In the 92nd reading group meeting, we have covered “CompuCache: Remote Computable Caching using Spot VMs” CIDR’22 paper by Qizhen Zhang, Philip A. Bernstein, Daniel S. Berger, Badrish Chandramouli, Vincent Liu, and Boon Thau Loo.
Cloud efficiency seems to be a popular topic recently. A handful of solutions try to improve the efficiency of the cloud by ratcheting up the utilization of already provisioned hardware and infrastructure. These approaches tend to provide some service using otherwise wasted resources. For instance, we have covered a paper that suggests running serverless computing on harvested VMs that use resources normally wasted/idle in the data center. CompuCache provides a similar utility, but instead of running a pure serverless compute infrastructure, it suggests using Spot VMs to run a compute-oriented caching service. See, running a purely caching service is more memory intensive, leaving CPUs still relatively underutilized, defeating our goal of using otherwise wasted resources well. So CompuCache is a caching service that can execute stored procedures against the cached data. This is the “Compu” part, and I suppose it enables a better CPU utilization of the spot VMs the service is running.
So, now let’s talk about using spot VMs for storage systems. Spot instances have unpredictable lifespans controlled by the cloud vendor and not the users/engineers. When the resources used by a spot instance are needed to support other services, the cloud vendor evicts the VM with little notice. This fickle nature of spot VMs precludes them from reliably supporting a storage architecture. However, caching may be a somewhat viable option since the master copy of the data is stored on some durable service. Of course, we still want to avoid cache misses as much as possible for performance reasons, so CompuCache needs to have mechanisms to deal with spot VM evictions.

CompuCache architecture relies on the Cloud VM Allocator component to get the resources to run multiple caches for different applications. The allocator allows client applications to specify the size of cache they need and allocate the resources. The system assigns memory in fixed chunks (1 GB), and these chunks can go to different spot VMs that have the resources. Naturally, if no existing VMs have the resources, the allocator will try to get more VMs running. The clients “see” the allocated memory as an address space, and can write and/or read from memory knowing some address and length of data.
The sharded nature of the cache means that the clients somehow need to know where their data may be in the system. CompuCache uses a scheme that maps virtual global cache address space to the specific nodes and their local address spaces. The client application constructs and maintains this map based on the results of cache allocation through the Cloud VM Allocator. Moreover, the client application is responsible for distributing this map to the CompuCache instances. When the node composition of the cache changes due to VM evictions or new VM additions, so is the mapping of virtual memory space to instances. As the system evolves, each client application must migrate parts of its cache between VMs. The paper has more details on the procedures involved in data migration due to spot VM deallocation/destruction.
An interesting part of CompuCache is its compute-oriented API. The clients can read and write data directly from the cache, but they can also run stored procedures (sprocs). I suspect the stored procedures allow CompuCache to better utilize unused cores that go into the spot instances. I was under the impression that stored procedures are not a very popular tool, but I may be mistaken here. Anyway, of course, the authors provide another explanation for using stored procedures to interact with ComputCache — latency. See, if we need to read something and then update something else based on the retrieved value using just puts and gets, we will pay the price of 2 RTTs (not to mention screwed-up consistency). Using stored procedures, we can achieve this read-then-update pattern in just a single sproc call and 1 RTT between the client and cache. This is not a new idea, and some systems have been suggesting sprocs for atomic access to multiple keys and latency benefits. But here is a caveat, CompuCache is sharded and shards are relatively fine-grained, so the data you access in stored procedures may be on multiple VMs. This not only negates the latency benefit but also complicates CompuCache. To deal with data on multiple VMs, the system can either retrieve the data to a machine running the sproc or move the computation itself to the next VM.
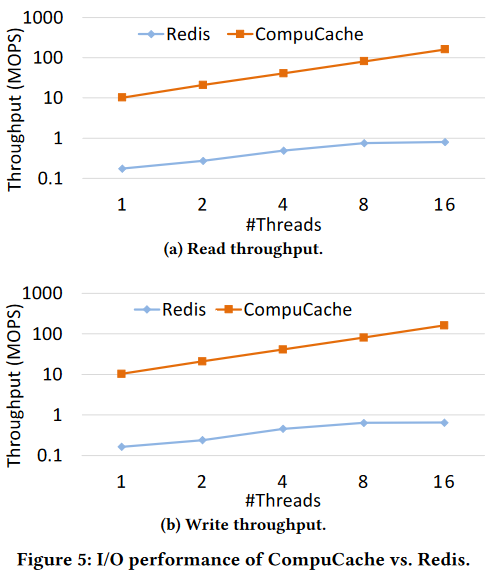
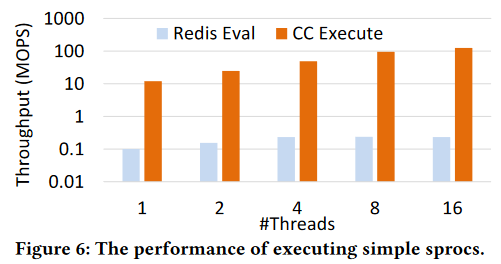
For the evaluation, the authors compared CompuCache with Redis, and it seems to outperform Redis by a large margin. This is interesting and unexpected, as there is nothing about using spot instances that should be beneficial for performance. Quite the opposite, the VM churn and reclamation should make CompuCache more likely to experience cache misses and spend more time migrating data and rebuilding caches. One explanation here is the poor performance of Redis sprocs implementation used in the evaluation, which seems to be at least two orders of magnitude slower than CompuCache. There is no word on what CompuCache uses for its sprocs to make it so much faster.
Discussion
1) Application-driven design. CompuCache places a lot of burden on the application that needs the cache. It seems like the “memory management” done by the application can be rather heavy. Any data migration requires remapping of the virtual address space to nodes. Consequently, clients then need to redistribute this map so that nodes themselves can find the data they may need to run sprocs. This can make the system brittle due to the application’s mismanagement of the cache.
2) API. An interesting thing to note is the API. ComputCache allocates memory to applications as some chunk of bytes. This chunk of bytes represents the virtual memory space that is mapped to multiple nodes/VMs. The API allows to read and write at some byte offset and length. So, there is no KV abstraction common in other caches, and in fact, the application needs to implement KV API if needed.
3) Sprocs vs. Serverless functions? One major point of discussion was comparison with prior work on serverless functions using harvested resources. The compute part of CompuCache looks a lot like a serverless function meant to operate on state directly from the cache. I’d suspect the sproc should also have the ability to find data in storage in case of a cache miss, but paper leaves any details on cache misses. Anyway, it seems that a sproc is a bit more restrictive than a general serverless function. So the question is whether you can run harvest VM serverless infrastructure capable of full-fledged function runtime and use it instead of CompuCache sprocs? Of course, you lose that nice benefit of collocating data and compute, but this benefit is elusive at best when a cache is sharded into many VMs anyway. The problem here is the map of virtual space to nodes — application knows it and maintains it, but a separate serverless compute does not know it, so it won’t have a clue what nodes to contact for data. So we are back to the point above — relying on the client application to manage cache can be brittle and restrictive.
4) Sproc performance. The performance evaluation is on the weaker side of the paper, mainly because it leaves many things underspecified. Why does Redis sproc is so much slower? How was the comparison done given the difference in cache APIs? What was the implementation of CompuCache?
5) Failures. Finally, it is hard to discuss any distributed systems without talking about failures. CompuCache leaves a lot of details on handling failures out of the paper. It is not clear what sprocs will do in case of a cache miss. In fact, it is even unclear what a cache miss is in CompuCache, as it does not store objects and provides some memory space for the application instead. It seems like this is all up to the application — if some memory is unreachable, the application should know how to find that data in a reliable store. This, of course, leaves sprocs vulnerable to failures. A big part of the paper’s fault tolerance discussion is data migration due to Spot VM eviction. In the real world, however, servers may fail without notice.