This week, our reading group focused on serverless computing. In particular, we looked at the “Palette Load Balancing: Locality Hints for Serverless Functions” EuroSys’23 paper by Mania Abdi, Sam Ginzburg, Charles Lin, Jose M Faleiro, Íñigo Goiri, Gohar Irfan Chaudhry, Ricardo Bianchini, Daniel S. Berger, Rodrigo Fonseca. I did a short improvised presentation since the scheduled presenter was a “no show.”
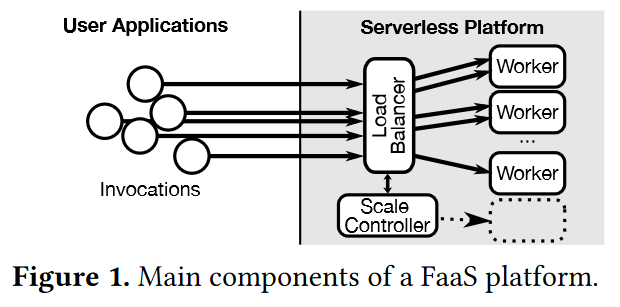
This is a very simple paper. I like simple papers, and this one is not an exception. Serverless functions or Functions-as-a-Service (FaaS) is a computing paradigm and resource abstraction that allows developers to write their code (i.e., functions), submit it to the cloud, and have the cloud run the code whenever it is needed or invoked. The developers have no control over where the code runs physically, but in return, they get managed, scalable (cloud can run many instances of the code in parallel), and pay-as-you-go platform.
Serverless functions have several limitations. One of which is the stateless nature of the functions, as any local state does not persist between invocations. The logic for this is simple — any two invocations of the same code may run on different worker nodes without any placement control on the user’s side. As a result, any state a function needs must be loaded from an external service like a database or a blob storage and any side effects persisted to the external service.
This creates some inefficiencies for many applications. Consider a social media example where a function needs to retrieve a social media post, among other things. If a post is popular enough, numerous function invocations will load up that same post many times over, costing the app some latency and exerting extra load on a storage system or cache. An optimistic approach would be to cache the post at the worker node and hope that the next invocation that needs the post will, by chance, get to the worker that has it cached.
The Palette paper takes the “cache at the worker” approach but makes the placement of function invocations aware of the worker cache. In particular, the Palette allows users to “color” function invocations such that similar invocations get the same color. Then, instead of using a simple load balancer on the serverless platform side, the system uses the color-aware load balancer that tries to send all invocations of the same color to the same worker (or set of workers).
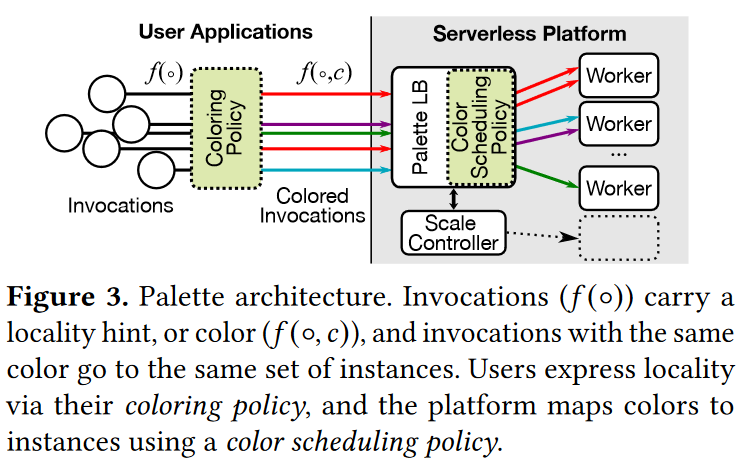
Of course, the color is just an abstraction for something that determines the similarity of invocations. For instance, in the social media example, the “color” of a function invocation may be the post ID, causing the system to send all invocations to the same set of workers that will likely cache the post. The coloring, however, is left to the users to define, for example, based on the function parameters used in the invocation.
The paper discusses several strategies for mapping colors to workers. These strategies boil down to consistent hashing or simply assigning workers to any new colors and remembering such assignments for later function calls.
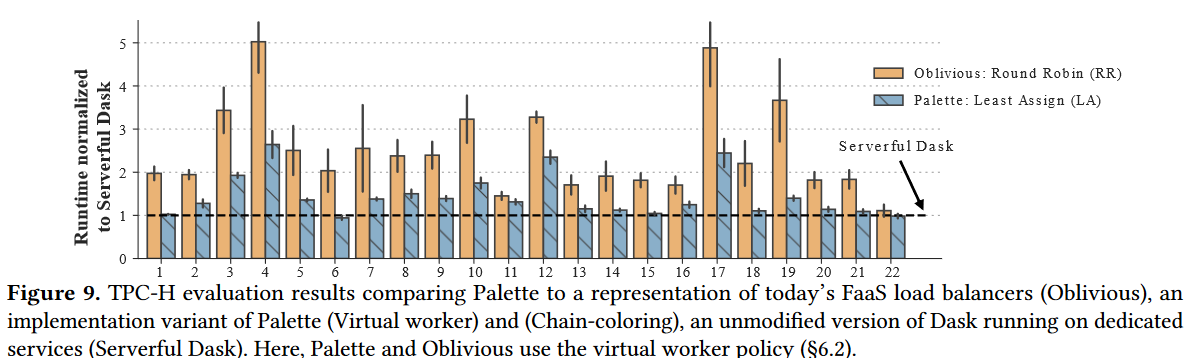
As far as evaluation, the authors compare Palette in several data-intensive workloads and use a serverful baseline to illustrate how caching can help many of these tasks get closer to the serverful baseline in performance.