I will be presenting our new paper, “HoliPaxos: Towards More Predictable Performance in State Machine Replication,” at the VLDB’25. Feel free to ping me if you are there and want to chat!
This paper explores several orthogonal optimizations to the classical MultiPaxos state machine replication protocol to improve its performance stability in the presence of slow nodes, network partitions, and log management activities.
I’ve been working (and trying to escape from) state machine replication for quite some time now. Metastable failures research was supposed to be my escape route, yet here I am — blogging about another Paxos state machine paper. This is a weird paper as it changes nothing about how MultiPaxos works, preserving the Paxos and Viewstmp Replication state-of-the-art from 1989. The industry relies on these classical SMRs (MultiPaxos, VR, and Raft) and sticks to the “if it ain’t broke, don’t fix it” mantra, and so we are doing the same with HoliPaxos. In fact, after working on Metastable failures, I cannot stop seeing how virtually every state machine replication work that comes out, reinvents the algorithms and in the process breaks something hugely essential by introducing new performance corner cases. Instead of reinventing consensus, we add some “sprinkles on top” of MultiPaxos to soften the impact of MultiPaxos’ performance corner cases and make it work just a tiny bit better than before. Importantly, making the protocols less prone to performance variations when conditions are not 100% ideal makes these protocols more tolerant to performance failures such as Metastable failures.
Anyway, there are other solutions that try to fix the same issues with SMR as HoliPaxos. The problem is that I do not think they do it well, and introduce too much new complexity into algorithms and protocols, hence breaking what was not broken before. Let’s look at these issues: node slowdown (solved by Copilots Paxos), network partition handling (solved by Omni-Paxos), and log management (solved in an ad-hoc way by everyone).
HoliPaxos is MultiPaxos in the common case operation, so it retains its performance, unlike more complicated solutions (looking at you, Copilots Paxos and Omni-Paxos). Yet, the changes incorporated into the SMR mitigate the problems mentioned above.
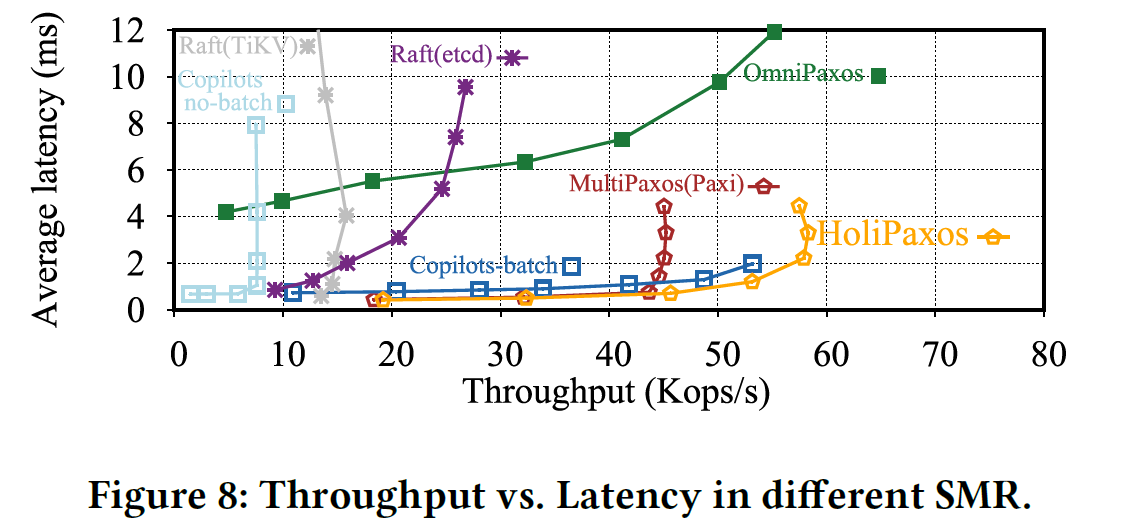
Node Slowdown
This problem looks at a type of a gray failure when a node become slow instead of failing outright with a bang. A slowdown-tolerance, like failure tolerance, allows a protocol to mask or reconfigure a system to handle some slow machines.
Copilots Paxos from OSDI’20 addresses this one by trying to “mask” slow nodes. It is insanely complicated, as Copilots rely on two co-leaders who receive the client operations, order and replicate them, and then reconcile their orders with an EPaxos-style protocol. In our evaluation, we also observed that Copilots Paxos does not work well at all without batching and also demands a lot of processing capacity from clients (who need to talk to two co-leaders). In case of actual slowdowns, the co-leaders rely on “good ol” timeouts to detect each other as lagging and reconfigure to take over the slow counterpart.
HoliPaxos does not attempt to mask the leader’s slowdown. Arguably, Copilots Paxos fails to mask slow leaders either, despite its attempt to shadow leadership with two nodes, as it still relies on a (short) timeout to detect a slow co-leader and reconfigure. Instead of masking, we go for a detection and reconfiguration approach, but just like Copilots Paxos, we aim for 1-slowdown tolerance (i.e., handling just one slow node in the cluster). This is a reasonable assumption, since a quorum masks slow followers, and we really only need to worry about a slow leader. Our solution relies on a self-monitoring approach — the leader monitors itself and detects if it is in distress. To that order, it looks at how many requests it currently has in progress (i.e., received a request from the client, but has not replied back to the client yet). With the help of some change point detection magic, we look for changes in that in-progress queue that are not correlated to changes in goodput. If the queue is trending up without an upward shift in goodput, then we conclude the leader is overloaded. A leader can become overloaded if the workload is too high or the leader is slow. In the former case, there is not much we can do except wait for the workload to subside, but in the latter, a leadership change should fix the problem. As such, upon a sign of an overload, we simply initiate a graceful leader handoff. If the problem was indeed a slow leader, it will be rectified after the leader change. In case of a more general overload, HoliPaxos will avoid repeated leader changes until the overload due to high workload goes away.
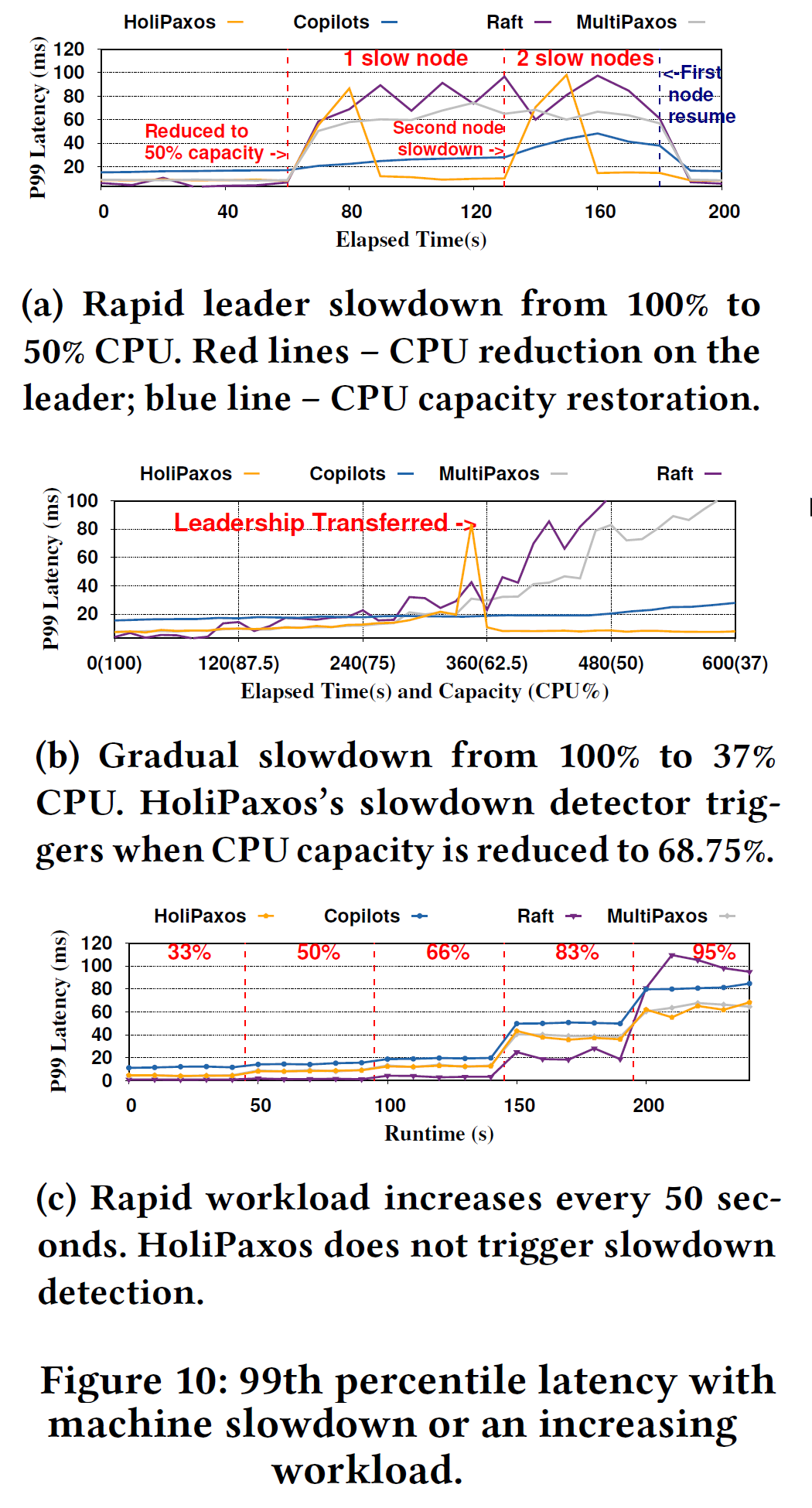
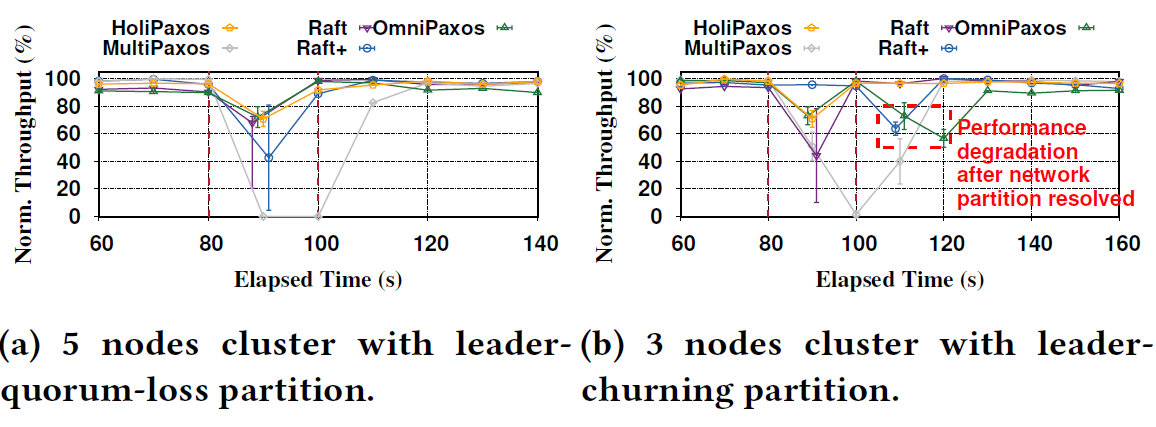
Network Partition Handling
This problem looks at the protocol’s ability to recover from non-standard network partitions, such as partial network partitions where nodes lose the ability to talk to some, but not all, peers in the cluster. The famous Cloudflare Raft incident highlighted the importance of this problem. Omni-Paxos largely solved this problem by constantly tracking node connectivity and using some quorum-connected node with the most connected peers as the next leader whenever a leader change is needed due to partitioning. In the figure below, I show one (of many) possible partitions that can cause problems with traditional SMRs (MultiPaxos and Raft). The leader-churn situation arises when one of the links between 3 nodes fails (in that case, a link between nodes A and C). In this example, all 3 nodes can actually make a quorum, but if nodes A and C start to churn, node B can never interject, as from B’s perspective, there is always a leader (either A or C). This churn reduces the performance of the cluster.
HoliPaxos avoids doing any real-time and continuous connectivity tracking, and instead adopts a Raft-style failure detector capable of carrying a ballot number in heartbeat messages and can demote stuck leaders. Raft failure-detector, however, does not solve the partitioning problem, so we also added a set of three rules that activate on the failure-detection side when the failures are sensed. This in-failure detection network partition handling avoids paying any performance cost during the normal execution. In this post, I will introduce just the first rule that we use. This rule alone is sufficient to solve the problem illustrated above, and pretty much the only rule needed for 3-node clusters (a larger cluster will fail to elect a stable leader without the other two rules).
“Rule 1: Pause leader elections for churning nodes. This first rule penalizes churning nodes by prolonging their heartbeat intervals upon detecting churn.” The consequence of large heartbeat intervals is such that the non-churning node (which is not aware that the leader heartbeats are longer now) will see the churning nodes as failed and will be able to slot in with its own leader election quickly.
Rules 2 and 3 essentially fix the things that Rule 1 breaks for clusters larger than 3 nodes, and you can read about them in the paper.
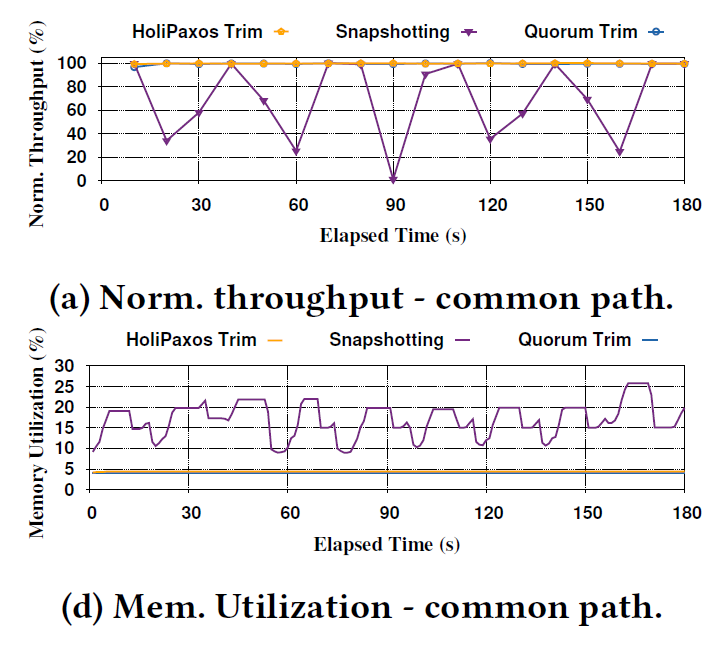
Log Management
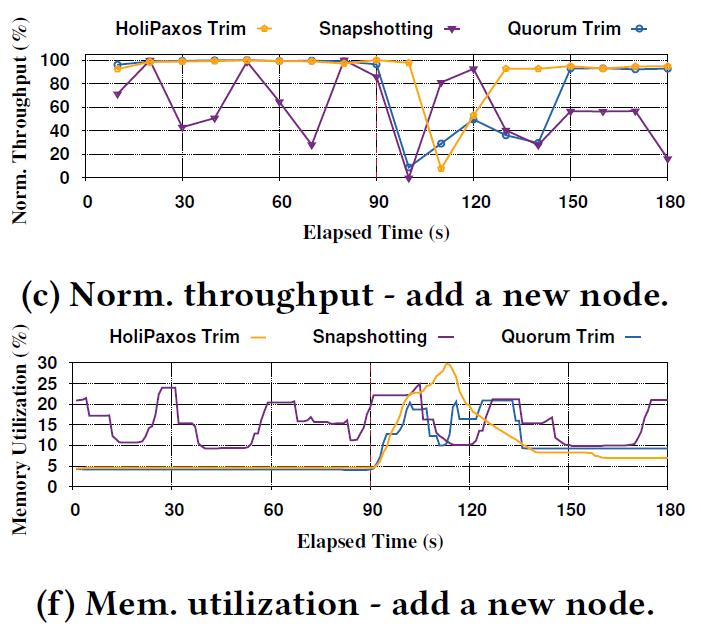
This problem deals with the need to clean up replication logs. I will largely defer to the paper for the explanation. However, we argue that traditional periodic snapshotting and compaction approach introduces too much performance variability in the common case execution. Furthermore, snapshotting is not vert resource efficient and most of the work gets thrown away eventually, since snapshots are rarely used except in case of recovery. We argue that a more “on-demand” node recovery is better for common-case performance and avoids unnecessary resource wastage while not substantially reducing the recovery potential or performance of the system.
The paper is available on VLDB website. Unfortunately, we did not get the “reproduced tags”, since the artifact evaluation people seemed to have had problems running/deploying things in the cloud and haven’t reached out to us for help beyond the initial complaint about the cloud stuff.