We have covered 60 papers in our reading group so far! The 60th paper we explored was “Exploiting Symbolic Execution to Accelerate Deterministic Databases” from ICDCS’20. I enjoyed the paper quite a lot, even though there are some claims I do not necessarily agree with.
The paper solves the problem of executing transactions in deterministic databases. We can image a replicated state machine, backed by Paxos or Raft. Trivially, in such a machine, each replica node needs to execute the transactions following the exact order prescribed by the leader to guarantee that all replicas progress through the same states of the machine. The good thing here is that nodes run each transaction independently of each other after the execution order has been established by the replication leader. The bad thing is that this naive approach is sequential, so each node cannot take advantage of multiple processing cores it may have.
Naturally, we want to parallelize the transaction execution. This, however, is easier said than done. To allow for more parallelism, we want to identify the situations when it is ok to run some transactions concurrently without impacting the final state of the state machine. For example, if we know what objects or keys the transaction reads and writes (i.e. the transaction’s read-and-write set), we can group independent transactions that operate on disjoint read-write sets together for parallel execution. For instance, a transaction accessing keys “x, y, and z” is independent of a transaction accessing keys “a, b, and c,” and the two can execute at the same time without impacting each other.
Of course, this requires us to know what objects/keys each transaction needs before running them, and this is a bit of a problem. In some situations, it may be easy to figure out the read and write sets of a transaction, but this is not always the case. Many systems, like Calvin, do a “pretend run” of a transaction (this is sometimes referred to as a reconnaissance transaction) to figure out the read-and-write set if the set isn’t obvious or annotated in the transaction. This has a few obvious downsides. Obviously, the pretend/reconnaissance phase uses the system’s resources. The reconnaissance run also increases the transaction’s latency. And finally, the reconnaissance is not perfect, and by the time of the “real” run, the read and write sets may have changed due to other transactions impacting the state of the system.
So, the above description is somewhat generic behavior for many systems out there. And this is where Prognosticator, a system discussed in the paper, comes in. Prognosticator uses Symbolic Execution (SE) to profile transactions and help predict each transaction’s read-and-write set. The system does not need experts to annotate transactions read-and-write sets, but it can still avoid the reconnaissance runs in many situations. Sometimes, however, the reconnaissance must still happen, but Prognosticator uses a few tricks to reduce the possibility of the reconnaissance becoming stale.
Let’s look at the issues with figuring out the read-write set of a transaction. Many transactions are not primitive read and write commands, and involve quite a bit of logic with loops and conditional statements. This means that a state of a client/application may impact both the values written and the keys accessed. For example, consider a transaction that takes some input i:
input i; if i > 10 then write x:=i; else write y:=i;
The read-and-write set of above example depends on the input value already known to the client. The paper calls this transaction an Independent Transaction (IT), as it does not have an internal dependence on the read values.
Some transactions can be a bit more complicated and have the read-write set depending on the value read by the transaction:
read a; if a > 10 then write x:=a; else write y:=a;
Here the transaction does not know its write set (i.e. writing x or y) until it acquires the value of a. Prognosticator paper refers to these transactions as Dependent Transactions (DT), as the write set has an internal dependence on the read values.
Obviously, for both types of transactions, we can do the reconnaissance phase to figure out all the logic and branching to learn all the required keys. But we do not really need full reconnaissance for the ITs, as their read-and-write sets only depend on some client input and not the transaction itself. In fact, we can just play out the transaction’s code to figure out the read-write set without actually retrieving any data from the store (i.e. using some dummy values). However, we still somehow need to know whether a transaction is IT, as using dummy values in DT will clearly not work. Moreover, such a “dry run” with dummy values for every IT we encounter is still wasteful, as we do it every time.

This is where Prognosticator’s Symbolic Execution (SE) approach shines. With SE, Prognosticator “unwraps” each transaction for all the possible execution branches, leading to a symbolic transaction solution for all possible code paths. If all code paths access the same keys then we have a static read-and-write set. If certain execution branches access different keys, but branching conditions involve only transaction input, then we are dealing with an Independent Transaction (IT). We can easily compute IT’s read-and-write set from the symbolic solution once the input is known. Finally, if SE yields some branches with different access keys, and these branches are conditioned on a transaction’s reads, then we have a Dependent Transaction (DT) and will require a reconnaissance read.
The Prognosticator “unwraps” each new transaction type only once at the client-side to create such a symbolic execution profile with all possible code branches. There are quite a few optimizations mentioned in the paper. The important gist of these optimizations is the fact that we do not care so much about the actual symbolic solutions, and care only about what keys show up in the read set and write sets. So if two execution branches produce different symbolic solutions, but access the same keys, these branches can be “merged” for the purposes of predicting the read-and-write set.
The rest of the Prognosticator’s magic depends on a batching technique that allows for a careful deterministic reordering of transactions. With the help of SE, the system identifies all read-only transactions (ROTs) and executes them concurrently at the beginning of the batch. This leaves us with a batch containing only ITs and DTs. The system then reorders DTs to the beginning of the batch. This allows it to run reconnaissance reads on all DTs while also working on ROTs. Since all DTs are now at the beginning of the batch, the reconnaissance reads cannot become stale due to any IT. Reconnaissance may still become stale due to the dependencies between DTs, and in this case, a DT is aborted during the execution phase and is placed in the abort batch to run after the main batch completes and before the next batch.
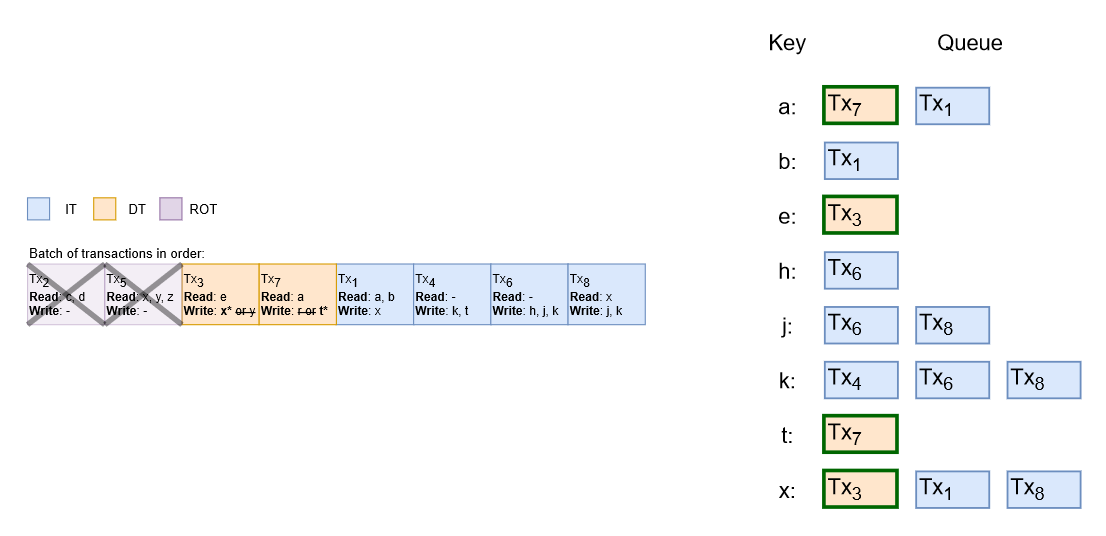
To execute the ITs and DTs in parallel, Prognosticator uses a lock table. The lock table is a collection of per-key queues, such that for every key in the batch there is an entry in the table with a queue of transactions. A transaction can be executed when it is at the head of the queues for all its keys. Obviously, executing a transaction removes it from all these queues.
The whole transaction execution process runs independently on each node. It is safe because we actually do not need to stick to the leader-prescribed ordered in the batch, as long as we keep the correct order of batches, and deterministically reorder the transactions in the same way on all replica nodes. With the batch execution, we have all the clients waiting for their transactions to finish, and this deterministic reordering does not cause any problems as all waiting transactions are concurrent. This is a common trick used in many systems.
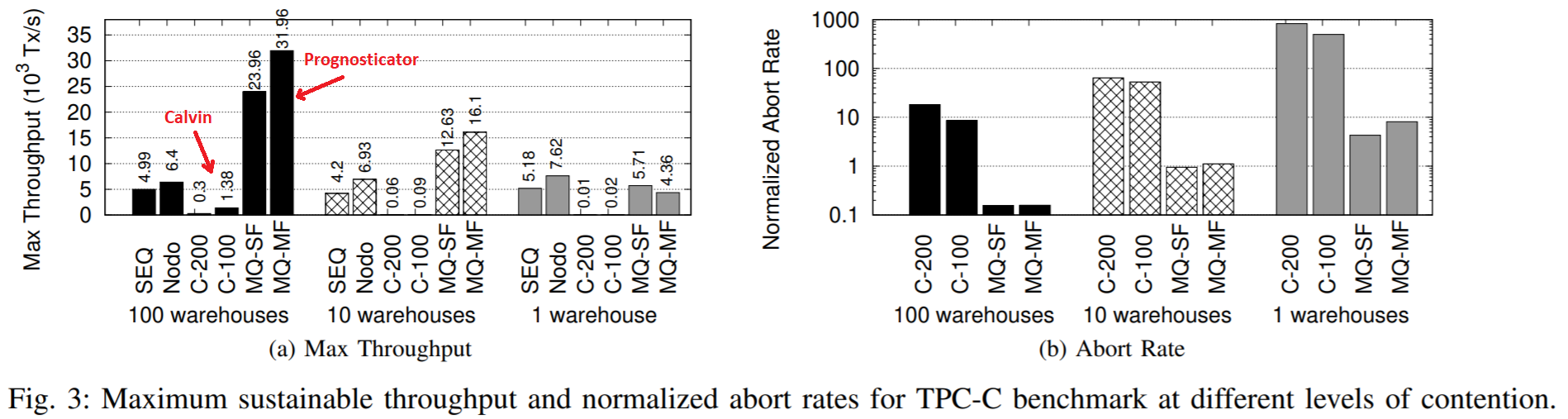
The whole package with SE and batching provides a significant boost to the throughput compared to Calvin. It is not entirely clear though how much of the boost was enabled by the SE, but I will come back to this point in the discussion summary.
The paper goes into more detail on many aspects of the paper, including symbolic execution, more efficient implementation of the lock table, resource usage, etc. It was definitely a good read for me. As always, we had a presentation in our reading group, and I had to cover for a missing presenter:
Discussion
1) Performance gains due to SE vs Batching. The paper claims a great speedup compared to Calvin, however, one question we had is just how much improvement is due to symbolic execution and how much of it is because of clever batching techniques. Let me elaborate. Some benefit comes from the careful reordering of operations. Running ROTs first helps a lot. Running reconnaissance reads at the node (compared to running a reconnaissance transaction at the client) is a lot faster too, and it reduces the possibility of reconnaissance becoming stale. Some of these techniques may be applicable in simpler systems without SE. For example, if we have transactions with annotated read-write sets, these reorderings within the batch become possible. Of course, SE definitely helps find ROTs and separate ITs from DTs to improve/enable the reordering within the batch without the need for annotated transactions.
2) Slow ROTs. Deterministic transactions are susceptible to clogged pipelines when some big long-running transaction gets in the way and delays consecutive transactions. Parallel/concurrent execution helps here by essentially having multiple processing pipelines. However, Prognosticator has one issue with the read-only transactions (ROTs), making them more susceptible to the clogging problem. The paper mentions that ROTs get executed at the beginning of the batch from a stable snapshot. All workers must complete their ROTs before the system moves to DTs and ITs to make sure that no DT or IT changes that stable snapshot while ROTs are still running. This means that there is a barrier at the end of the ROT phase, allowing a single long-running ROT to screw up the performance by delaying all DTs and ITs in the batch. However, this may be just an artifact of an academic prototype — taking a separate snapshot and running all ROTs from that snapshots should allow ROTS to execute concurrently with writes.
3) Cost of SE. The paper mentions the cost of doing symbolic execution. There are a few problems here. The first is processing time – more complicated transactions need a lot of time to pretty much exhaustively explore all branching. This also requires putting a limit on the number of allowed loop iterations. The limit can create a situation where a transaction is not fully profiled if it actually goes above the limit, requiring a reconnaissance. The limit, being a configurable parameter, may also require some expert knowledge of the workload to properly configure, and this is something the paper strives to avoid. Another big cost is the memory footprint of transaction profiles. The authors mention that the TPC-C benchmark required 960 MB for transaction profiles, which is not a small cost for a simple benchmark with relatively few transaction types. In the real world, the memory cost of having transaction profiles may be much higher.
4) Extension to sharded systems? Prognosticator works in the replicated system with all nodes storing identical data. It does not work in a sharded environment, yet most large-scale databases are sharded. It may be non-trivial to apply the same approach to sharded systems. After all, running a distributed transaction is harder, and may require some coordination between the shards. At the same time, it may still be possible to separate transactions according to their types and conflict domains with the help of SE to increase parallelism and make transaction execution more independent. Again, real systems based on Calvin’s ideas have cross-shard transactions. A big problem with sharded setup in Prognosticator involves DTs — the system expects to perform the reconnaissance read locally, which means that all data for the transaction must be available at each node. This is not possible in the sharded environment. And making reads non-local will make the system much closer to Calvin with a longer distributed reconnaissance phase and negative performance impact. So, the non-sharded nature of Prognosticator is a huge performance benefit when comparing with more general Calvin.