formal methods
-
Reading Group #150. Model Checking Guided Testing for Distributed Systems.
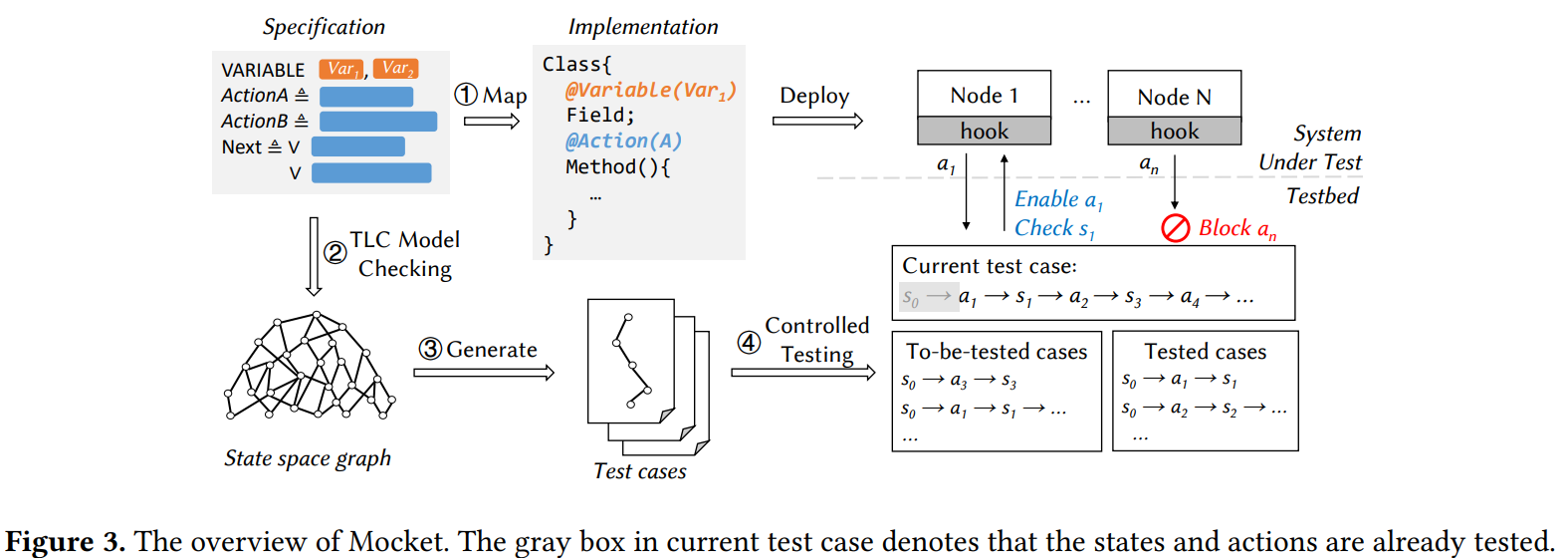
For the 150th reading group paper, we read “Model Checking Guided Testing for Distributed Systems” EuroSys’23 paper by Dong Wang, Wensheng Dou, Yu Gao, Chenao Wu, Jun Wei, and Tao Huang. We had a nice presentation of the paper, and I will be extremely short in my summary. The authors present and evaluate Mocket, a…
-
Reading Group. Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amazon S3
For the 90th reading group paper, we did “Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amazon S3” by James Bornholt, Rajeev Joshi, Vytautas Astrauskas, Brendan Cully, Bernhard Kragl, Seth Markle, Kyle Sauri, Drew Schleit, Grant Slatton, Serdar Tasiran, Jacob Van Geffen, Andrew Warfield. As usual, we have a video: Andrey Satarin…
-
Reading Group. DistAI: Data-Driven Automated Invariant Learning for Distributed Protocols
In the 71st DistSys reading group meeting, we have discussed “DistAI: Data-Driven Automated Invariant Learning for Distributed Protocols” OSDI’21 paper. Despite the misleading title, this paper has nothing to do with AI or Machine Learning. Instead, it focuses on the automated search for invariants in distributed algorithms. I will be brief and a bit hand-wavy…
-
Reading Group. Compositional Programming and Testing of Dynamic Distributed Systems
We have resumed the reading group after one week of Thanksgiving break. On Wednesday, we have discussed “Compositional Programming and Testing of DynamicDistributed Systems.” This paper is on the edge between programming languages, distributed systems, and some formal methods/verification. The premise of the paper is to decompose large monolithic distributed programs into smaller pieces and…
Search
Recent Posts
- Spring 2024 Reading Group Papers (##161-170)
- Reading Group #153. Deep Note: Can Acoustic Interference Damage the Availability of Hard Disk Storage in Underwater Data Centers?
- Reading Group #152. Blueprint: A Toolchain for Highly-Reconfigurable Microservice Applications
- Reading Group 151. Towards Modern Development of Cloud ApplicationsReading Group 151.
- Reading Group #150. Model Checking Guided Testing for Distributed Systems.
Categories
- One Page Summary (10)
- Other Thoughts (10)
- Paper Review and Summary (14)
- Playing Around (14)
- Reading Group (96)
- RG Special Session (4)
- Teaching (1)