In our 48th reading group meeting, we talked about time synchronization in distributed systems. More specifically, we discussed the poor state of time sync, the reasons for it, and most importantly, the solutions, as outline in the “Sundial: Fault-tolerant Clock Synchronization for Datacenters” OSDI’20 paper. We had a comprehensive presentation by Murat Demirbas. Murat’s talk was largely based on his extensive time synchronization experience in wireless sensor networks.
First, let’s talk about the need for time synchronization. Many problems of distributed computing could have been avoided if we had a perfect global clock available everywhere, as we often rely on the ordering of events for correctness. For instance, such a perfect clock would make causality/dependency tracking easy. And this alone would have simplified and improved many different systems and processes, ranging from efficient consistent snapshots, to more consistent storage systems, to the improved debuggability of all distributed applications. In the absence of a perfect global clock, we have been relying on other clever tricks and techniques, such as logical clocks, vector clocks, loosely synchronized causality-tracking hybrid logical clocks to name a few.
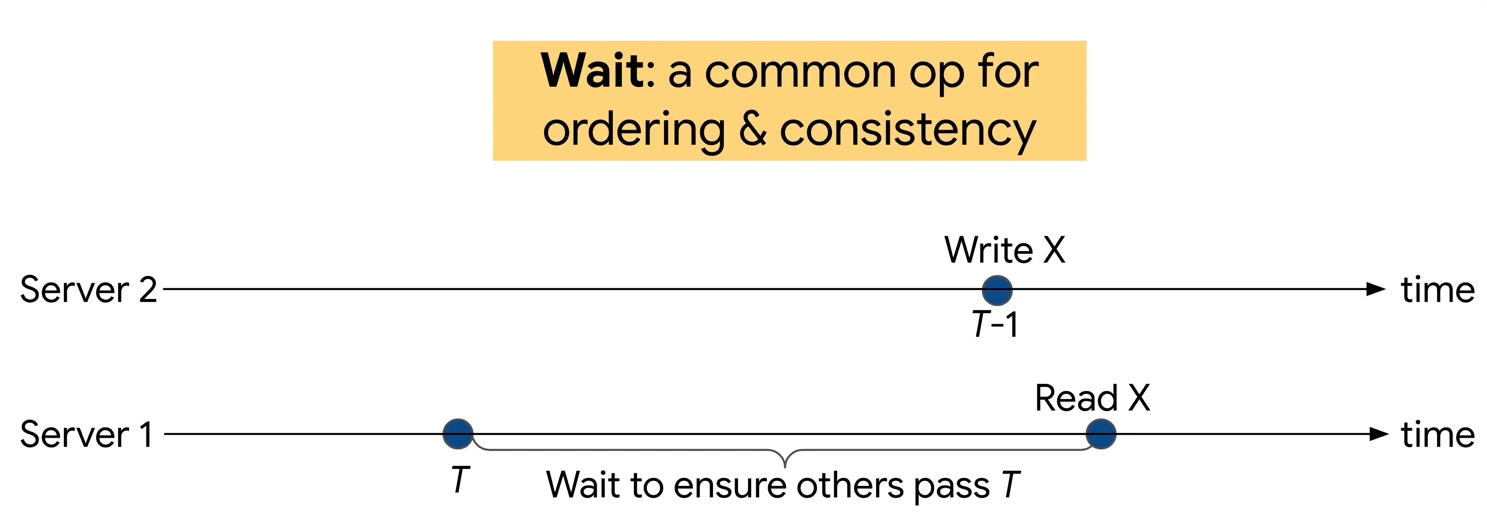
Fundamentally, if we have unsynchronized clocks on two servers, we cannot use these clocks to order the events. The paper provides the following example to the issue: a shared variable X is read on some server at time T, but this same variable is updated on a different server at time T-1, however, due to time asynchrony, the update actually happens after the read in the real-time. This essentially makes the clocks useless for ordering, unless we know how badly unsynchronized the clocks are. Knowing this time uncertainty ε allows us to delay the read at T until we know that all servers have moved on past T. Some systems may resort to rescheduling the operations/transactions that fall within the uncertainty instead of waiting, but this is a similar enough use case. Naturally, having smaller uncertainty is better for performance, since a system will incur shorter waits or fewer rescheduled operations.
So what prevents us from driving this uncertainty ε down to 0 for a perfect synchronization? This is not an easy answer, and there is a myriad of factors. The clocks themselves are a problem — servers tend to have cheap quartz oscillators that “tick” at different speeds depending on temperature and voltage variations. These variations make individual machines drift apart ever-so-slightly over time. Trying to synchronize these flimsy clocks is a problem as well — the servers communicate over the network for time sync. And the network is unpredictable, starting from how messages may be routed, to different queues and buffer delays at NICs and switches. All these add the variability to message propagation time and make the network non-symmetric, as message flow in one direction may be faster than in the opposite.
The paper proposes Sundial, a set of techniques to tame the network-induced uncertainties. Sundial focuses on reducing the message propagation variability in the network.
Firstly, Sundial avoids indirect communication and only exchanges messages between adjacent neighbor nodes in the network topology. This eliminates routing uncertainty between nodes, and also buffer/queue uncertainty at the intermediate switches.
Secondly, Sundial records the timestamps into messages at the lower level in the network stack. This ensures that the timestamp we are transmitting for synchronization has not been sitting in the local queue for too long, again reducing the variability.
Thirdly, Sundial ensures that a single node is used as a source of truth for the current time. Since the nodes in the system cannot talk directly to the “source of true time”, the system constructs a tree communication topology starting with the TrueTime root and covering all nodes in the system.
Fourthly, Sundial tames the unreliable clocks on the individual servers by doing very frequent synchronizations — once every 100 microseconds.
A big portion of the paper is devoted to handling failures since a link or node failure prevents the updated time to reach any node in the subtree below the fault, that subtree may start to deviate more the TrueTime at the root node. The gist of the solution is to allow all nodes in the impacted branch to detect the synchronization failure and switch to an alternate tree structure that was precomputed ahead of time. As all impacted nodes perform the switch to a new tree locally, the coordination is avoided, and the process is very quick. An important point in having such a back-up plan is to make sure it is smart enough to avoid correlated failures that can render both the main and back-up trees broken. The paper has a lot more details on the fault tolerance aspect, including handling the failures of root nodes.
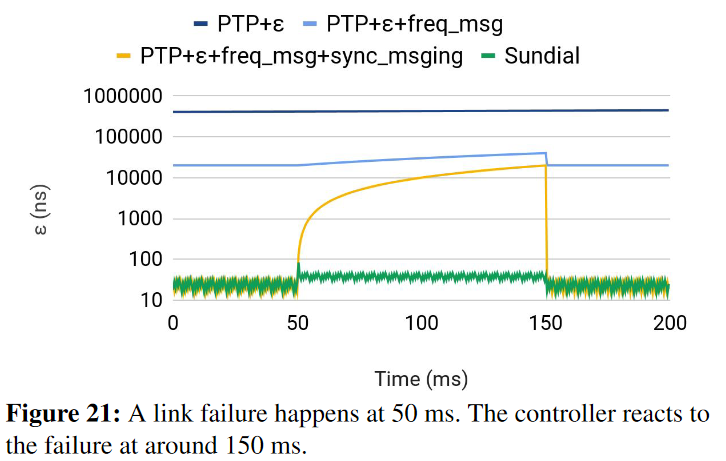
Combining all the Sundial’s techniques provides good time synchronization with fairly tight bounds. It achieves ~100 ns synchronization even under some failures, which is significantly better than PTP time synchronization (and even better than its precursor NTP?).
Discussion
We had a nice discussion and questions, below I summarize the most important points.
1) Set of techniques. As outlines, Sundial is a set of techniques to improve the time sync, and there are some important lessons there. For example, doing things in hardware (or as close to hardware) is good. We start seeing (network) hardware optimizations for distributed systems more and more often. Just a few weeks ago we talked about smart switches and using them to drive replication and routing for “hot keys” in a storage system. Obviously, time synchronization is a different problem, but it is also the one to benefit from hardware a lot. Another lesson is to have a single source of time, even though it makes the communication pattern more structured and prone to failures.
2) Better clocks/oscillators. Sundial synchronizes a lot – one message every ~100 microseconds. This is 10000 messages per second. We are not sure what impact this may have on the network (messages are small) and performance, but there is a practical reason for synchronizing this often. As Sundial aims to keep the uncertainty small (ε=~100ns), it cannot afford the cheap clocks to drift too much upon failures and needs to failover to a back-up tree quickly. This means that the system needs to have a super-tight timeout and very frequent message exchange. Better clocks/oscillators (or maybe using multiple clocks in a server?) can improve the situation here and either allow for even better synchronization or reduce the message frequency. Oven-controlled oscillators, for example, use a heated chamber to keep the crystal at the same temperature and reduce its drift due to the temperature variations.
3) Comparison with PTP. The paper extensively compares Sundial with PTP protocol. The authors mention how PTP does not report ε, and that they had to augment the designs to provide the uncertainty in these protocols. The paper puts PTP’s uncertainty at ε=800μs. This contrasts with other literature but, where PTP is often reported as having a sub-nanosecond accuracy (is accuracy the same as uncertainty? but regardless, to have an accurate time, we need to have low uncertainty, otherwise how do we know it is accurate?), or nanosecond level accuracy. It is worth noting that PTP in these papers either required a dedicated low-load network for time synchronization or hardware with support of some advanced features needed for PTP to work well or both.
4) Time sync in wireless sensor networks. Murat has spent quite some time describing how the same set of techniques was used 15-20 years ago to achieve microsecond level synchronization in the wireless sensor networks. The presentation has many fascinating details, but it appears that these techniques were known and used for some time, but not used in the data center setting. What was the blocker for doing this earlier?
5) New applications of synchronized time. Finally, we discussed a lot about the possible new applications of such precise time synchronization. The paper mentioned Spanner latency improvement as one benefit, but this is an “old stuff”. Actually, for many years we, the distributed community, were (self-)taught to not rely on time for anything critical. Sure, we use the time for things like leases and timeouts, but these are all “negative” communication that happens rarely, allowing us to be very conservative with the timeouts — there is a little harm if we add a few more seconds to a lease timeout that happens upon a leader failure and needed in rare reconfiguration cases. With super-tight synchronization bounds, we can try to use the time for positive communication and convey progress instead of the lack of one. This of course is challenging, since time is not the only uncertain variable in the system. All of our other “friends”, such as network uncertainty/variability, and crashes still exist, and we also need to tame them in some way to use the time for positive, active communication.
For example, one may use a “silent agreement” that requires no acks from the followers if everything is going well. But this quickly falls apart under faults. However, one may treat a synchronized clock as an agreement itself and use it to drive the ordering in a multi-leader system. This may also fall apart if the network is too-asynchronous, and a message from one server that already applied the operation may reach the other follower too late – after it has irreversibly applied some other higher-timestamped operation. Taming the network asynchrony may be the next big thing to allow new usages of time in distributed systems!
The network latency vs time uncertainty is very important for constructing consistent snapshots. If time uncertainty is guaranteed to be smaller than the network latency, we can use the time to construct the consistent snapshots, since we can be sure that no message that breaks the causality can reach the other side within the uncertainty period. This, for example, can be useful for debugging. In my Retroscope consistent monitoring system, I use HLC to preserve the causality when uncertainty is too large, but having software clocks like HLC unnecessarily complicate systems.