This Wednesday, we were talking about serializability checking of production databases. In particular, we looked at the recent OSDI’20 paper: “Cobra: Making Transactional Key-Value Stores Verifiably Serializable.” The paper explores the problem of verifying serializability in a black-box production system from a client point of view. This makes sense as serializability is an operational, client-observable property. The tool, called Cobra, collects the history via a middle layer sitting between a client and the database and then uses the history to construct a polygraph representing all possible execution orders. The problem then becomes finding whether a serial execution order exists in the polygraph. This means that we need to find some graph that has no dependency/ordering cycles. For instance, this would represent a cycle: A depends on B, B depends on C, and C depends on A. In fact, quite a few tools take a similar approach for checking sequential equivalence properties. What makes Cobra different is that they want to check serializability at scale, but the problem is NP-complete, so adding more events to the graphs makes checking exponentially slower. To mitigate the issue, Cobra uses a few tricks. It uses a few domain-specific heuristics to reduce the size of the polygraph. It also takes advantage of parallel hardware (GPUs) to speed up (by order of magnitude!) some highly-parallel polygraph-pruning tasks. And at last, Cobra uses an SMT solver to perform the final satisfiability search on the pruned polygraph. I will leave the details of all these methods to the paper.
Our video presentation by Akash Mishra is, as always, on YouTube:
Discussion
This is a very nice and interesting paper that sparked some lively discussion. here I list a few of the key discussion points.
1) Performance improvement. Cobra is significantly faster than the baselines in the paper. One concern during the discussion was about the optimizations of the baselines. For example, one baseline is Cobra’s approach minus all the optimizations. This is great in showing how much improvement the core contribution of the paper brings, but not so great at comparing against other state-of-the-art solutions. For the paper’s defense, they do provide other baselines as well, all of which perform worse than Cobra minus the optimizations one. So maybe there are no other domain-specific solutions like Cobra to compare just yet.
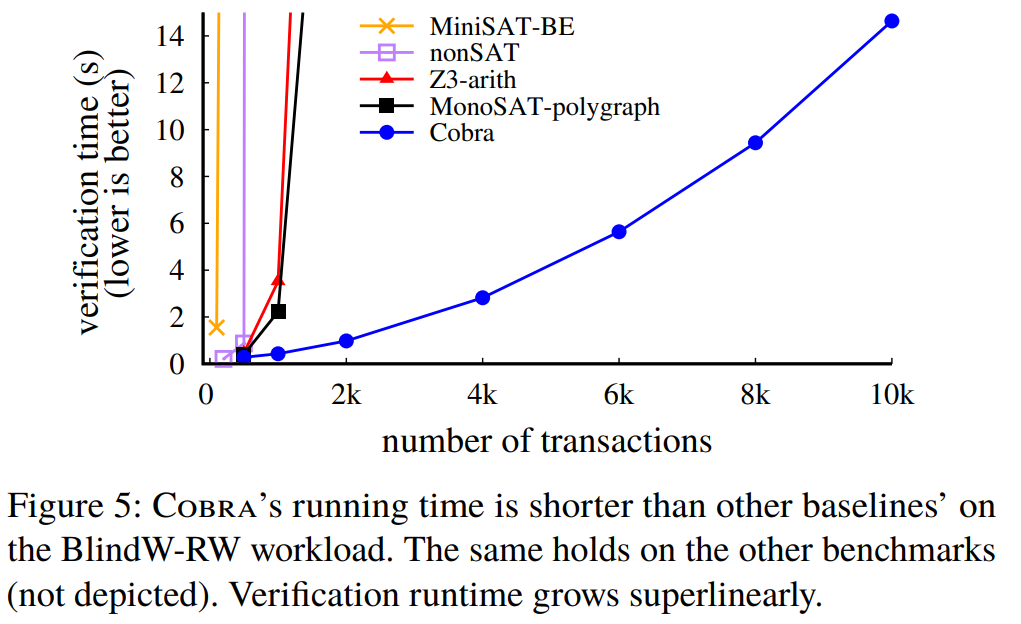
2) Performance improvement part 2. Another performance discussion was around the use of GPU. While the authors mention a magnitude improvement when using GPU for graph pruning, it is not often clear how much of the overall improvement is due to the GPUs. Interestingly enough, the overall gains compared to the baseline are ten-fold. For this one, the paper provides a figure that breaks down the time spent in each phase/optimization of Cobra. In read-heavy workloads, polygraph pruning, which is GPU-optimized, dominates the entire computation, suggesting that a lot of the gains may come from the use of specialized hardware.
3) Better parallel hardware? Are GPUs the best hardware to accelerate pruning? Maybe some better alternative exists? FPGAs?
4) Is it fast enough? While Cobra is significantly faster than other approaches, it may still be not fast enough for use in some production workloads. While it can handle 10k transactions in ~15 seconds, real production workloads can produce more transactions in under one second. The paper claims that Cobra can sustain an average load of 2k requests per second, which is enough for many large services. 2k transactions per second is the scale of systems about 35 years ago.
5) Do we need this in production? We spent quite a bit of time discussing this. Aside from concerns in point (3) above, there may be less utility from checking a production system. Achieving serializability in happy-case is not as difficult. There are plenty of databases out there that do just that. Testing systems in production is like testing a happy-case execution most of the time, so there may be little incentive to do that, especially given the cost of Running Cobra.
Keeping the same guarantees under failures is more difficult, this is why tools like Jepsen stress test the system by introducing the faults. Our thinking was that Cobra when combining with the fault injection can be a powerful stress-test tool. And with the capacity to check larger histories, it may be useful for checking more involved scenarios and doing routine fuzz testing (maybe even check-in testing!) to try to prevent engineers from introducing bugs.
As far as continuous production use, we did not have many scenarios, aside from a service provider checking its own compliance with some consistency SLAs or a user trying to catch a service provider to get a discount (but at what cost?)
6) Limitations. Cobra works only on key-value stores and only with a subset of common operations. For instance, it does not support range operations. Checking the serializability of range commands requires knowing not only what keys exist but also what keys do not exist in the system. This is hard in a black-box production system. However, our thought was, if this is not a production system, and you start with a blank-state for testing purposes, the knowledge of what keys do not exist is there — initially, none of the keys exist. Maybe in such a scenario, Cobra can add support for ranged operations. Especially since we think it will be more useful as a very powerful testing tool (point 5 above) rather than a production monitoring tool. There may be other reasons for the lack of range operation support that we do not know or understand.