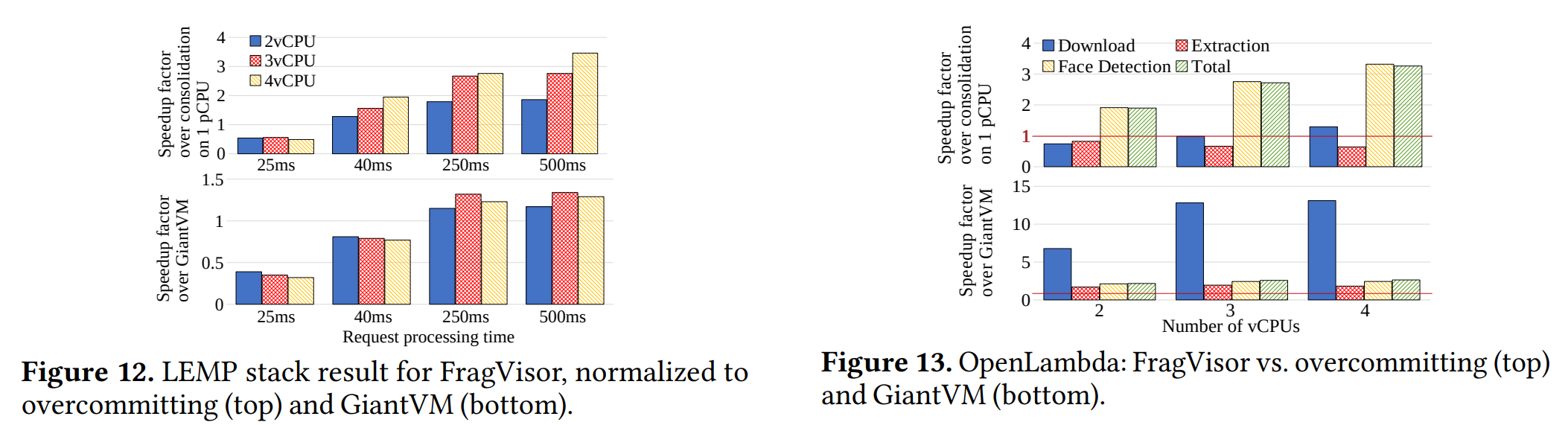
I will not go into the details of the performance evaluation too much and just show a few use cases. In both use cases, the paper compares the Aggregate VM against the overprovisioned VM running on one physical core (so, a 4 vCPU overprovisioned VM still has only one physical core). There is also a comparison against GiantVM, another disaggregated VM solution meant for gluing bigger chunks of resources, as opposed to FragVisor’s smaller fragments. The LEMP workload simulates the php-serving application; it is a workload that avoids memory sharing, as different concurrent requests to serve a page are independent. In this workload, when page render time is larger (i.e., 250+ms), AggregateVMs show nearly linear improvement from having more cores. However, the improvement in OpenLambda varies depending on the task, and in some instances, an overprovisioned VM still runs faster than an aggregate one.
Discussion
1) Motivation. The primary motivation for the paper is resource fragmentation. The idea is that fragments cannot be used for a primary VM unless we aggregate them together. But this runs into a problem evident right from the title of the paper. The authors claim that current solutions to fragmentation are spot VMs and Harvest VMs. According to the paper, the problem with these VMs is that they can get evicted or destroyed, unlike aggregate VMs that can morph and use the resources of multiple servers during their lifetime. However, if a server can support a large enough spot VM, then it can support the same size primary VM, eliminating the need for the Aggregate VMs. In my opinion, spot VMs solve a different problem: getting some revenue or work done from spare capacity kept in the cluster to accommodate load and demand fluctuations. These fragments may exist there on purpose! The Aggregate VM motivation is based on the premise that these fragments are accidental and otherwise unusable.
I am not saying excessive fragmentation is not a real problem; the paper has impressive references claiming up to 17% fragmentation in some clusters and millions in lost revenue due to fragmentation. However, while unused resources are lost income, I think this is done at least partly on purpose. Furthermore, having evictable resources may be the only way to both use the reserves for something and have the spare capacity to accommodate demand changes.
2) Why not use smaller VMs? Since aggregate VMs favor embarrassingly parallel tasks with little-to-no memory sharing between cores, then why do we need bigger VMs? Why not use many smaller ones such that each smaller VM sits in one physical server? Of course, there are some overheads, like having many copies of OS and managing a larger fleet of VMs, but somehow it still feels like a plausible solution to workloads that run okay on aggregate VMs.
3) IO sharing. The multi-queue stuff is an interesting way to reduce memory sharing from having a single IO device/interface. However, it may be hard to make it in a dynamic environment as the authors propose, where VMs can fluctuate between physical servers and their numbers. This can require quite a bit of readjustment in the buffers and can be complicated.