We kicked off the winter term set of papers in the reading group with the “Towards Modern Development of Cloud Applications” HotOS’23 paper. The paper proposes a different approach to designing distributed applications by replacing the microservice architecture style with something more fluid.
The paper argues that splitting applications into microservices from the get-go can introduce performance, correctness, and manageability problems. Instead, the authors propose writing and designing applications as a logical monolith—breaking applications into logically separate modules, like microservices, but keeping applications monolithic with a single executable. This single executable does not mean that the application runs entirely in one place. The app remains distributed, as multiple processes of this executable can run in different locations (i.e., different VMs or containers). Furthermore, not all instances of the app’s process run every logical component or service. As a result, the application can still run like a microservice app, as processes running different subsets of components deploy in different places and interact with each other over the network. However, that decision over where and how to deploy the components lies with the “magical” runtime systems. For instance, the runtime may collate some components in the same process because they are chatty, avoiding the network and serialization costs associated with communication over the network.
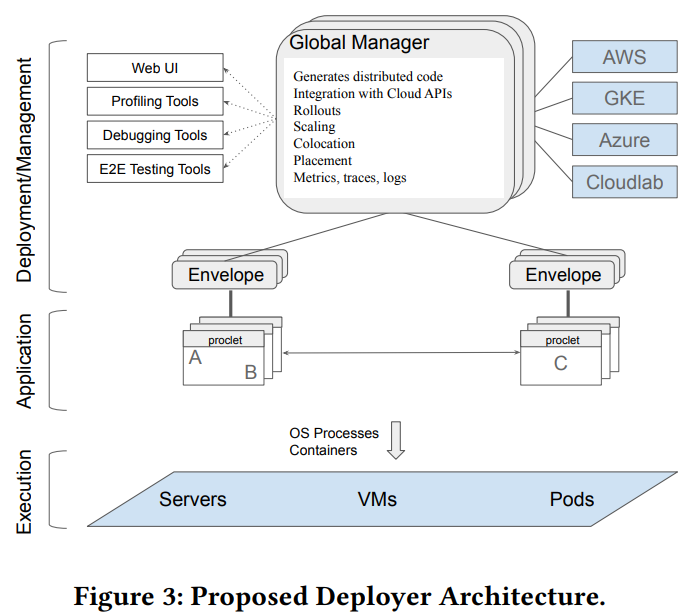
All-in-all, the proposed architecture somewhat reminds me of Borg. The runtime has a global manager that controls placement, scaling, collocation, etc. Each application process has a “proclet,” a daemon within every process to control starting/stopping of the process’s various components/services.
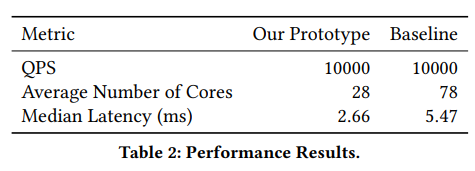
The paper claims that this logical monolith with the runtime scheduler/optimizer is faster than traditional microservices and uses fewer resources. They tested the performance on a small microservice-style application, so add a sizeable pinch of salt to these results when extrapolating to larger applications.
Aside from the performance issues, the authors claim their solution addresses some correctness problems and various manageability issues. The key idea for all of these presented in the paper is “Atomic Rollouts” via the blue/green deployments. With atomic rollouts, the service avoids running in the mixed-version configuration — if a request starts in the same version of the app’s process, it will continue in that same version and will not use any other versions. Avoiding mixed-version operations solves some correctness problems due to version mismatches. It also allows easier rollouts of newer APIs between components/services and quicker sunsetting of the older APIs.
Discussion
Our discussion was way longer than these three topics, but these seemed the most important for the group.
1) The Use-case & Eval App is too Small. One of the biggest concerns noted in the group was the scale/size of the eval app. It is too small to show whether the suggested approach works “for real.” The testing app consists of 11 microservices and was doing only 10k QPS, making it neither large in terms of code-base nor running at really high throughput. A common question was on the merits of even bothering with a microservice-style application of this size, as a monolithic app could have been sufficient for the scale and performance requirements presented in the paper.
2) Runtime. Arguably, the runtime is the most interesting part of the paper, as it needs to make the decisions for the app’s scalability and deployment. However, the description lacks sufficient details on the scheduling/scaling aspects of the system.
3) Atomic Rollouts. This topic also resulted in a heated discussion. Most problems (aside from perf, which is solved by the collocation of components/services whenever possible), are solved by the atomic deployment. However, this is somewhat of an orthogonal problem to the monolithic design proposed by the authors. Microservice apps can potentially use atomic deployment (at least for the major version changes). That being said, the atomic rollouts may also be difficult and/or costly to achieve in practice. For example, while the paper suggests a single request remains in the components/services of the same version through its entire lifespan, there is no guarantee that the side effects of this request do not cross the version boundary. Consider an application where requests modify some state in the cache or storage system. Such a modified state can then be used by a different request running on another