For the 149th paper in the reading group, we read “On-demand Container Loading in AWS Lambda” by Marc Brooker, Mike Danilov, Chris Greenwood, and Phil Piwonka. This paper describes the process of managing the deployment of containers in AWS Lambda.
See, when AWS Lambda first came out, its runtime was somewhat limited — users could upload a zip with their function code, and the system then would run this function in some standard runtime. Having standard runtime is nice, as all worker nodes may have a copy of that runtime image available locally, making a startup relatively simple and quick. All that needs to happen is grabbing a zip with the function and running in an instance of that standard runtime. This approach, however, precludes more complicated functions and applications from using a serverless computing platform. In particular, large functions with many dependencies cannot really be zipped into one (small) file. Instead, these functions can be packed as container images, requiring the serverless platform to be able to deploy these images. Unlike small (up to 250 Mb) zips with code, container images (the paper talks about 10 GiB images) are much costlier, performance- and monetary-wise, to copy from storage to workers whenever a new instance of a function runtime starts. As such, there are a few broad angles to the problem of containerizing serverless functions: deploy or cold-start latency, network bandwidth, and storage costs.
Okay, so we have users who create these large images for their serverless functions, and we need the serverless platform to handle these images and somehow solve the problems above. To start, AWS lambda cheats — while users submit their functions/runtimes as container images, AWS does not deploy these runtimes as containers. Instead, Lambda relies on Firecracker VMs; so, the container image, upon uploading, is flattened to an ext4 filesystem mounted by the VM. This filesystem, and not the container image itself, then must be copied to the worker node for the Firecracker VM to work.
Replacing a container image with a mountable filesystem does not solve the problem of moving/deploying all that data. However, Lambda still has a few tricks up its sleeve. Unsurprisingly, many container images may have a lot in common — rely on the same language runtimes, libraries, and dependencies. Once represented in the filesystem, such “sameness” results in many different functions having identical “stuff” in their file systems. The flattening process divides the filesystem into chunks or blocks of some relatively small size such that identical files are guaranteed to produce identical chunks. Naturally, identical data does not need to be stored (too) many times over by Lambda. However, the system needs to identify these duplicate blocks to optimize the storage. To do so, Lambda ensures that the name/id of each chunk depends on its content, making identical blocks have the same names for easy deduplication.
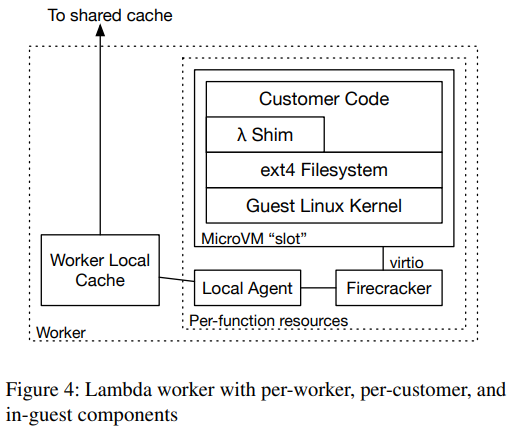
The “sameness” of many images also lends nicely to the idea of caching — if many images have the same blocks, these blocks are more likely to be needed by many functions, so it makes sense to cache them closer to the worker nodes. AWS Lambda goes a step further and introduces a two-layer caching hierarchy sitting on top of the authoritative storage (S3). The first level cache is local to the worker nodes, so some very popular blocks reside straight on the machines that see containers deployed. The second level cache is a remote cache for reasonably warm blocks. In addition, each level has two sublevels — in-memory and SSD caches.
To get the benefit of caching for latency of container deployment, AWS Lambda does not actually fetch the entire file systems image to the VM upon the startup. Instead, the hypervisor “fakes” the filesystem to the guest and fetches blocks on demand — whenever a VM needs a block, the hypervisor fetches it by traversing the caching hierarchy. As a result, the most common and frequently used blocks are retrieved extremely fast from the local cache, allowing the VM to start up quickly and avoid most data transfer in the process. This on-demand fetching also works because most stuff in these large images is never used. All these optimizations allow a cache hit rate of 99.8\%, largely avoiding the need to go to the much slower S3 for data.
I would not be Metastable Aleksey, if I did not mention the possibility of Metastable failures for such a well-optimized caching system. The paper has a section on mitigating the potential risks. If some portion of the cache fails, more traffic will go to S3. This in itself is not a problem, as S3 is highly scalable and should handle the load. However, the lack of cache elongates the start-up time, increasing the number of outstanding function deployments and prompting even more function deployments that may need to go to new nodes without cache, thus creating a feedback loop. The paper mentions that they limit the number of concurrent container starts to tame the feedback mechanism. And, of course, they test the no-cache operation at target concurrency settings to guarantee the system can handle it.
My summary is already running long, so I will stop here, but the paper has plenty more content and details, such as encryption, garbage collection, using erasure coding in caches to reduce storage/memory overheads, and some implementation tidbits.