In the 99th reading group meeting, we discussed stream processing. The paper we read, “Darwin: Scale-In Stream Processing” by Lawrence Benson and Tilmann Rabl, argues that many stream processing systems are relatively inefficient in utilizing the hardware. These inefficiencies stem from the need to ingest large volumes of data to the requirement of durably storing ingested data for fault tolerance to the generality of the stream-processing frameworks themselves. Due to these inefficiencies, many stream processing systems scale by adding more machines instead of solving the existing bottlenecks. The authors propose a set of methods to address the scalability concerns. The paper refers to these fixes as a “scale-in” approach, where the system tries to optimize and fully use the resource it already has before requiring more servers.
Overall, the paper identifies several areas of concern and improvement. On the framework generality side of things, the authors discuss query compilation. The idea here is that compiling streaming queries into native, optimized code will be faster and more efficient than having these queries run in a more general but interpreted environment. Out of all identified problems, Darwin seems to only solve this one. Darwin exposes an SQL-like interface to users, creates a query plan that incorporates various optimizations, translates the query plan into C++ code, and finally compiles C++.
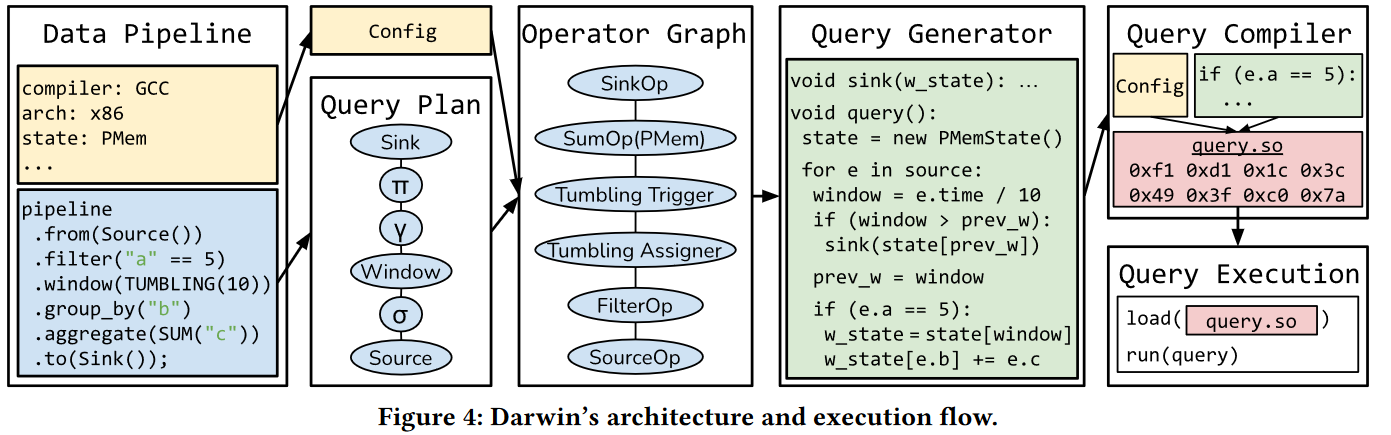
Other bottlenecks/issues the paper identifies are network communication, persistent storage, and recovery. For network communication bottlenecks, the authors propose using… well faster networks and RDMA. On the persistent storage side of things, the paper claims we need more speed and should consider newer technologies, like nonvolatile memory (PMem). Finally, for the recovery aspect, the paper is again not very creative and suggests using “modern storage technology to achieve efficient checkpointing.”
Discussion
1) Limited Implementation & Eval. This is a short paper, so there are only so many details on many of the discussed topics. The paper identifies 4 bottlenecks and provides experimental justifications for these. However, on 3 out of the 4 issues, the solution seems to boil down to “using modern technology.” So, it seems like either 3/4 of the problems have been solved with “modern technology” or that the authors have no good solution to them.
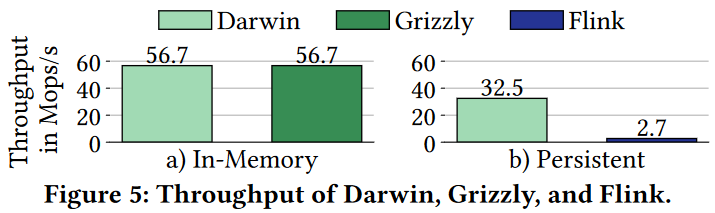
The limited evaluation is also interesting. After all, in RAM, Darwin shows the same performance as the other systems the authors compare against. This makes us question whether the remaining 1 problem and solution (query optimization) is also actually a problem in (at least some) other streaming systems.
2) Few Interesting Numbers. We really liked the motivation for scaling streaming systems the paper uses — Alibaba’s 2020 Singles Day (a big e-commerce sales event) produces 4 billion streamed events per second are required 1.5 million cores of Apache Flink to handle. At such a scale, improving the efficiency of streaming systems is very crucial.
Reading Group
Our reading group takes place over Zoom every Wednesday at 2:00 pm EST. We have a slack group where we post papers, hold discussions, and most importantly manage Zoom invites to paper discussions. Please join the slack group to get involved!