One of the questions engineers of large distributed system must answer is “where to compute”. This is a big and important question, as we do not want to send a request originating in the US to some server in Australia. It simply makes no sense to incur the communication overhead if there are resources available closer. But physical affinity is not the only requirement to answer the question. Just as we would not make an Olympic swimming competition in a desert simply because a desert is close, we would not send a Russian language speech recognition request to the servers with English language model. In other words, when deciding on the placement of a computation, we need to find the closest place with enough resources of the right type.
Slicer is a Google’s answer to this “where” problem. It continuously tries to find the best possible place to perform the computations in the presence of dynamically changing workload. Many applications within Google, such as speech recognition, various caches and DNS service use Slicer to partition and balance their workload among a set of tasks, or application servers (containers). Computation placement is not on the application critical path, and it is somewhat static: once it has been made, we can use it for some time until the conditions change. Think of finding a swimming pool for our Olympics competition ahead of the actual races and sticking with the same pool until the games are over.
Slicer sticks with the same pool of resources as well, as it directs similar requests to the same set of tasks. Each application using Slicer needs to produce a key associated with the request and Slicer hashes it into a 63-bit internal key, which is then used to decide on the placement of the computation. This makes it possible for requests with the same key to be processed by the same set of tasks, catering to locality of reference.
Clerk library provides a client interface to pull and learn which keys are assigned to which tasks. With Clerk, clients can learn the assignment and communicate directly with tasks. Google’s RPC service Stuby is also integrated with Slicer and can provide Clerk’s functionality, so many applications do not even need to use Clerk. Application servers use a similar library, called Slicelet, to learn which keys that particular task is expected to process, allowing tasks to adapt for the change in the requests they serve.
Slicer service is divided in two major parts: Assigners and Distributors. Assigners map keys to tasks, while Distributors retrieve these maps from Assigners and deliver them to the Clerks and Slicelets upon request. More than one Assigner exists globally, and any assigner can generate the key assignment for any application, however, in most cases only one assigner is considered to be preferred. Sometimes more than one Assigner can act as preferred for short duration, but Assigners eventually converge to the same assignment through the optimistically-consistent storage. Slicer also has a mode with strongly consistent assignment, however it has not been tested on production at the time of paper publication. Slicer also packs a variety of backup mechanisms to make sure clients can still make the requests despite Assigner or Distributor failures. In case of miss-assignment (~0.02% of requests), for example due to failed tasks, client will need to try the request again with the new assignment obtained from Slicer.
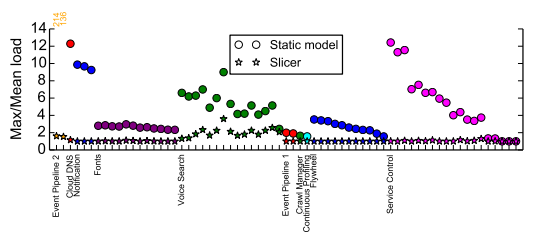
Assigners perform load balancing for the requests by changing how many tasks are assigned to each key. Balancing is done taking into account a usage rate of different keys. As the load changes, Slicer updates it’s mapping by taking some servers off the lesser used keys and putting them for the use by “heavy” keys. Load balancing results in lesser load on the “hottest” tasks of an application (median job’s hottest task is 63% less loaded), compared to static request distribution. At the same time, Slicer reacts to shifting workload patterns in the matter of minutes.
Slicer seems to be playing a big role in deciding where to process requests at Google, at least for certain applications. It provides load balancing and ensures the requests get to servers or tasks that are both prepared to accept them and have capacity to do so.