“Achieving High Throughput and Elasticity in a Larger-than-Memory Store” paper by Chinmay Kulkarni, Badrish Chandramouli, and Ryan Stutsman discusses elastic, scalable distributed storage. The paper proposes Shadowfax, an extension to the FASTER single-node KV-store. The particular use case targeted by Shadowfax is the ingestion of large volumes of (streaming) data. The system does not appear to have replication and cannot handle server failures without data loss. However, the authors focus on reconfiguration performance and its impact on the rest of the system. So, in case of failures, replacement servers can be added with a minimal performance penalty. Under failure-free conditions, nodes can be added or removed without data loss. Finally, Shadowfax stores data in three different “places” based on how hot the keys are. Recently updated keys reside in RAM, colder data gets pushed to the SSD, and finally, the data from SSD is asynchronously copied to the shared cloud storage.
The main problem Shadowfax solves is ingesting lots of data from networked clients. A single server can only do so much, so we really need a system that can partition the keyspace across the servers. Shadowfax builds on top of FASTER, single-node storage that leverages a lock-free hash table to support key indexing/look-up. Shadowfax adds hash-based key partitioning to ensure each server is responsible for a subset of all keys. This partitioning is stored in ZooKeeper for fault tolerance of the sharding configuration.
A lot of the Shadowfax design stems from two ideas: (1) avoiding coordination and context switching and (2) avoiding unnecessarily costly operations.
For the first point, Shadowfax servers pin processing threads to cores, allowing each thread to pick up some requests and dispatch them to the underlying FASTER store shared among all processing threads. As such, the processing threads never coordinate with each other by any other means except the FASTER store. The shared FASTER store uses lock-free hashing to minimize the impacts of concurrency. Whenever some coordination is needed, FASTER avoids explicit cross-thread coordination with the help of asynchronous cuts. As different threads may access the same shared data, it is often essential to know when all threads have passed or seen some particular version of the data. For instance, when some record moves from RAM to SSD, all threads must have completed their access to that record in RAM (or agreed not to access it) before the memory can be cleaned up. FASTER achieves this lazily via view or epoch changes. When a thread sees a new epoch and transition to it, it agrees to have finished accessing any data in the old epoch. When all threads have moved (at their own pace) to a new epoch, the system can reclaim the memory supporting the older epoch’s data.
On the client-side, threads pin to a core as well. Clients maintain sessions with the servers. Each client thread opens a session with each server, allowing independent client threads to talk to the same server without any internal coordination. When accessing the key, a client thread uses its session for the partition/server hosting the key and batches the request before sending it over to the server with other requests from the same session.
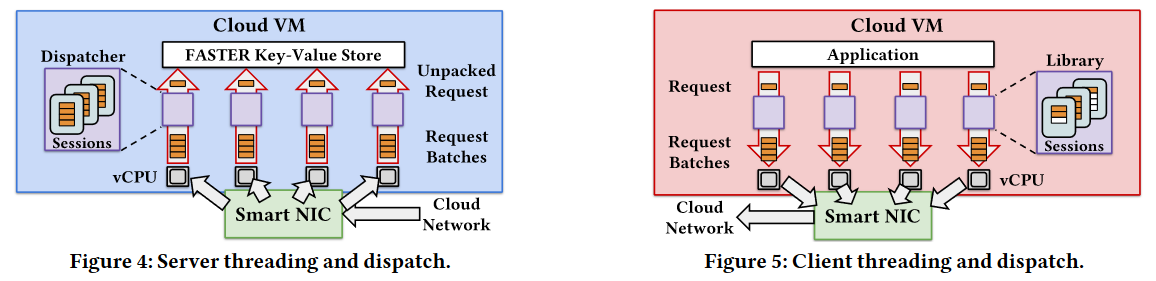
The scheme with sticky sessions works well when the partitions are static. However, in a dynamic situation, it may be possible that a client sends a request to a server that no longer serves a key. This is where the second aspect of the design comes in. The naive solution would be for a server to check ownership for each request, but this would also be a waste of CPU cycles for the vast majority of requests. Instead, Shadowfax checks request ownership at a batch level using view numbers and drops outdated batches. Each server has a view number representing its configuration version. Whenever there is a partitioning change impacting a server, its view increases. The client attaches the view obtained (and cached) from ZooKeeper to a batch, so if the client’s information is stale, its batches will not succeed. Naturally, when this happens, the client refreshes the keyspace mapping and server views from ZooKeeper.
The migration tries to avoid as much coordination as possible. It leverages the idea of the asynchronous cut to transition between phases of the migration process — once all threads finish a migration phase, they can transition to the next phase. I will skip the detailed explanation of data migration, however, I will mention that it requires a few state transitions on both the source and target nodes, and during the process, some requests may get delayed, as the target machine may not have yet received the data for remapped/repartitioned keys. In short, the source must find the keys to send, tell the target to expect the data migration, and move the keys, while the target needs to accept the keys and eventually start serving them.
Another extension of Shadowfax over the FASTER store is the ability to move data from SSD to shared cloud storage. The main benefit of using cloud storage is the speed of reconfiguration and migration. Shadowfax eventually writes all records from SSD to shared cloud storage. This cloud copy allows the migration procedure to avoid copying the records from SSD and instead migrate the index with pointers to the records in the shared cloud storage.
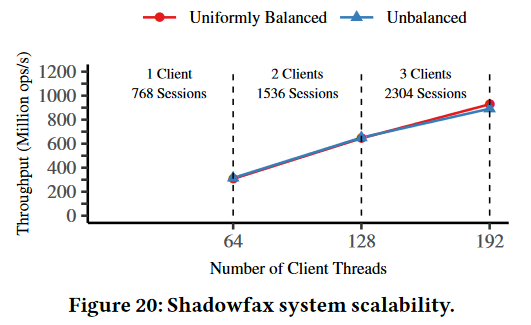
Regarding performance, Shadowfax seems to provide around 130 million ops/sec on one 64-core server. On 12 servers (and 3 clients) as shown in the figure here, the throughput can go as high as 930M ops/sec. Scale-up procedures also seem to be quick with little impact on performance. We can see a dip in source throughput, but it is relatively short and lasts way under a minute in all tested scenarios.
Discussion
1) Fault tolerance? While it is impressive to get up to 130M ops/sec of throughput over TCP (albeit with FPGA network acceleration), I cannot stop wondering what kind of applications need such per-node throughput and do not need data redundancy? If we operate at such speeds, a server reboot can mean millions of lost operations that existed only in RAM.
2) Client Scalability. Shadowfax clients communicate with servers over TCP, but the system assumes a small number of clients/sessions. In fact, the authors perform most evaluations with just one massive client. What happens is that a client needs a session to each server from each of its threads. So a 64-core client will have 64 sessions per server. I am not entirely sure if having this many sessions will impact the performance. The paper achieves 930M ops/sec in 12 server clusters with 3 clients, but each client is massive, and all three clients combined have 192 sessions on each server. The authors claim this result as proof that the servers can handle many client sessions.
One question I have is whether having more smaller clients will impact the performance even if it is the same number of sessions? Referring to the theme of the first discussion point, what kind of application will have a single client producing 310 (930/3) million events/records/updates each second? Of course, an argument can be made that these clients are “proxies” for many real clients, like sensors, IoT devices, etc., but that will also mean that these proxy clients will not be able to provide 310M ops/sec, as they need to manage a lot of connections from actual data producers. So this, in turn, will require more proxy clients, hence more sessions.
3) Benefits of cloud storage? Shadowfax uses shared cloud storage to copy data from SSD. However, this cloud storage does not seem to bring many benefits to the system, except for the data migration and recovery use case. Cloud storage also provides some limited protection from data loss when a server crashes and never reboots. But this protection only covers some data since “hot” keys in RAM are not written to SSD and consequently not copied to the cloud, leading to the cloud alone having incomplete or stale data.