The “Barbarians at the Gate: How AI is Upending Systems Research” paper by Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Bowen Wang, Alexander Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Yang, Jeff Chen, Lakshya Agrawal, Aditya Desai, Jiarong Xing, Koushik Sen, Matei Zaharia, Ion Stoica from Berkeley has recently made a splash in systems research social media and several blogs. Murat and I read the paper live a few days ago:
The core premise of the paper is that AI, and LLMs in particular, can change how the system’s community does research. The idea the paper is pushing for (which, by the way, is not the idea of the authors, and they use existing frameworks to perform case studies and shape the narrative of the paper) is what they call AI-Driven Research for Systems (ADRS). An ADRS approach involves placing LLM agent(s) in the exploration loop, where LLMs refine a “starter” solution to a problem, evaluate these refinements using a provided evaluator, and then repeat the refinement and evaluation process.
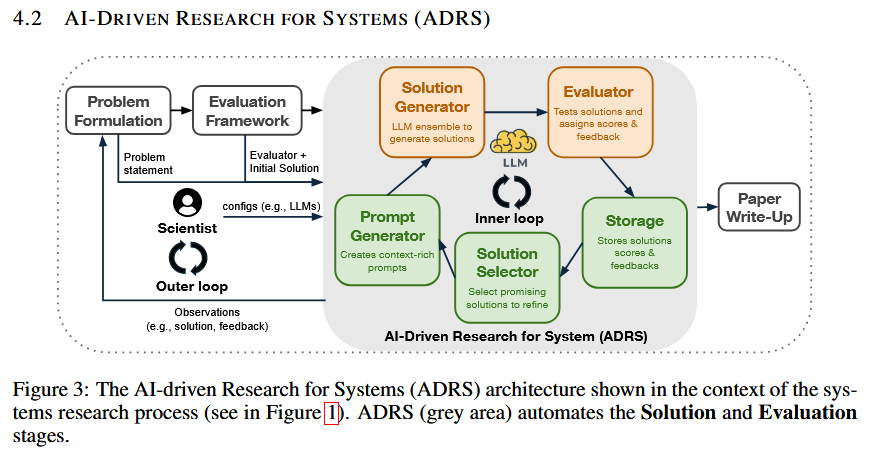
In a sense, the evaluator provides the “reward” function for the LLM. Improved evaluation results make LLM pick and refine that solution in the next loop. Of course, ADRS needs to cast a wider net and engage in exploration rather than strict exploitation by trying at least several directions from the “starter” and intermediate solutions to avoid being stuck in local maxima. The paper also briefly discusses the role of a human in guiding LLM refinements as it iterates.
The authors test this approach on 11 case studies (they report only 4 in detail). Notably, however, the paper focuses on improving performance as the research goal, primarily because it is easier to quantify success/improvement in an algorithm.
I think the authors do an excellent job showing how LLMs and tools to facilitate the ADRS vision can speed up the development. However, I also believe that all the actual research was completed before ADRS could even begin working and developing faster algorithms. This is where I get into my concerns with the approach, and the paper did not address them, although the authors mentioned them in the text.
Problem formulation, the first step in the research sequence outlined in the paper, is a complex problem. Nearly all of the case-studies presented actually skipped that step, as problems were pre-formulated in already published research.
The second “manual” (and the last step before the automated part of ADRS) is the evaluation framework, which includes the “evaluator” component that ADRS must use to check the quality of LLM’s work. The evaluator serves as a reward, but it also must check all the constraints and invariants imposed on a correct solution. This is an elephant in the room and probably the most important component of the whole ADRS approach. If we step back and consider what ADRS is trying to do, we will see that we are moving towards a declarative approach to creating new systems. ADRS is building SQL, where S stands for Systems (e.g., Systems Query Language). The researchers describe the expected outcome via a prompt, evaluator, and a “starter” code, and then let LLM agents loose to create code that satisfies that outcome. The evaluator is the enforcer of the outcome and essentially directs LLM agents to improve X while satisfying conditions a, b, and c.
My concern is that imperfect evaluators may prompt LLMs to exploit the “holes” in the declaration. For example, if an evaluator is not checking some aspect of safety, a solution may converge to exploiting that and produce unsafe, but fast solutions. In many larger systems and algorithms, the list of restrictions and constraints is often extensive, and I’d argue that we may now even know all the restrictions and properties we want out of a system. So, this is a problem: less-than-perfect evaluators are likely to result in brittle systems — extremely good at the aspects LLMs were rewarded for at the expense of restrictions that designers forgot about. However, creating perfect evaluators is an unachievable feat, as it requires knowing all the properties, constraints, and expectations for a system in advance.
I also want to mention that brittleness may not come from forgetting about big things. It is the smaller constraints that may make the ADRS-developed system brittle. Consider my favorite problem of performance failures with a system that has two execution paths — fast and slow. The fast path takes most of the time, so there is a much bigger reward to optimize it. However, as the fast path becomes quicker, the danger of getting stuck in the slow execution paths increases. Lacking a constraint that the slow path must be optimized to the same extent as the fast path will create a more brittle system when the slow path is eventually engaged.
Now, to be fair, the same problems apply to people writing code. However, with people involved more directly, they may (even if it is unlikely) discover some of these hidden properties and constraints while optimizing code or designing new algorithms. And this is an essential part of research training, getting one’s hands dirty, diving deep, asking questions, and discovering new things while practicing the craft.
Anyway, I think ADRS vision is a great productivity tool for already skilled researchers. It may also necessitate a more formal approach to system design, requiring better specifications and models to serve as evaluators, which is also great. But this brings me back to the research question. I do not think ADRS makes it easier to do research. It may make it easier to implement prototypes. It may reduce the time required for implementation. But it does not change how good research is done. Good research does not happen in incremental progress to refine implementations; it comes from asking questions, stating problems, figuring out right and useful abstractions, designing good experiments…
And speaking of bad research, it seems like LLMs will make it incredibly easy to do now. Take a paper, feed their code and a benchmark into LLM, get new code, publish. I hope ADRS will not result in a bunch of slop research, or we will need to organize a monthly SlopSys, a slop conference for AI slop papers.