In this post I am trying to understand the Google’s Dataflow Model, a data management and manipulation framework used for dealing with unbounded and unordered datasets. A lot of the data is being constantly produced today and has no “maximum size”, in other words the amount of such data is constantly increasing, and therefore modern computing system must have a way of dealing with constant influx of information in an efficient way. In addition, many applications may misalign chronological data out of sequence due to the various reasons, leading to sequential data coming into the information processing system out of sequence. A data processing model, described in “The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive Scale, Unbounded, Out-of-Order Data Processing” paper, attempts to provide an efficient framework for handling such ever-growing and potentially permuted data.
As has been previously stated, the Dataflow model operates on unbounded data, in other words the dataset used in the system build with such framework is infinite and grows over time. The event occurrence and processing time becomes an important factor for system like that, since individual datapoints tend to have a chronological order to them. In addition, a lot of real life data can originate at a particular time, but be delayed for processing by some variable time, causing not just different event occurrence and processing time, but also the possibility of different chronology of events as they occur and being processed. Below I briefly describe the model and talk about its usage based on the examples in the paper.
The Model
The model operates on two basic primitive actions:
- ParDo is responsible for parallel processing of the events
- GroupByKey is doing grouping of the intermediate results of the ParDo function.
These actions are nothing new; they operate on the key-value pairs and allow for distributing the computation to multiple machines and grouping and aggregating the results after the computation is done.
Window based data processing deserves more attention as it allows to work with data in slices instead of bulk processing of everything at once. Once again, handling input data in blocks using windowing approach is very common. Because the Dataflow model assumes that the incoming data can be unordered, the window based approach needs to be able to update the computations performed while processing preceding data slices. Additionally, the model supports unaligned windows, or windows that may differ in terms of size and start or end time relative to other her windows. Such unaligned windows can be used to represent user sessions, or a cluster of user actions, in many of google applications.
The model operates on the data with two distinct timestamps, event time and processing time, and it is possible to partition the dataset into windows based on any of these time metrics. Unfortunately, when data is windowed, the system cannot ensure that it has collected and processed all events belonging to the window. Instead dataflow model provides a guarantee that eventually, if we process all data (which is impossible, since it is assumed the data is unbounded), the window will have all correct events associated with that window. A heuristic time watermark is used to estimate when the system expects to see events arriving to the system for processing depending on the event time. Once the watermark time is reached, window is processed. Obviously, such heuristic is not enough to guarantee the correctness of each window, so a trigger mechanism is utilized to issue an update to the window upon the arrival of new data after the window has already been computed. Essentially, a trigger retracts old window state, calculates a new state and signals that the updated window is now available. For example, event #9 in Figure 1 is arriving very late for processing, way past the watermark time (dark dashed line), so in many use configurations, event #9 will invoke a trigger and cause a corresponding window state to update.
The system also supports streaming data, which can be dynamically placed into the unaligned windows as more data comes in, with a window becoming available when a systems watermark suggests no more events for the window are expected to come in. The trigger mechanism is used to update the window state incase more data become available in each window.
Examples
Bellow, I will illustrate some of the examples provided in the paper. For all examples, the system computes the sum of the values of the events. Figure 1 shows the input events in relation to their event time and processing time.
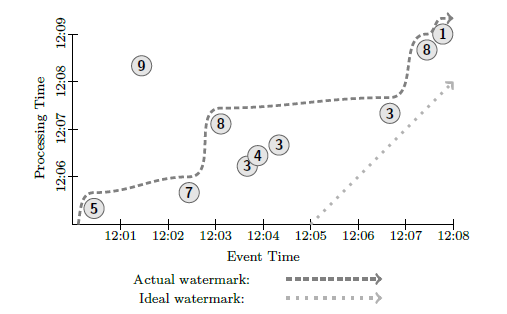
Figure 1. Sample events
The most basic example is batch processing the entire dataset. It is illustrated on the figure 2. As can be seen, the entire dataset is viewed as one window processed at once.
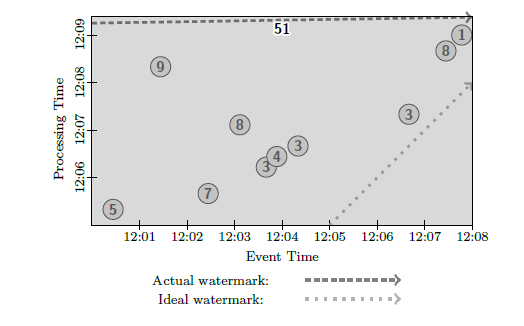
Figure 2. Bulk batch processing
It becomes more interesting when the data is partitioned into windows as it arrives to the system for processing. In the example on Figure 3, incoming data is broken into non-overlapping windows of 1 minutes, with value at each window accumulating from the previous one. Note that the watermarks are not used in this example, as the window is emitted for processing at fixed interval.
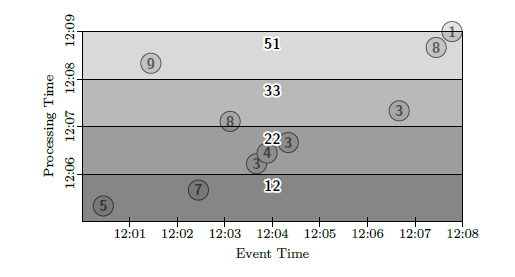
Figure 3. Processing in non-overlapping accumulating windows
Next example makes use of fixed windows with data partitioned by the event time. At first the system does not see the event #9, so the first window is bounded by the maximum watermark time estimated for the window (shown in darker shade of gray). As soon as the processing time reaches the watermark for the window, the data is processed and the windows state is computed. Later when the event #9 comes to the system, the trigger is invoked and a window state is recalculated, as seen in the light shade of gray for the 12:01 window.
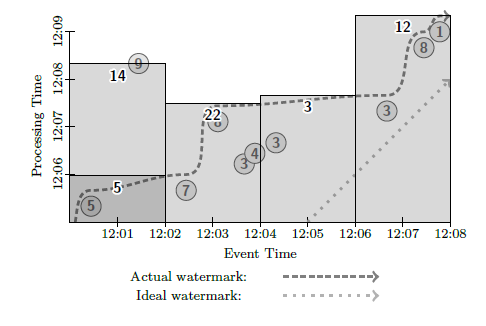
Figure 4. Fixed windows with streaming data
More sophisticated examples deal with unaligned windows to computed users sessions, but the basic principle stays the same with the exception of the fact that unaligned windows can change their size both in event time and processing time dimensions as more data becomes available.
Some Thoughts
According to the authors, the session use case is the main driving force behind developing the dataflow model. All other examples discussed in the paper are byproducts of the system developed to satisfy the session computation by google, which may not be a very good sign. Clearly, authors thought about other potential uses, but it is not clear how well their system performs under other usage scenarios compared to the existing alternatives.
Triggers provide a mechanism to keep the system in the most up-to-date state as new out of order events arrive for processing. Unfortunately, triggers seem like a fairly expensive operation, especially in some usage scenarios where previous window values must be retracted, new data added and window recomputed for every late event incoming to the system. Authors do not provide a performance measure for the system as a whole and triggers in particular, but invoking a trigger for every late event may be a potential speed issue for highly out-of-sequence data.
Authors also claim that the model is a highly customizable solution in terms of performance, because of the ability to batch process or stream process incoming data. No real performance measure is provided in the paper, so the reader is left to guess about the degree of such flexibility.