Many distributed computation platforms and programming frameworks exist today, and new ones constantly popping out from the industry and academia. Some platforms are domain specific, such as TensorFlow for machine learning. Others, like Hadoop and Naiad are more general, and this generality allows for sophisticated and specialized programming abstractions to be built on top.
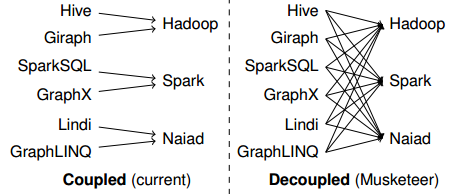 So we naturally ask a question, which distributed computation platform is faster and more scalable? And what programming model or framework is better? Authors of the Musketeer tried to find the answer and concluded that there is no such thing as the perfect computation platform or perfect programming front-end, as they all perform better under different circumstances and workloads. This discovery led to the Musketeer prototype, which decouples the programming front-ends from their target platforms and connects all the front-ends to all the computation back-ends.
So we naturally ask a question, which distributed computation platform is faster and more scalable? And what programming model or framework is better? Authors of the Musketeer tried to find the answer and concluded that there is no such thing as the perfect computation platform or perfect programming front-end, as they all perform better under different circumstances and workloads. This discovery led to the Musketeer prototype, which decouples the programming front-ends from their target platforms and connects all the front-ends to all the computation back-ends.
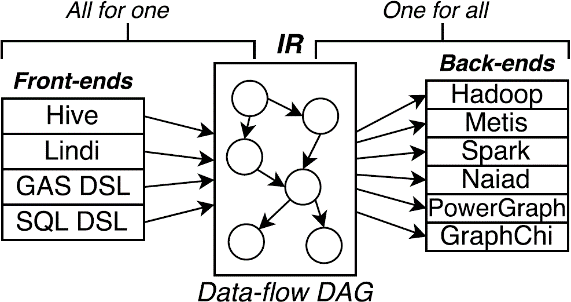 Musketeer accomplish this task through translating the code created in every supported programming front-end to an intermediate representation (IR). This intermediate representation can later be translated into the commands of the computation platforms. Think of Java or Scala code translated to Java bytecode before being JIT compiled to native code as the program runs. Each IR is a data-flow DAG representing the progression of operations in the computation.
Musketeer accomplish this task through translating the code created in every supported programming front-end to an intermediate representation (IR). This intermediate representation can later be translated into the commands of the computation platforms. Think of Java or Scala code translated to Java bytecode before being JIT compiled to native code as the program runs. Each IR is a data-flow DAG representing the progression of operations in the computation.
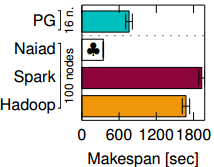
Musketeer runs the IR on the platform it chooses the most suitable for the job (Figure on the right). For example, some platforms may be better for some operations and not every platform supports all types of computations. Musketeer detects the patterns of operations in the IR through idiom recognition and will not allow IR containing certain patterns to run on the platform that does not support these patterns or performs badly.
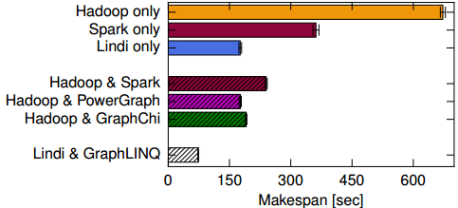 Musketeer can also split the entire computation into smaller jobs, each running on different platform. The partitioning is done by picking a lower cost back-end to run the partition. Of course finding the partitions in the DAG is a complicated problem (NP-hard).Musketeer uses exhaustive search to find best partitions for smaller IRs, and heuristic based dynamic programming approach for larger DAGs when the cost of brute-force approach becomes prohibitive. Heuristic approach does not examine all possible partitions. Such partitioning allows achieving better performance than a homogeneous platform.
Musketeer can also split the entire computation into smaller jobs, each running on different platform. The partitioning is done by picking a lower cost back-end to run the partition. Of course finding the partitions in the DAG is a complicated problem (NP-hard).Musketeer uses exhaustive search to find best partitions for smaller IRs, and heuristic based dynamic programming approach for larger DAGs when the cost of brute-force approach becomes prohibitive. Heuristic approach does not examine all possible partitions. Such partitioning allows achieving better performance than a homogeneous platform.
The IR is not optimized when it is generated at first, however Musketeer performs the optimizations before starting the computation. In particular, certain operators in the IR DAG will be merged together to reduce the number of jobs executed. The merging affects the platform choice, as some platforms support more complex jobs, while others need more steps to achieve the same result. Musketeer also optimizes for the IO by trying eliminate the duplicate scanning of a dataset. All the optimizations allow the code generated from the IR to have similar performance as the manually optimized code.