Our 72nd paper was on avoiding coordination as much as possible. We looked at the “Meerkat: Multicore-Scalable Replicated Transactions Following the Zero-Coordination Principle” EuroSys’20 paper by Adriana Szekeres, Michael Whittaker, Jialin Li, Naveen Kr. Sharma, Arvind Krishnamurthy, Dan R. K. Ports, Irene Zhang. As the name suggests, this paper discusses coordination-free distributed transaction execution. In short, the idea is simple — if two transactions do not conflict, then we need to execute them without any kind of coordination. And the authors really mean it when they say “any kind.”
In distributed transaction processing, we often think about avoiding excessive contention/coordination between distributed components. If two transactions are independent, we want to run them concurrently without any locks. Some systems, such as Calvin, require coordination between all transactions by relying on an ordering service to avoid expensive locks. Meerkat’s approach is way more optimistic and tries to avoid any coordination, including ordering coordination. Meerkat is based on Optimistic Concurrency Control (OCC) with timestamp ordering to enable independent transactions to run without locks and ordering services. Another innovation for avoiding coordination is the replication of transactions from clients straight to servers. Instead of relying on some centralized replication scheme, like Multi-Paxos or Raft, Meerkat lets clients directly write transactions to replicas, avoiding replication coordination and leader bottlenecks. The authors explored this “unordered replication” idea in their previous paper. The clients also act as the transaction coordinators in the common case.
Meerkat does not stop its coordination avoidance efforts here at the cross-replica coordination. In fact, this is where the most interesting magic starts to happen — the authors designed a good chunk of a system specifically to avoid the cross-core coordination within each server to take advantage of modern multi-core CPUs. The authors call such avoidance of cross-core and cross-replica coordination a Zero Coordination Principle or ZCP for short.
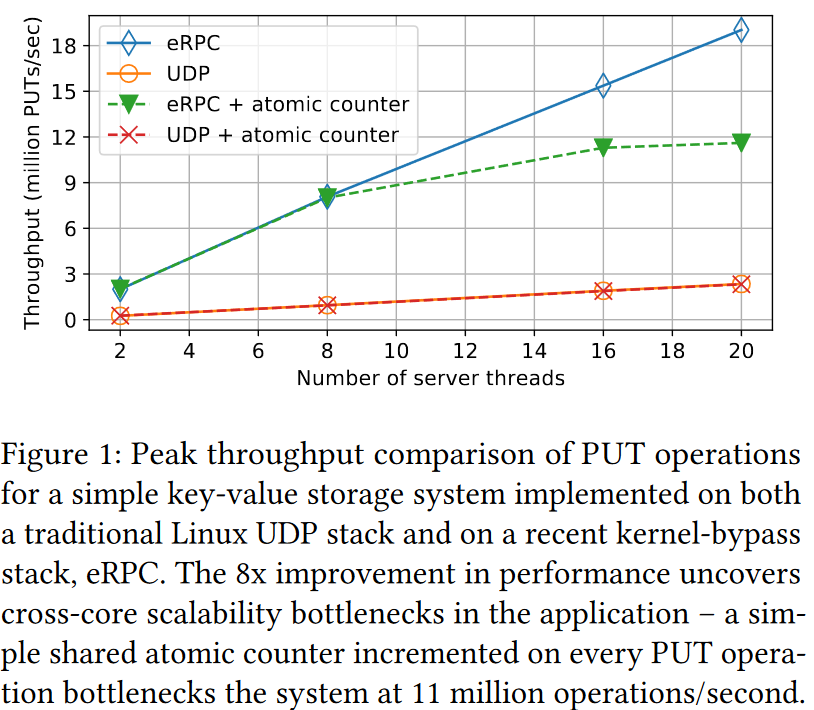
As a motivating example for ZCP and the need for cross-core coordination avoidance, the paper illustrates the contention created by a simple counter shared between threads on one machine. It appears that with the help of modern technologies to alleviate networking bottlenecks (kernel bypass), such a shared counter becomes an issue at just 8 threads. In the example, a simple datastore with a shared counter could not scale past 16 threads, while a similar store without a shared resource had no such problems.
Let’s talk about the protocol now to see how all the coordination-avoidance efforts actually work. The system tolerates \(f\) failures in the cluster of \(2f+1\) machines. Each transaction can read and write some set of objects supported by the underlying key-value store. These objects represent the transaction’s read- and write-sets. The replicas maintain two data structures to support transaction processing: a trecord and a vstore.
The trecord is a table containing all transaction information partitioned by the CPU core ID to make each transaction “sticky” to a single core. It manages the transaction state, such as the read- and write-sets, transaction version timestamp, and commit status. The vstore stores versioned key-value pairs. Unlike the trecord, the vstore is shared among all cores at the server. The transaction protocol runs in 3 distinct phases: Execute, Verify, Write. I’m not sure these are the most intuitive names for the phases, but that will do.
In phase-1 (execute), the transaction coordinator (i.e., a client) contacts any replica and reads the keys in its read-set. The replica return versioned values for each key. The coordinator then buffers any pending writes.
The phase-2 (validation) combines the transaction commit protocol with replication of transaction outcome. The coordinator starts phase-2 by first selecting a sticky CPU core that will process the transaction. The sticky core ID ties each transaction to a particular CPU core to reduce inter-node coordination. The coordinator then creates a unique transaction id and a unique timestamp version to use for OCC checks. Finally, the coordinator sends all this transaction information to every replica in a validate message.
Upon receiving the message, each replica creates an entry in its trecord. The entry maintains the transaction’s state and makes this transaction “stick” to the core associated with the core-partitioned trecord. At this point, the replica can validate the transaction using OCC. I will leave the details to the paper, but this is a somewhat standard OCC check. It ensures that both the data read in phase-1 is still current and the data in the write-set has not been replaced yet by a newer transaction. At the end of the check, the replica replies to the coordinator with its local state (OK or ABORT).
The coordinator waits for a supermajority (\(f+\lceil\frac{f}{2}\rceil+1\)) fast-quorum of replies. If it receives enough matching replies, then the transaction can finish right away in the fast path. If the supermajority was in the “OK” state, the transaction commits, and otherwise, it aborts.
Sometimes a supermajority fast-quorum does not exist or does not have matching states, forcing the coordinator into a slow path. In a slow path, the coordinator only needs a majority of replicas to actually reply. If the majority has replied with an “OK” state, the coordinator can prescribe the replicas to accept the transaction, and otherwise, it prescribes the abort action. Once the replicas receive the prescribed transaction state, they mark the transaction accordingly in their trecord and reply to the coordinator. Here, the coordinator again waits for a quorum before finalizing the transaction to commit or abort.
Finally, in phase-3 (write), replicas mark the transaction as committed or aborted. If the transaction is committed, then each replica can apply the writes against the versioned datastore.
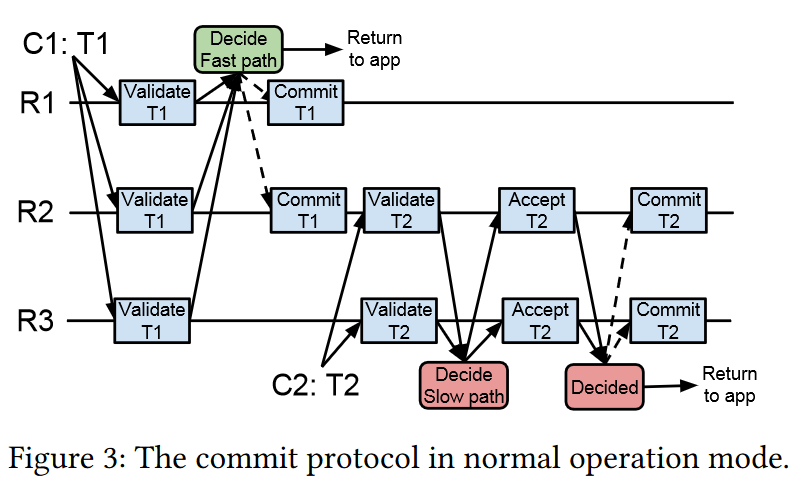
Phew, there is a lot to unpack here before diving deeper into the corner cases and things like replica and coordinator failures and recovery. The important parts relate to how the coordination is handled/avoided. To start, the coordinator uses a timestamp for the version, circumventing the need for a counter or centralized sequencer. The transaction replicates with its timestamp directly by the coordinator (who happens to be the client in the normal case) to the replicas, avoiding the need for a centralized replication leader or primary. At the server level, each transaction never changes its execution core even as it goes through different phases. All messages get routed to the core assigned to the transaction, and that core has unique access to the transaction’s trecord partition. This “core stickiness” avoids coordination between the cores of a server(!) for the same transaction. I speculate here a bit, but this may also be good for cache use, especially if designing individual transaction records to fit in a cache line. As a result, the only place the coordination happens between transactions is the OCC validation. During the validation, we must fetch current versions of objects from the core-shared vstore, creating the possibility for cross-core contention between transactions accessing the same data.
I do not want to go too deep into the failure recovery; however, there are a few important points to mention. The replica recovery process assumes replicas rejoin with no prior state, so they are in-memory replicas. The recovery process is leader-full, so we are coordinating a lot here. And finally, the recovery leader halts transaction processing in the cluster. As a result, the recovery of one replica blocks the entire system as it needs to reconcile one global state of the trecord that can be pushed to all replicas in a new epoch. I will leave the details of the recovery procedure to the paper. However, intuitively, this over-coordination in recovery is needed because the normal operation avoided the coordination in the first place. For example, state machine replication protocols “pre-coordinate” the order of all operations. When a replica needs to recover, it can learn the current term to avoid double voting before simply grabbing all committed items from the log available at other nodes and replaying them. It can replay the recovered log while also receiving new updates in the proper order. In Meerkat, we have no single history or log to recover, so a pause to reconcile a consistent state may be needed.
The coordinator recovery is handled by keeping backup coordinators and using Paxos-like consensus protocol to ensure only one coordinator is active at the same time and that the active coordinator is in a proper state.
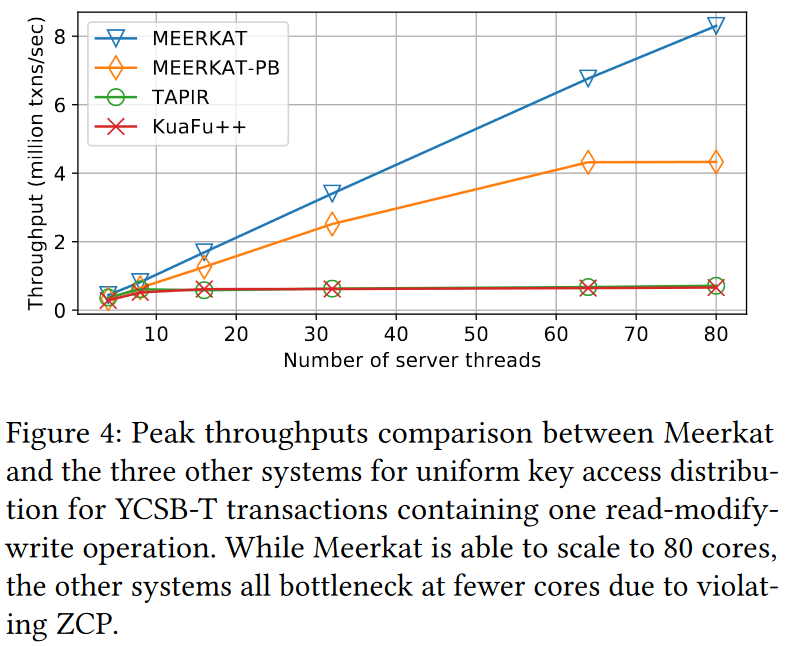
Now we can talk a bit about the performance. Meerkat significantly outperforms TAPIR, which is the previous system from the same group. The performance gap between the systems is huge. This begs a natural question about the performance. Just how much of Meerkat’s gain is due to a super-optimized implementation and utilization of techniques like kernel-bypass? Meerkat-PB in the figure can shed some light on this, as it represents a version of Meerkat with a dedicated primary for clients to submit transactions. Having a primary adds cross-replica coordination, and despite that, it still significantly outperforms the older systems.
As always, we had a presentation in the group, and it is available in our YouTube channel. This time, Akash Mishra did the presentation:
Discussion
Quite frankly, I have incorporated quite a bit of discussion into the summary already.
1) Performance. One of the bigger questions was about performance. How much of the “raw” speed is due to the ZCP, and how much of it is due to the enormous implementation expertise and use of kernel bypass and fancy NIC to deliver messages to proper cores/threads. We speculate that a lot of the overall performance is due to these other improvements and not ZCP. That being said, once you have an implementation this efficient/fast, even tiny bits of coordination start to hurt substantially, as evidenced by the motivation examples and even the primary-backup version of Meerkat.
2) Replica Recovery. The blocking nature of recovery may present a real problem in production systems, especially if the recovery time is substantial. It would have been nice to see the recovery evaluations.
3) Performance States. To continue with performance/recovery topics, it appears as the system can operate in multiple very distinct performance states. In the fast-quorum operation, commits come quickly. In the slow path, a whole new round-trip exchange is added (probably after the timeout). This creates distinct latency profiles for fast and slow paths. This can also create distinct throughput profiles, as a slow path sends and receives more messages, potentially creating more load in the system.
4) Sharded systems? Many systems use sharding to isolate coordination into smaller buckets of nodes or replica-sets. For example, Spanner and Cockroach DB do that. Such sharding allows independent transactions to run in separate “coordination pods” without interfering with each other. To scale these systems just need to create more such coordination pods. Of course, in systems like Spanner, transactions that span multiple replica-sets add another level of coordination on top, but the chance that any two shards need to coordinate is kept low by making lots of tiny shards. I wonder about the differences between two philosophies — avoiding coordination vs. embracing it, but in small groups. Are there benefits to “coordination pods”? Should we embrace ZCP? Can ZCP survive the scale of these larger sharded systems?
5) The need for supermajority quorum? Supermajority fast quorums often raise many questions. Just exactly why do we need them? The short answer here is fault-tolerance, or more specifically the ability to recover operations after failures. See, in majority quorum protocols that have a leader, we have at most one operation that can be attempted in the given epoch and log position. This means that if some replicas fail, we can recover the operation if we can guarantee to see the value in at least one replica. Any two majority quorums intersect in at least one replica, making the single operation recoverable as long as it has made it to the majority. Unfortunately, this does not work with leaderless solutions as illustrated by Fast Paxos, as many different values can be attempted in the same epoch and slot position. However, we still need to survive the failures and recover.
Let’s look at the example to illustrate this. Assume we have 5 nodes, 3 of which have accepted value “A” and 2 have value “B.” Let’s assume that we commit “A” at this time since we clearly have a majority agreeing on “A.” If 2 “A” nodes crash, we will have 3 live nodes remaining: “A, B, B.” By looking at these nodes we do not know the fact that value “A” might have been committed by the coordinator. We need a supermajority quorum to survive the failures and recover. If we commit with a supermajority of size \(f+\lceil\frac{f}{2}\rceil+1\) (4 out of 5 nodes) “A, A, A, A, B”, then failing 2 “A” nodes leaves us with 3 nodes: “A, A, B.” We see more “A” operations here and can recover “A.” In fact, if some value is in a supermajority, then any majority quorum will have the majority of its nodes (i.e. \(\lceil\frac{f}{2}\rceil+1\) nodes) having that value (but not the vice-versa — the majority value of a majority quorum does not mean the value was in the supermajority).
Now, how does this relate to Meerkat? Each Meerkat transaction has a unique id, so one may think we never have the possibility of committing two or more different transactions for the same id. However, we have to be careful about what Meerkat replicas need to agree upon. It is not the transaction itself, but a transaction status — OK or ABORT. So, we do have two possible values that can exist at different replicas for the same transaction. As a result, Meerkat needs a fast path supermajority quorum to make the transaction status decision recoverable in the replica recovery protocol.