In the 88th DistSys meeting, we discussed the “EPaxos Revisited” NSDI’21 paper by Sarah Tollman, Seo Jin Park, and John Ousterhout. We had an improvised presentation, as I had to step in and talk about the paper on short notice without much preparation.
EPaxos Background
Today’s paper re-evaluates one very popular in academia state machine replication (SMR) protocol — EPaxos. EPaxos solves a generalized consensus problem and avoids ordering all state machine operations. Instead of a single total order of everything, EPaxos relies on a partial order of dependent operations. For instance, if two commands are updating the same object, then these commands may depend on each other and must be ordered with respect to each other. These dependant operations can happen concurrently, in which case they are conflicting. Not all operations depend on each other or have conflicts. For instance, if operations are commutative, and let’s say, work on different objects, requiring an order between them is overkill. Avoiding ordering operations that do not care about the order can enable some parallelism.
In practice, things are a bit more complicated. The first problem is figuring out if operations depend on each other and conflict. Of course, one can funnel all commands/operations through a single node, like Raft or Multi-Paxos, and have that node figure out which operations conflict and which do not. However, our goal was to improve parallelism, and with a single node to handle all commands, we are not achieving it, at least not on the scale possible in distributed systems. So, we need different nodes to start operations independently and learn if these operations may conflict with each other. EPaxos does this with its leaderless approach.
Every node in EPaxos can receive a request from a client and replicate it in the cluster, learning of dependencies and possible conflicts in the process. We can call the node driving replication of a command a coordinator. If a quorum of nodes agrees on dependencies for the command, the protocol commits in one round trip. Such single RTT replication is called a fast path, and in EPaxos it requires a fast quorum that can be bigger than the traditional majority quorum in some deployments. However, if nodes disagree about dependencies, there is a conflict, and the protocol may take a slow path. Slow path essentially uses Paxos to replicate and commit the operation with a “merged” list of conflicting dependencies to other nodes. It ensures that conflicts that may have been observed by only a minority of nodes are recorded by a quorum for fault tolerance.
Let’s look at this a bit deeper. The two commands ‘C1’ and ‘C2’ conflict when some nodes have received them in a different order. As such, one node may say ‘C1’ comes before ‘C2,’ and the other node orders ‘C2’ before ‘C1.’ As such, we express conflicts by a mismatch of dependencies at different nodes. In this example, the mismatch is ‘C1’ depends on ‘C2’ vs. ‘C2’ depends on ‘C1.’ EPaxos needs to ensure that enough nodes know about all the dependencies happening, so a slow path is taken to commit the command with all the learned dependencies. It is important to understand that not all dependencies are conflicts. For example, if operation ‘C4’ happened so much after operation ‘C3,’ that all (or really a quorum of nodes) nodes see that ‘C3’ happened before ‘C4’ in their dependencies, then this is not a conflict, and we can proceed with the fast path.
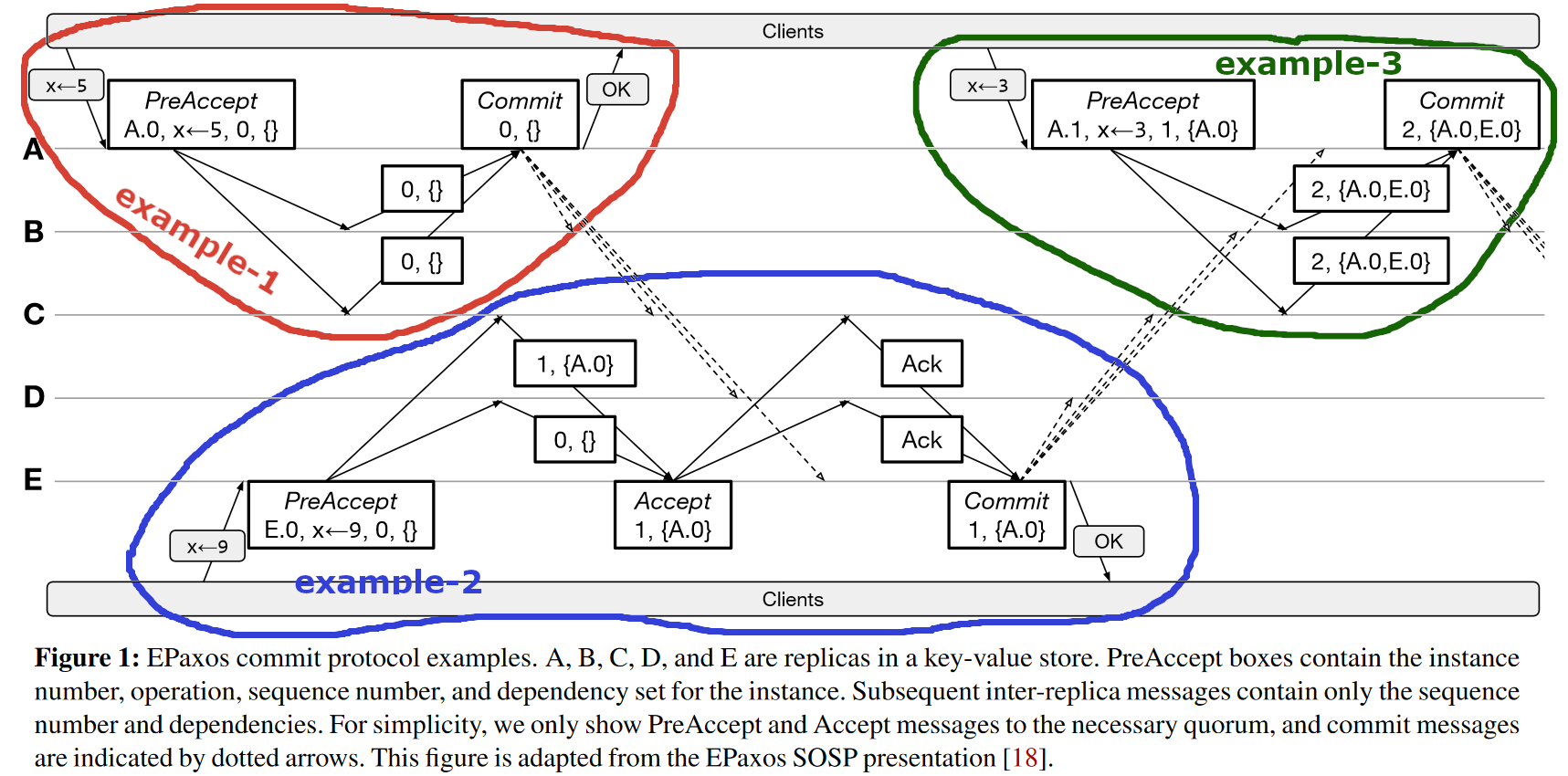
Now let’s take a look at a few examples. The figure above, which I borrowed from the revised paper, has three distinct operation examples. In example-1, node ‘A’ is the coordinator for ‘x=5’ operation, and it knows of no dependencies for the object. It reaches out to a quorum, and the followers also know of no dependencies. Coordinator ‘A’ concludes the operation in the fast path. The same would have happened if the dependencies known to ‘A’ matched the followers — since this is a no-conflict situation, ‘A’ can commit in the fast path. In example-2, node ‘E’ knows of no dependencies for ‘x=9’ command, but one node in the quorum has recorded a dependency in the form of other operation on object ‘x’. This dependency mismatch between replicas is a conflict, and ‘E’ takes the slow path to record the combined observation. Note that initially, only replicas ‘A-C’ had the dependency, but after the Accept message by ‘E’, both ‘D’ and ‘E’ also have it. Performing the slow path ensures that at least a quorum of nodes knows the dependency. Finally, example-3 has node ‘A’ as the coordinator again. It knows a previous command as a dependency, but the followers know more additional dependencies. Even though there seems to be a conflict, all the followers agree on dependencies. In this case, the protocol can proceed in the fast path in some cases. The exact conditions that determine whether node ‘A’ can take that fast path depend on how ‘A’ communicates with the rest of the replicas. I will discuss this later.
There are a few caveats to the process. First of all, when the coordinator learns of dependencies, it must learn the whole chain of dependencies to make sure the new command is properly ordered and executed at the proper time. So, over time the dependency lists get larger and larger. At some point, it will make no sense to remember old commands that were executed a long time ago on all nodes as conflicts, so the conflict and dependency tracking system must have a way to prune the no longer needed stuff. Another issue is the need to wait for all dependencies to execute before executing the new operation. As a result, the acts of committing an operation and applying it to the state machine can be quite far apart in time.
One detail missing in my simplified explanation so far is the need to construct dependency graphs for the execution of operations. See, the fast path and slow path modes are all about committing the operations and their dependencies. We have not really ordered the operations yet, and the dependency graph will help us establish the actual execution order. Each operation is a vertex in a graph, and dependencies between operations are the edges. So to execute an operation, we first add it to the graph. Then we add the dependent operations and connect the operations and their dependents. Then for each new vertex, we also look at its dependents and add them. The process continues until there is nothing more to add to the graph. In the resultant dependency graph, concurrent operations may appear to depend on each other, creating loops or cycles. The execution order is then determined by finding all strongly connected components (SCCs), which represent individual operations, conflict loops, or even groups of loops, sorting these SCCs in inverse topological order, and executing SCCs in that order. When executing each strongly connected component, we deterministically establish an operation order for commands in the SCC based on a sequence number and execute all non-executed operations in the increasing sequence number. A sequence number is maintained to break ties and order operations in the same SCC. The paper has more details about the sequence number. As you can imagine, dealing with the graph is quite expensive, so it is even more important to prune all old dependencies out.
Finally, one of the biggest caveats to this fast path leaderless process is typical in distributed systems. Of course, I am talking about handling failures. In particular, the protocol needs to ensure that failures do not erase the fast-path decision. It is tricky due to concurrency, as two or more coordinators may run conflicting operations. Having such concurrency is like attempting to place two different commands in the same execution slot or position. If we use a majority decision to see which command was successful in that particular position, then we risk creating an ambiguous situation even when just one node fails. For instance, if a command ‘C1’ has three votes, and ‘C2’ has two in a cluster of five nodes, then a failure of one ‘C1’ vote creates ambiguity, as both ‘C1’ and ‘C2’ have the same number of remaining nodes. Fast Paxos paper describes the problem well, and the solution is to use a bigger fast quorum to avoid such ambiguity.
A larger fast path quorum is the case in EPaxos protocol. However, the original paper proposes some optimizations to allow a majority fast quorum in configurations of three and five nodes (technically, it is an \(f+\lfloor\frac{f+1}{2}\rfloor\) fast quorum). Of course, these optimizations do not come entirely for free, as the need to solve the ambiguity problem remains. The optimized recovery needs only \(\lfloor\frac{f+1}{2}\rfloor\) responses and some additional information about the dependencies available at the nodes. The whole set of optimizations is hard to summarize, so I refer interested readers to the paper, Section 4.4.
Now let me return to the example-3 fast path again. Previously I said that the quorum needs to agree on dependencies, but also showed example-3. In that example, the coordinator disagrees with followers. However, the coordinator still takes a fast path as long as all the followers in the quorum agree. Unfortunately, this is not the case in optimized EPaxos, at least not always. In fact, the paper says that the followers must have the same dependencies as the coordinator for the fast path if the coordinator communicates with all nodes and not just an exact quorum of nodes. Moreover, the followers must record having matching dependencies with the coordinator. So, example-3 works when the coordinator only contacts enough nodes to form a quorum. Intuitively, succeeding in this configuration means that not only enough nodes matched the dependencies, but all other nodes do not even learn about the operation from the coordinator. Upon recovery, this restricted communication gives additional information, as the recovery protocol can know what nodes were part of the initial fast quorum. In practice, however, this creates problems, as it is harder to get a fast quorum to agree, as the coordinator needs to be lucky to pick exact nodes that agree on the dependencies. Moreover, just one node failure results in failed fast quorum and forces retry, further contributing to tail latency.
As such, practical implementations broadcast messages to all nodes and expect the fastest to reply to form the quorum. In the broadcast-to-all communication, example-3 in the figure will not work.
EPaxos Revisited
The revisited paper brings a few important contributions to EPaxos. First, it conducts a re-evaluation of the protocol and makes an excellent comparison to the Multi-Paxos baseline. I really like the re-evaluation part of this paper!
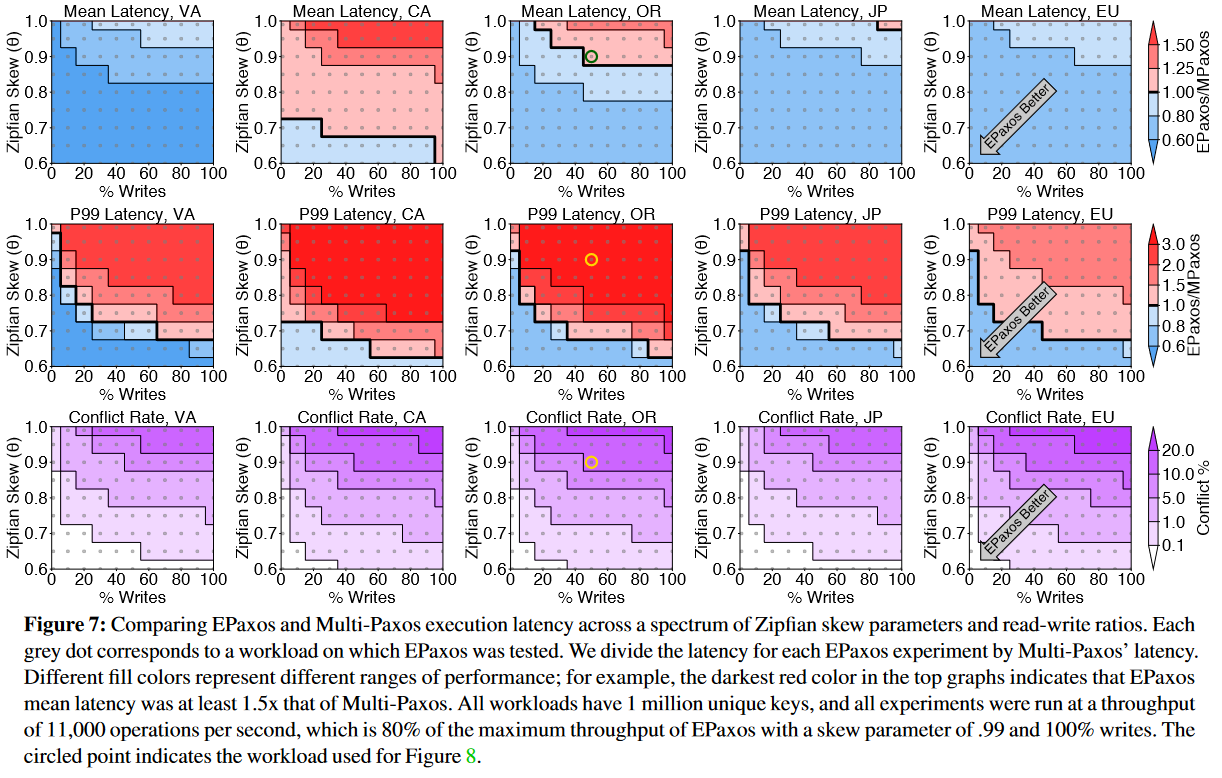
Unlike the original EPaxos paper, the revisited paper reports performance for a much bigger range of possible conflicts. The paper uses a more realistic read/write workload with different read-to-write ratios. The authors also change the conflict workload to a more realistic scenario. In this original paper, conflicts were simulated by having concurrent commands access the same predefined key — a “hot spot” method. The revisited paper no longer focuses on just one key and, instead, simulates conflicts by using Zipfian distribution to select keys. Finally, the reporting of results is way more visual. The figures capture the performance differences between EPaxos and MultiPaxos in every region and tested scenario. I was surprised to see very bad EPaxos tail-latency, even given the expectations of it having more performance variability. Below is the evaluation figure for latency in a five regions deployment. It may appear confusing at first, but just reading the caption and staring at it for a minute was all I needed to understand it.
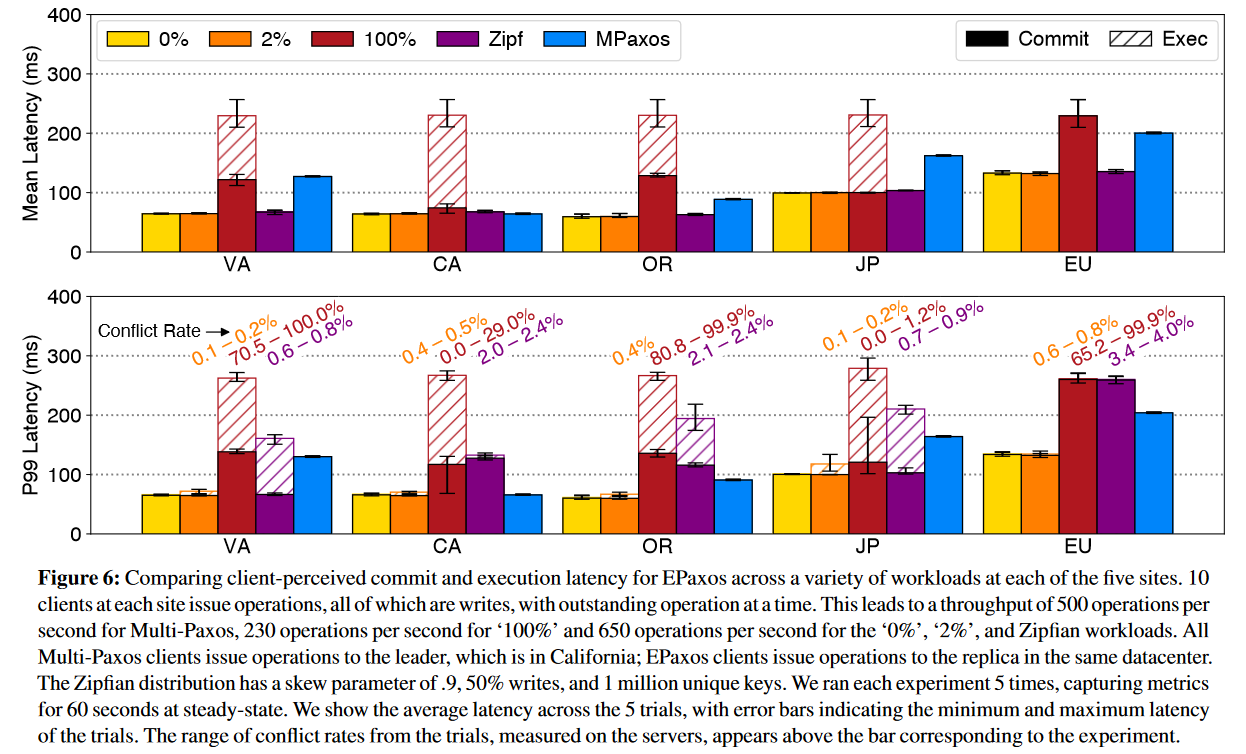
Another important part of re-evaluation is addressing the commit vs. execute latency problem. As mentioned in the summary above, execution can delay significantly after the commitment. Yet, the original EPaxos measured only commit latency. The figure below shows the difference.
The second contribution is a bit shaky. EPaxos performance degrades as the conflict rate rises. Naturally, finding a way to reduce conflicts can help avoid the expensive slow-path, which, in turn, will improve both latency and throughput. The paper proposes a technique they call Timestamped-Ordered Queuing (TOQ) to reduce conflicts. Recall that the EPaxos coordinator sends its dependencies to the followers, and the followers reply with their updated dependencies. Whether the algorithm takes a fast path depends on a few conditions. The basic rule is that all followers in the quorum must have the same dependencies. TOQ exploits this and adds some delays at each follower to increase the chance of followers having the same conflicts/dependencies. For concurrent conflicting operations, quorum replicas may receive these operations in a different order. These out-of-order messages require a slow path to resolve. But if followers wait a bit to receive these concurrent messages and order them deterministically, then we can have the same dependencies/conflicts at follower replicas in the quorum.
This waiting does not fix the conflicts coordinator communicated with the followers. And this is where my problem with the revisited paper lies. The TOQ optimization relies on the coordinator’s ability to communicate a different list of dependencies than the followers and proceed with the fast path, as in example-3. However, this only happens when we use unoptimized EPaxos with a larger fast quorum or make the coordinator use “thrifty” mode by contacting only a quorum of nodes instead of all nodes. In both cases, we lose something — larger quorums increase latency and decrease the number of failures a system can sustain before it is required to take a slow path all the time. And thrifty optimization can increase tail latency substantially, as a single failed node may prevent the coordinator from having the quorum of votes, requiring a timeout and retry. Considering that delaying the followers’ reply already adds extra latency, the TOQ optimization becomes a bit questionable in practice.
The paper studies the added effect of delaying the followers on latency and proposes some compromise solutions to reduce the delay at the expense of having some conflicts. On the evaluation side, the paper says it has not enabled thrifty optimization, so for TOQ to be correct, it must have used a larger fast quorum. However, the paper does not mention this, so it is impossible to know whether the authors performed the TOQ evaluation on the correct system configuration.
Discussion.
1) Correctness. In my presentation, I focused a lot on the correctness of example-3, where the coordinator communicates a different dependency list than the followers have in an optimized EPaxos fast quorum. I said that this is incorrect, according to the original paper. The lack of preparation for the meeting showed — I was wrong.
The correctness, in this case, is not necessarily violated, but this largely depends on the “version” and configuration of EPaxos. According to the paper, a thrifty mode, where the coordinator only contacts the required number of nodes to reach quorum, will work as described in the figure, so there are no safety issues. However, without the thrifty mode, the safety breaks. It breaks because we are running a smaller fast quorum (optimized EPaxos) but do not record enough information to solve the ambiguity over taken fast-path that may arise with failures. The non-thrifty, optimized EPaxos is the configuration when we need followers to agree with the dependencies of the coordinator and record this. In the discussion, we looked at some examples of safety violations due to this problem.
Interestingly enough, I am not sure that the authors of the revised paper fully understood the implications of thrifty/non-thrifty and other optimizations on safety. In the EPaxos overview figure, the paper explicitly states: “for simplicity, we only show messages to the necessary quorum,” suggesting that the authors do not assume thrifty mode here, making example-3 incorrect.
So, where did this example come from? The authors borrow a figure from the original EPaxos presentation. In that presentation, Iulian Morau explicitly stated that the coordinator talks to the majority of replicas only (3 out of 5).
2) TOQ Benefits. In the light of the above, TOQ benefits become a bit more questionable because we are not sure whether the experiments ran on the correct and safe configuration of EPaxos. At the same time, it is worth mentioning that the Tempo paper, which we will discuss later this year, uses a similar approach to TOQ. We also discussed the Accord protocol with a similar technique, so the TOQ is not entirely without benefits and seems appreciated in other literature.
3) Bounding Dependency Chains. This is an important improvement to EPaxos introduced in this paper. It prevents dependency chains from growing indefinitely under certain conditions. Such uncontrolled growth can prevent execution, stalling the protocol. We have spent quite a bit of time trying to figure out exactly how the proposed solution works. We think the paper could have improved here a bit more on the clarity.
4) Appendix. The appendix has lots of additional performance data that is worth checking.
Reading Group
Our reading group takes place over Zoom every Wednesday at 2:00 pm EST. We have a slack group where we post papers, hold discussions, and most importantly manage Zoom invites to paper discussions. Please join the slack group to get involved!