This time around our reading group discussed a distributed filesystem paper. We looked at FAST’21 paper from Facebook: “Facebook’s Tectonic Filesystem: Efficiency from Exascale.” We had a nice presentation by Akash Mishra:
The paper talks about a unified filesystem across many services and use cases at Facebook. Historically, Facebook had multiple specialized storage infrastructures: one for hot blob storage, another for warm blobs, and another for analytics. While these systems were optimized for their specific purpose, they had a major drawback of resource overprovisioning. For example, hot storage needs to have a lot of IOs per second (IOPS) and may overprovision storage to get these IOPS, leaving storage resources wasted. On the other hand, warm/cold storage has opposite requirements — it needs more storage and fewer IOPS, leaving the IOPS unused. Tectonic, as a unified system, aims to avoid such resource overprovisioning and fragmentation. Having one system to serve different workloads creates several challenges. First, of all the single systems need to scale to support much larger storage capacities than several isolated systems. Second, it needs to work just as well as the purpose-build components it replaces.
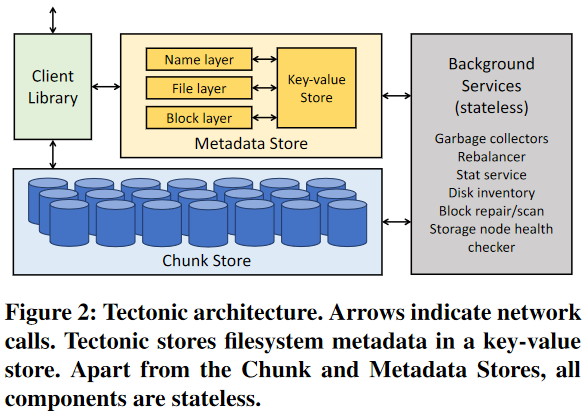
The storage backbone of Tectonic is Chunk Store. It stores chunks of data that make up logical blocks that make up files. Chunk Store is linearly scalable storage that grows with the number of storage servers. This largely covers the data and IOPS scalability of the file system on the hardware level. However, another limiting factor in large file systems is metadata management. As files are being accessed, the clients must first consult the metadata sub-system to locate blocks for the file and enforce other file system guarantees. One problem Facebook had with HDFS in their analytical cluster is limited metadata server scalability, and therefore tectonic avoids “single server” Metadata Store. Instead, all metadata is partitioned based on some directory hashes to allow multiple metadata servers to work at the same time. Furthermore, Tectonic implements the Metadata Store as a collection of micro-services over a Paxos-replicated key-value store, allowing different metadata requests to be processed by different metadata services of the same partition. The client library has all the logic that orchestrates interaction with the Metadata Stores and the Chunk Store. Placing the filesystem logic on the client-side allows for tenant-specific optimizations to better suit the workloads.
Having a unified filesystem for many services at Facebook allows for more efficient resource usage. Tectonic distinguishes between two resource classes: non-ephemeral resources (storage capacity), and ephemeral resources (IOPS). Storage capacity is provisioned to a tenant and remains at the provisioned level until a reconfiguration. Ephemeral resources (IOPS and metadata query capacity), however, can “move around” between tenants depending on the need. The resource sharing/allocation is controlled by a somewhat hierarchical system. A tenant selects a TrafficGroup for its application. The TrafficGroup is assigned to a TrafficClass, which controls latency requirements and decides the priority of allocating the spare resources.
As always, the paper has way more details!
Discussion.
1) Magnetic storage. Tectonic uses magnetic devices for storage. HDDs are much slower than SSDs, and a lot of new large storage systems are now targetting SSDs. We wonder how much of a design decision was influenced by the use of hard drives instead of SSDs. Resource sharing is a big part of the motivation and design of Tectonic, and since SSDs have different performance characteristics than magnetic storage (lower storage volumes, higher IOPS), these differences may have influenced the design of Tectonic or the entire need to have such unified system in the first place. Of course, at Facebook scale storage cost is a big consideration, and HDDs are cheaper. Cold/warm storage is a big part of Facebook’s architecture, so it makes sense to put infrequently used data on cheap disks and keep “hot” data in caches in the rest of the architecture stack.
2) Sharded metadata. The metadata store in Tectonic is sharded, meaning that there is no single coherent view of the metadata at any given time, as different directories (subdirectories) may be on different shards. This potentially creates the possibility for some consistency issues, especially for metadata operations that may span multiple shards. Another issue of sharded metadata is getting directory stats, as subdirectories may be in different partitions, so there is no perfectly correct/up-to-date view. But of course, sharded metadata allowed scaling the system horizontally much easier than a more centralized approach.
3) KV store for metadata. Metadata store is backed by a KV store. A lot of metadata fall naturally into the KV abstraction. For example, a key can be a directory name, and value is a list of its children. However, Tectonic does not store metadata in such a naive way. Instead, the value is expanded into the key. The need for this raised a few questions in the group. The basic here is avoiding the read and write (and a need for a transaction) when you need to append something to the list of values. In the expanded format, the value becomes a suffix of a key in the KV store, and adding something becomes as trivial as writing the key-value pair. Reading the entire list can be by scanning the store for a particular key prefix. Cockroach DB has a very good explanation of using KV storage to implement more complicated data models.
Paper has a few other examples of little performance tricks, like making some metadata records sealed or read-only to allow caching and partitioning schemes designed to avoid hotspots.
4) Client-driven. An interesting aspect of the system is that it is entirely client-driven in terms of all of its logic. From one point of view, this allows different clients to implement their custom protocols for using Tectonic. The paper has quite a bit of detail on how different tenants interact with the rest of the system differently to optimize for latency or throughput. On the other hand, this creates a possibility of client conflicts, if not managed properly. For instance, Tectonic allows a single writer per file and avoids ordering concurrent writes from different writers. However, this also means that if two clients are competing, the one who writes to the metadata server last and gets a token will be the sole writer, and any data written by a different client will be lost, even if it has been written to the chunk store. We feel like some of these decisions are in part because the product is internal to Facebook, and they have more control over how their engineers use it.
5) Comparison with other distributed FS. There are plenty of other distributed filesystems out there. Tectonic already compares itself somewhat with HDFS it replaced. Ceph is another popular one. It also has a more centralized, Paxos-replicated metadata service, which is good for consistency but may interfere with scalability. At the same time, Ceph clients (I think) cache the location of data, so maybe the need to query metadata is not very frequent. We also talked about comparing this to blob stores like S3, and extensions over S3, like EMRFS, for use as HFDS replacement. But these are not as general-purpose/flexible to fit multiple different use cases.
6) Verification. The paper does not mention any kind of formal verification done on Tectonic. One argument we had in the reading group is that Tectonic’s lax “eventual” consistency does not require checking. But this is not true, and there are plenty of opportunities to screw up even in the eventual consistency model (i.e. liveness issues, convergence, etc). Moreover, there are plenty more opportunities to make concurrency mistakes when using clients to build stronger consistency models on top. I think S3 was brought up again as an example of a team that verified the blob storage even before it was strongly consistent. We hope the some formal verification was done on a system this large and important, and that simply talking about it was outside of the scope of the paper.