Last week we read “OLTP Through the Looking Glass 16 Years Later: Communication is the New Bottleneck” CIDR’25 paper by Xinjing Zhou, Viktor Leis, Xiangyao Yu, Michael Stonebraker. This paper revisits the original “OLTP Through the Looking Glass, and What We Found There” paper and examines the bottlenecks in modern OLTP databases.
The new paper looks mainly at VoltDB, an in-memory OLTP database that primarily relies on stored procedures for transactional workloads. As such, a typical interaction with the database will involve a client invoking pre-compiled stored Java procedures.
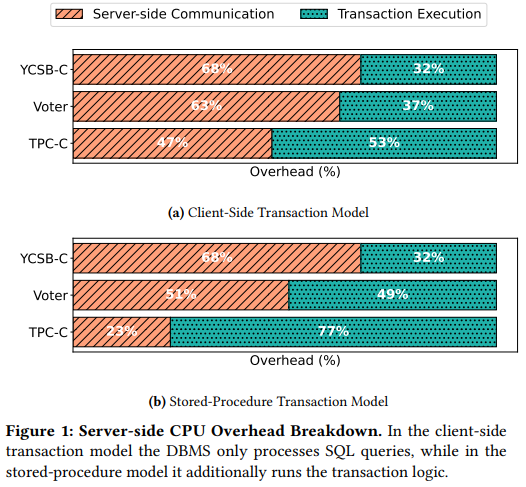
The paper jumps straight to the problem—Rign on the first page, wedged in the middle of 3rd paragraph, we see a lovely figure that tells us the horror story about how expensive networking is for modern OLTP systems (VoltDB). For simple workloads like YCSB, communication eats up ~70% of the CPU cycles. More intricate transactional workloads (TPC-C) spend more time doing, well, transactions (which, in the case of VoltDB, actually involves running a more complicated stored procedure inside the DB!). At this point, six paragraphs into the paper, we can stop.
The rest of the paper expands on this key finding and also shows the overheads of stored procedure isolation. When stored procedures execute in a more isolated environment, like a VM or a container, and use networking (e.g., TCP) to communicate with the main DB system, the overheads get too high, circling back to the original point of expensive communication. The paper has a very nice breakdown of these isolation overheads and explains why we should care about stored procedures for high-performance OLTP.
Finally, the paper includes a few research directions based on the findings: (1) explore distributed DBMSes with replication and distributed transactions, as they may have even higher networking overheads; (2) better kernel bypass ans specialized networking stack for database systems, (3) better isolation, and (4) better transaction models.
As a side note, my student Owen (who also presented this paper in our reading group) had a related presentation at the DPDK Summit this past Fall, talking about DPDK, the potential improvement we can gain with it, and, most importantly, difficulties in adoption due to a lack of good, easy-to-use abstractions..