We discussed “Multitenancy for Fast and Programmable Networks in the Cloud” in the 59th DistSys Reading Group meeting. In a sense, this was a continuation of a previous discussion we had a few months ago when covering Pegasus paper.
Pegasus and many other new protocols rely on specialized programmable network hardware that is not yet available to regular cloud users. This is because such hardware has no support for multitenancy and cannot be efficiently shared and virtualized to allows cloud users to get a virtual slice of the hardware pie. This paper discusses enabling multitenancy on today’s smart network hardware, such as smart switches.
It is not an easy feat to pull off — these switches (in the paper, the authors used a switch based on Barefoot Tofino logic) have limited programmability, limited resources, and can run just one program. Of course, if you can have only one running program, it is hard to run code from different users/tenants. The paper works around this by compiling the code from all tenants together into one “jumbo-program” that can run on the switch. This tenant packing also solves an issue with resource sharing and isolation as the switch’s hardware resources must be defined at the compile time. Of course, there are also issues isolating tenant’s code. This is done at compile time too by renaming the tenant program’s fields, such as tenant-defined headers and table names to the tenant-unique names. A few restrictions are placed on tenants for the sake of isolation, and the paper goes into more detail. One important assumption is that the tenants are expected to be isolated based on their virtual networks (VLANs).
In addition to being the glue that holds all the tenants together, the “jumbo-program” incorporates some “system” code to provide common functionality. For instance, the “system” program can process common packet headers. This allows it to read VLAN ID (ID) and then invoke proper tenant so that the tenant code can do its own header matching/parsing.
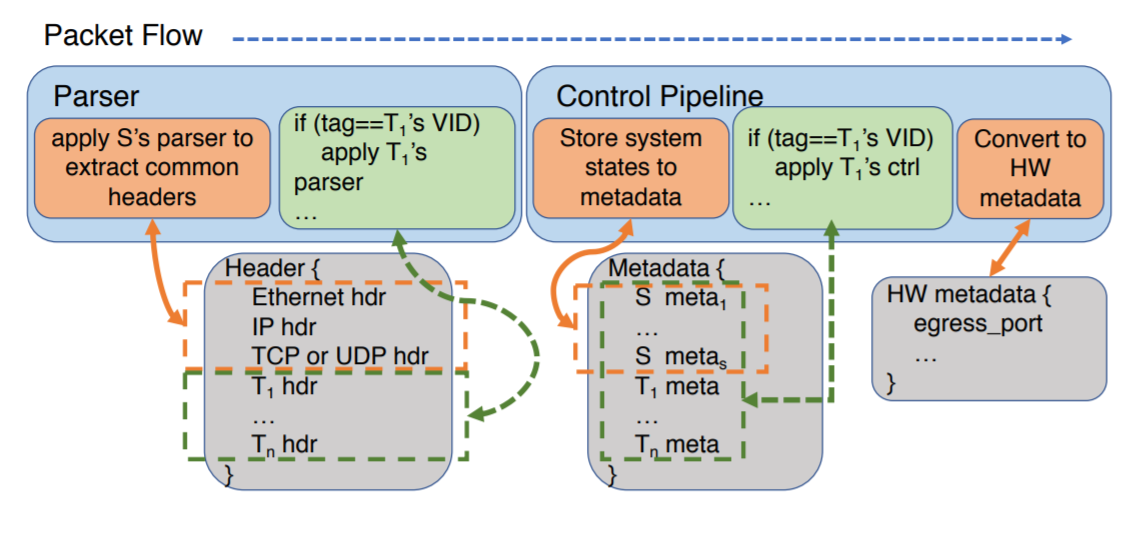
The “system” program of a “jumbo-program” also helps us deal with one tricky part here. See, the program on a switch needs to run at the network line speed, and cannot delay any packets, so there is no way to delay any processing. This means that the program runs as a pipeline in multiple stages with no way of returning to a previous one. The “system” program “sandwiches” the tenant program and in a sense establishes some rules and bounds for the tenants.
I already mentioned that the resources are defined/allocated ahead of time. This is also true for memory, as programmers must hardcode the array sizes of stateful memory they want to use. However, the paper works around this by kind of building a virtual memory in the system program of the “jumbo-program”. The “jumbo-program” just allocates a huge array of memory in each pipeline stage and uses a configuration stage to store the memory boundaries for each tenant. Tenants use the boundaries as index offsets into the big array, essentially implementing virtual memory within the “jumbo-program”, and allowing for dynamic memory reallocation by adjusting these memory offsets.
The paper has its HotCloud presentation. And as usual, we had our own presentation, this time by David Correa:
Discussion
1) Other approaches? The paper mentions some alternatives to the switches they have used. For example, software switches are a lot easier to program. FPGAs can be used for handling some network functions as well. But, according to the paper, these are all slower. ASICs, like Barefoot (now owned by Intel) Tofino, are a lot faster, but with such speed, they are more limited. The programmability constraints, the pipeline processing nature, memory limitations (22 MB of SRAM), etc. are big limiting factors though.
2) Hardware-specific solution. So the solution presented here is rather specific for the hardware available now. This is cool, but I’d want to imagine what can be done in the near future. Can we improve the hardware to reduce these limitations? The authors conjecture that the pipelines will stay: “we expect ASIC-based pipelines—both for switches and NICs—to be more effective than other programmable architectures in terms of both cost and power consumption.” However, maybe somehow better support for multi-tenancy can be backed to a new generation of devices on the hardware level, along with greater flexibility of adding/removing tenants.
3) Not quite cloud-ready? The major pain point of the solution seems to be the need to “mush together” all the tenants before compiling the program and deploying it on the switch. If tenants change (or tenant’s requirements for some hardware resources) the whole thing needs to be repackaged and re-deployed. This sounds like a cumbersome process that may result in some downtime while the new “jumbo-program” is deployed on the network. Exposing this process as some kind of cloud service seems quite infeasible due to these issues. It would have been nice if more resources could have been reallocated between tenants dynamically (of course, we are not experts here, but there may be some real hardware/performance limitation for this very static approach). It would also be nice to have the ability to “side-load” new tenant programs into the “jumbo-program” runtime.
4) Incentives for the cloud providers? Smart network devices can greatly benefit those who have access to them. We are starting to see many systems relying on these. However, right now, cloud providers are those who have access to such hardware, and it may provide some advantage to these providers and their native services. As such, there may be little incentive to offer these resources in the cloud. That being said, this may also play the other way around. If this becomes a very desired feature, the first cloud provider to offer these virtualized multi-tenant switches stand to benefit, and other providers will follow in the chain reaction of chasing the market.