Last week, we read “Databases in the Era of Memory-Centric Computing” CIDR’25 paper in our reading group. This paper argues that the rising cost of main memory and lagging improvement in memory bandwidth do not bode well for traditional computing architectures centered around computing devices (i.e., CPUs). As CPUs get more cores, the memory bandwidth available to each core remains flat or even decreases, as shown in the figure below. Similarly, the cost of memory does not decrease as fast as that of computing or storage.
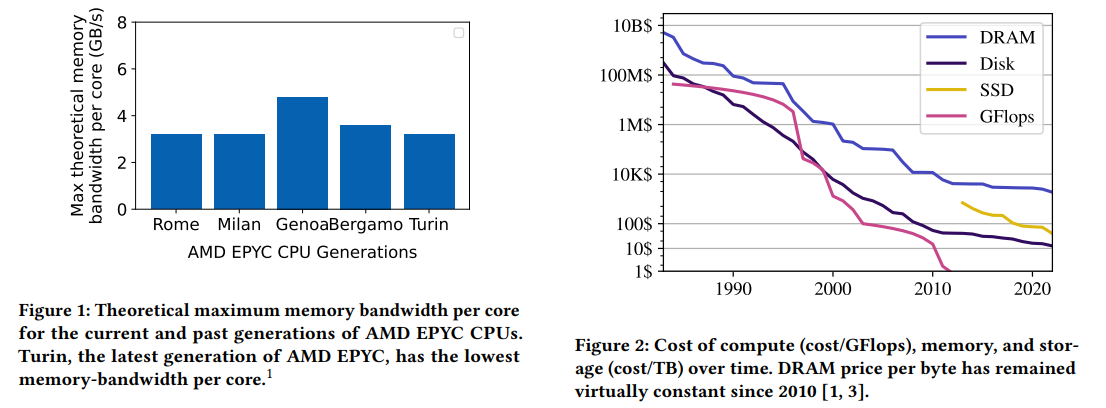
The authors argue that restricted bandwidth leads to CPU underutilization for memory-intensive jobs and applications. As for the price aspect, more expensive memory makes it a more valuable resource to waste.
As such, the paper suggests that we stop building systems around the compute and instead should focus on more constrained resources — memory: “Memory-centric computing aims to reduce the cost of memory in cloud systems by enabling efficient memory sharing. A memory-centric system treats memory itself as the dominant cost and compute power as commodity.“
While “memory-centric architecture” sounds interesting and exotic, memory disaggregation is the actual tool to implement it. Such disaggregation of CPU and memory is a logical solution to prevent both underutilization of memory for compute-bound jobs and underutilization of CPU for memory-bound ones. Naturally, this also plays well with the cost of memory in datacenter/cloud, as less memory gets wasted or goes unused.
The paper illustrates the “napkin math” tradeoffs of disaggregation on one database-oriented example—a distributed join of two large disk-resident tables done by 10 computing servers. I am going to skip the numbers and assumptions (please refer to the paper for this), but I will mention that the math shows that the memory-centric approach with CXL disaggregation is roughly 25% slower than that of a traditional CPU-centric architecture without memory disaggregation. One advantage of memory disaggregation is the ability to share memory between servers/workers, and this advantage allows for overall lower memory usage (and remember, memory is expensive!) in this task.
My thoughts
My take on this paper is a bit twofold. Memory disaggregation is nothing new now, and the benefits are decently well-known. From this perspective, the paper is easy to agree with. There are obvious advantages from the cost-saving and resource-management standpoint of pooling and sharing memory.
The paper argues that bandwidth-intensive systems adopt the memory-centric (e.g., disaggregated) approach; this is where I am not entirely sure. See, from the authors’ perspective, and they are database people, databases are memory-intensive applications. However, they are also storage-bound applications with limitations of storage bandwidth, often higher than that of memory. Paying the price of memory disaggregation may be worth it when you have another, even bigger bottleneck in your system.

The bandwidth is an interesting argument. On one side, if we have CXL for disaggregation, we can have 100+ GB/s of bandwidth from a full x16 link (and maybe multiple such links). But this bandwidth will be shared between the users of the memory devices plugged into that link. A modern server with 12-channel memory can get 300+ GB/s of bandwidth (again, shared between tenants/VMs on that server). If we use “far” memory over RDMA, then a 200 gbit/s InfiniBand interface gives you roughly 25 GB/s — less than the bandwidth of a single DDR5 channel. This comparison does not look good for truly bandwidth-sensitive applications/systems. Finally, there is High Bandwidth Memory (HBM). The paper dismisses this technology as just too expensive to be practical. HBM is indeed more expensive, but it is available, and solutions using it have truly astonishing bandwidth compared to traditional DRAM. Azure offers HBv5 high-performance VM with up to 6900 GB/s of bandwidth! If we translate this into the per-core metric from the figure above, we get around 20 GB/s per core. Imagine what kind of in-memory DBMS we can design for this hardware!
I also want to point out the level of scalability a shared-nothing system can achieve (look at Google Spanner, for example). This scalability is partly due to avoiding unnecessary sharing and interdependencies and taking control of the hardware. Now, of course, hardware may be virtual and imaginary and shared in the cloud (as well as other cloud resources). However, traditional architectures still create a possibility for more self-contained systems that can scale horizontally. This self-containment is imperfect and breaks with common dependencies (networks, configuration services) and the need to sync between the groups/partitions (e.g., add 2PC to a distributed partitioned DB for cross-partition transactions). Disaggregated memory is, by default, a shared resource and a shared dependency. It is by definition not self-contained. While it may allow us to sync between workers or compute nodes cheaper, it also can introduce problems, like noisy neighbor issues and a larger blast radius for failures. The latter point is of special interest to me, as shared/disaggregated memory and storage can act as a gateway to propagate the failure between partitions of a system or even different systems.
Anyway, I am all for memory disaggregation. We will learn how to constrain the blast radius for failure containment. We will learn how to share the resources better and provide tenant/application performance isolation and better performance predictability. However, I also think memory disaggregation will occupy a niche of memory-not-intensive applications. And storage-bound databases may be included in this niche set of systems. But there is another class of systems/applications in that niche that may benefit more—serverless computing. Many serverless functions have a decent amount of IO to do over the network to retrieve the data before doing any kind of processing and finish by doing more network IO to output the data somewhere else in the cloud. These applications already come with this IO bottleneck “built-in.” Furthermore, many serverless functions, even compute-heavy, tend to be smaller (e.g., not occupying the entire large machine), so their memory bandwidth is already limited to some fraction of what a machine could theoretically do. As such, these applications may favor cost, programmability, and other cloud perks over raw memory performance. From the cloud-vendor perspective, serverless platforms are also hard to run efficiently, as scheduling and resource management are hard at such a scale. Memory disaggregation, with potential cost savings due to pooling memory, can be a big hit in this space.
Reading Group
Distributed Systems reading groups meets on Thursdays at 1 pm over Zoom. Please join our Discord server for more info.